這篇是 30 天系列的補完。系列文在第 10 天之後就沒有可執行的實作、第 30 天也坦承「斷賽」與硬體限制。這裡用一套能在 RTX 4060(8GB VRAM)本機完整跑完的方案重建文字版 EmoRAG,並且把數字老實攤開——包含做得好的、和還做不到的。
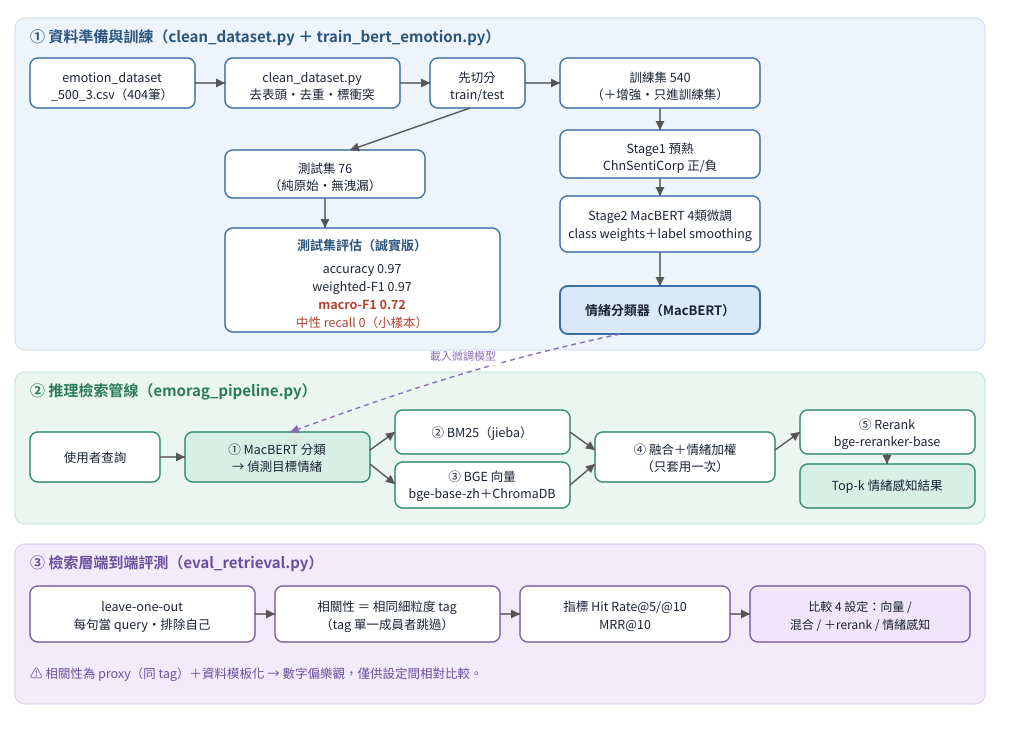
三段式流程:① 訓練(先切分再增強的誠實流程、兩階段微調)→ ② 推理檢索管線(分類偵測情緒 → BM25+BGE 融合 → 情緒加權 → rerank)→ ③ 檢索層評測(Hit Rate / MRR)。
all-MiniLM-L6-v2 處理中文效果差。 它是英文為主的輕量模型,第 30 天就是卡在這裡。cross-encoder/ms-marco-MiniLM-L-6-v2 這個 reranker 不支援中文(第 11 天自己也指出了),用在中文檢索會越排越差。Qwen3-Embedding-0.6B 記憶體跑不動,所以微調的念頭無疾而終。這篇的目標不是「衝出漂亮數字」,而是把流程接成一條可重現、且誠實標示能力邊界的線。
hfl/chinese-macbert-base(102M 參數,fp16 微調尖峰約 5GB,4060 跑得動),四類分類:積極/消極/中性/期待。使用者查詢
├─① MacBERT 分類 → 偵測目標情緒
├─② BM25 關鍵字檢索(jieba 分詞)
├─③ BGE 向量檢索(BAAI/bge-base-zh-v1.5 + ChromaDB, cosine)
├─④ 分數融合 + 情緒加權(emotion_boost,已修正為只套用一次)
└─⑤ Rerank(BAAI/bge-reranker-base,中文原生,取代不支援中文的 ms-marco-MiniLM)
向量檢索在查詢端加上 BGE 建議的 instruction 前綴;reranker 輸出過 sigmoid 正規化到 [0,1] 以利跨查詢比較。情緒加權原本在 BM25/向量/rerank 三個階段各乘一次(等於加權三次),已改為只在最終分數套用一次。
原始 380 筆(積極 186/消極 140/中性 13/期待 41),增強 +236 筆(補中性、期待),切成訓練 540 筆/測試 76 筆(純原始)。5 epochs + early stopping,CPU 實測 train_runtime ≈ 147 秒(約 2.5 分鐘;4060 GPU 會更快,另加 Stage1 預熱約 5–8 分鐘)。
| 類別 | precision | recall | f1-score | support |
|---|---|---|---|---|
| 積極 | 1.00 | 0.97 | 0.99 | 40 |
| 消極 | 0.97 | 1.00 | 0.98 | 30 |
| 中性 | 0.00 | 0.00 | 0.00 | 1 |
| 期待 | 0.83 | 1.00 | 0.91 | 5 |
| accuracy | 0.97 | 76 | ||
| macro avg | 0.70 | 0.74 | 0.72 | 76 |
| weighted avg | 0.96 | 0.97 | 0.97 | 76 |
混淆矩陣:積極 39 對、1 筆被判成期待;消極 30 筆全對;中性唯一 1 筆被判成消極;期待 5 筆全對。
這份報表想講的重點不是 0.97,而是 0.72。 weighted-F1 0.97 看起來漂亮,是因為積極+消極佔了 70 筆;但 macro-F1 只有 0.72,而且中性類 recall = 0——測試集裡中性只有 1 筆,模型根本沒機會、也沒能力學好它。
換另一次(CPU、沒跑 Stage1 預熱)的結果是 accuracy 0.92/macro-F1 0.67,中性類(那次 support=3)一樣 recall = 0。兩次跑下來的共同結論很一致:
強勢類別(積極/消極)很穩,弱勢類別(中性/期待)受小樣本主宰、會隨切分抖動,中性幾乎必掛。這是資料規模問題,不是調個超參數就能補的。
系列文第 6 天那句被判成「正面」的句子,在新分類器上:
| 輸入 | 預測 | 信心度 |
|---|---|---|
| 生成的程式碼一直報錯我好煩躁喔 | 消極 | 0.839 ✅(第 6 天原誤判為正面) |
| 這個產品真的很棒,我非常滿意 | 積極 | 0.796 |
| 服務態度太差了,讓我很失望 | 消極 | 0.911 |
| 我渴望它能有更強的創造力 | 期待 | 0.929 |
| 我把檔案備份好之後就下班了 | 中性 | 0.924 |
| 還可以,沒什麼特別的感覺 | 消極 | 0.539 ⚠️(其實偏中性,低信心,正是中性弱項的體現) |
| 舊版(系列文) | 新版(emorag_bert) |
|---|---|
| TF-IDF + LogisticRegression(第 2 天) | BERT 端到端微調,理解語意而非詞頻 |
| 先過採樣再切分 → 0.95 虛高 | 先切分、測試集純原始 → macro-F1 0.72(誠實) |
| all-MiniLM-L6-v2(中文差) | bge-base-zh-v1.5(中文專用) |
| ms-marco-MiniLM reranker(不支援中文) | bge-reranker-base(中文原生) |
| 情緒加權重複套用(三重) | 只在最終分數加權一次 |
| Colab T4 雲端、片段程式碼 | RTX 4060 本機、完整可跑 |
emotion/tag 標籤有衝突。清理腳本見 emorag_bert/clean_dataset.py,待人工複核的衝突清單見 label_conflicts_reviewed.csv。# 1. 環境(Windows PowerShell;4060 用 CUDA 版 PyTorch)
python -m venv venv ; .\venv\Scripts\Activate.ps1
pip install torch --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
# 2.(建議)先清資料,產生 emotion_dataset_clean.csv 與 label_conflicts.csv
python clean_dataset.py
# 3. 微調情緒分類器
python train_bert_emotion.py
# 4. 跑情緒感知檢索 demo(含互動查詢)
python emorag_pipeline.py
把 0.95 換成 0.72,數字看起來退步了,但它第一次反映了模型真正的能力:強勢情緒判得準、弱勢情緒(尤其中性)因資料太少而學不起來。對一個入門學習專案來說,一個誠實、可重現、知道自己邊界在哪的 0.72,遠比一個藏著資料洩漏的 0.95 有價值——因為它清楚告訴你下一步該做什麼:補資料、清標籤,而不是繼續換模型。
數據來源:
emorag_bert/eval_report.txt(測試集報表與 demo 預測)、emorag_bert/train_log_clean.txt(訓練過程與另一次跑的對照)、emorag_bert/README.md(硬體與模型設定)。

