請問如何刪除之前和之後的非字母中文單字
:MySQL 資料庫同步
MySQL 資料庫同步
-首先使用諸如startwith(non-letter)之類的正則表達式獲取數據,然後使用string.Replace替換為空字符串。
-使用類似 (non-letter)endwith的正則表達式獲取數據,然後也替換為空字符串。
但我不知道如何實現..
另外想詢問大神們都是怎麼看到一堆字串,馬上想到要用甚麼正則抓取解決問題...
已邀請的邦友 {{ invite_list.length }}/5
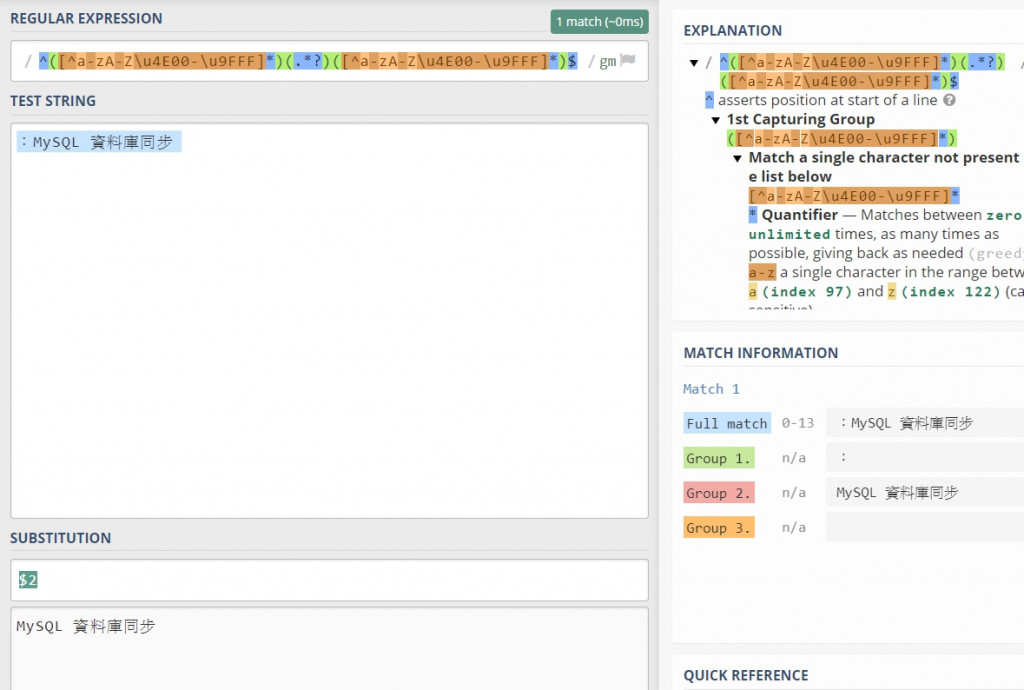
^([^a-zA-Z\u4E00-\u9FFF]*)(.*?)([^a-zA-Z\u4E00-\u9FFF]*)$
可以分為三個 Group
第一個和第三個取符號
中間取除此之外的所有字元
replace 可以用 $2 將整段匹配的文字,取代為中間的內容
var regex = /^([^a-zA-Z\u4E00-\u9FFF]*)(.*?)([^a-zA-Z\u4E00-\u9FFF]*)$/gm;
var str = ':MySQL 資料庫同步 ';
var result = str.replace(regex, '$2');
console.log(result);
發現可以使用以下方式來捉取符合起始或尾隨的非單字元: ^\W+|\W+$
^\W+: 在開始時匹配 1+ 個非單字元。|: 或。\W+$: 在結束之前符合 1+ 個非單字元。



