近日想製作用谷歌翻譯製作的小翻譯器
但卻發生了些問題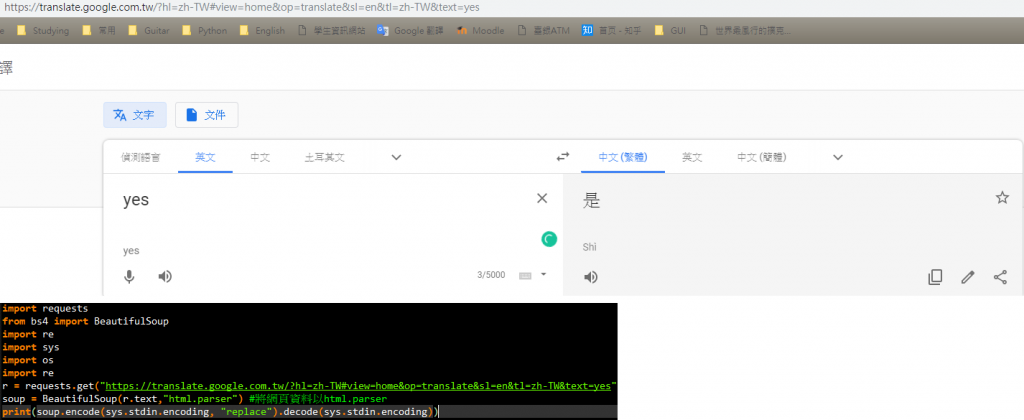 )
)
圖片中我用谷歌的翻譯器 打yes 得到了'是'的結果
但是我用程式去爬我輸入yes時的網址的時候
當我把網站抓到的全部內容print出來
其中卻沒有任何'是'的結果
想請問是哪個環節出了問題了嗎
還有如果可以得到結果的話
要如何取得結果 不太清楚dev class等的關係
可以的話希望稍微說一下要怎麼取得特定內容
都只是自學 懇求指教> <
4/13 21:30 更新:
謝謝各位幫助 大致了解 應該就是要有辦法能取得動態的變數 離我還挺遙遠
那再問個小問題 從網路上看到的
r = requests.get('https://tw.yahoo.com/')
if r.status_code == requests.codes.ok:
soup = BeautifulSoup(r.text, 'html.parser')
stories = soup.find_all('a', class_='story-title')
以下是YAHOO的部分原始碼
不知道為什麼他的程式是去搜尋
find_all('a', class_='story-title')
而不是後面的class='Va-tt'
卻可以成功輸出需要的文字:慘被掏空200億 15年內大復活
已邀請的邦友 {{ invite_list.length }}/5
