最近嘗試使用requests取得一些網頁資料,遇到2個問題
認證
從requests library中得知requests支援多種驗證功能,但不知如何取得網頁使用的驗證方式?
這邊用蝦皮網站做測試,發現用basic auth帳密亂打也能得到200,有點困惑
網頁內容
試著從蝦皮取得一些使用者帳戶資訊 (profile/addrss...),status code 200,但回傳的內容似乎都一樣但和網頁看到的不符,讀取shopee網頁原始碼似乎上面也沒有網頁看到的資訊,請問該如何取得資訊呢
程式碼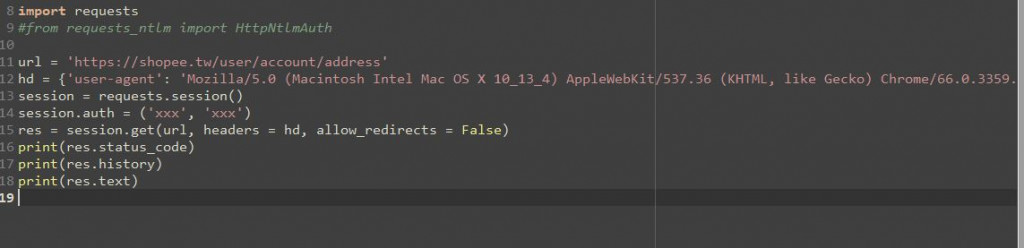
蝦皮個人資訊頁面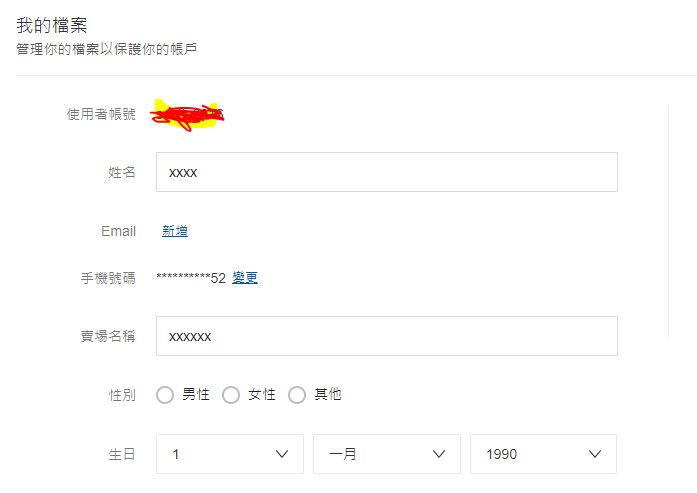
網頁原始碼
已邀請的邦友 {{ invite_list.length }}/5
basic auth帳密亂打也能得到200
首先要知道 200 代表為何 ? 只要網頁正常回應就是 200, 當然包含帳密錯誤, 登入帳密錯誤當然是 200 , 你確定是用 session auth 那麼簡單的認證? , 不是 hash md5 加 cookie 有的沒的 ?
網頁內容 ... 使用者帳戶資訊 ... 200
首先 200 表示 網頁回應正常不是已登入 ..... 使用者帳戶資訊 沒登入當然看不到 ....
有用抓網頁封包看過內容嗎? 不然就瞎子摸象 ....
抓了一下蝦皮不簡單的 ...
我習慣用 fiddler web debuggr
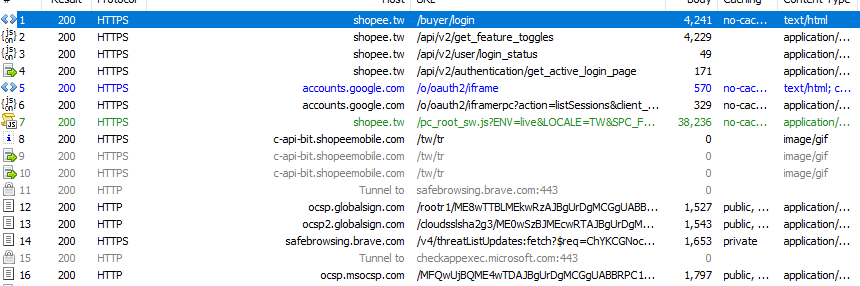
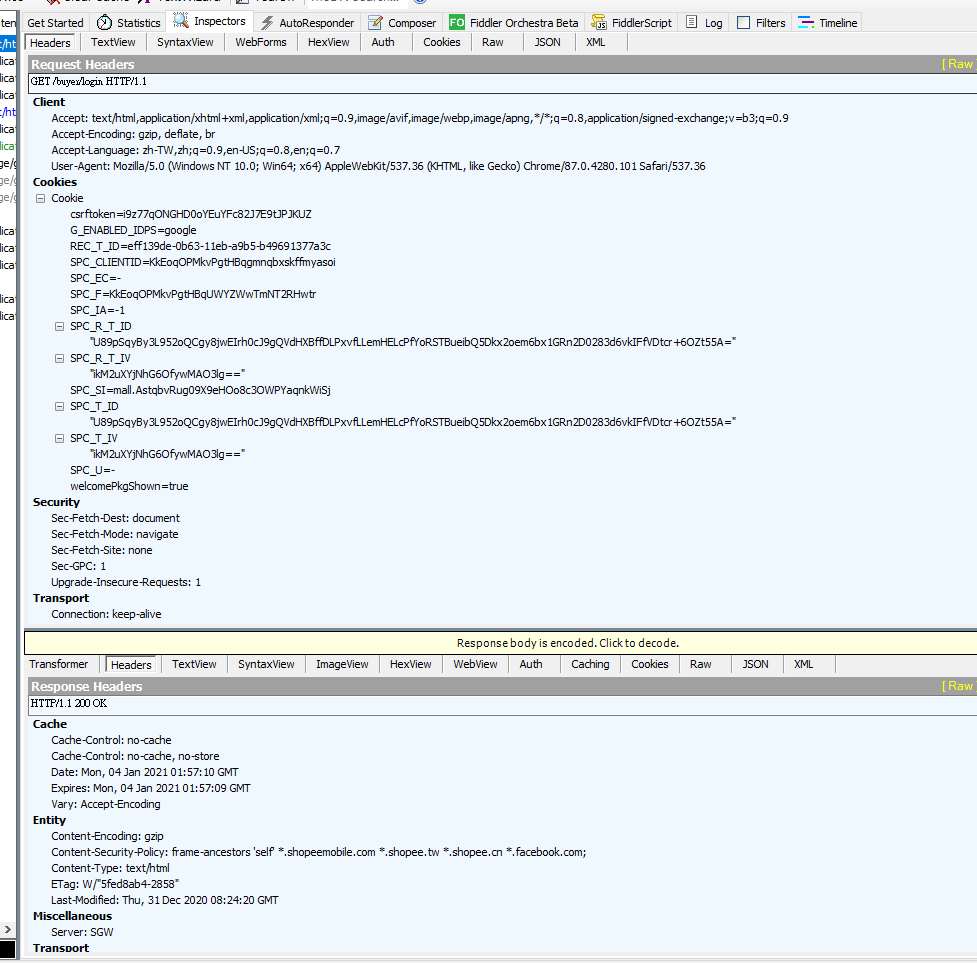
感謝回覆
我也不確定Basic Auth是否能通過蝦皮身份認證,查了一下已知的認證種類非常多,怎麼能知道要使用哪一種方式呢?想像中用瀏覽器登入的user也沒有這個資訊,應該是server透過某種方式告知user?
封包抓取之前有用過wireshark,目前先用chrome抓取瀏覽器的封包資訊來試著hack一下。不過這邊遇到的問題是我直接用瀏覽器登入看shopee的網頁原始碼裡面好像也沒有任何資訊 (例如Addr頁面會顯示之前存的地址,但是HTML中完全找不到對應的資訊),這樣就算session return content成功,好像也無法parsing出結果?
不知道是不是 用 Basic Auth 那您為何用, 這不是瞎子摸象嗎? 用那種方式傳送認証不知所以要錄網頁的傳送封包呀,抓完一步一步分析,我技術不好,有時要分析個一兩天到有一個月都可能。
chrome 抓封包要看 network 傳送的 通常是 post 傳加密過的帳密,所以要去研究其加密過程,不是看原始碼那麼簡單, 試試fiddler web debuggr 每個交談都可看到詳細內容,然後去分析到每個交談你都要知道做什麼
知名網站要能抓到認證過程相當難,蝦皮那麼大網站應該沒那麼簡單,風控相當嚴格,如再不行用 selenium 去做吧,用selenium去學習爬蟲入門比較簡單,當然很多網站都有風控無法爬,像是困難的圖形相關認證最難,遇到下列九功能格哪個是斑馬線之類的我就掛了
感謝您的回覆,看起來透過chrome不容易取得資訊模擬一般user的行為,我會嘗試使用封包抓取軟體看是否能取得更多訊息
Selenium就比較像模擬瀏覽器上的操作,我之前也使用過,如您所說,機器人認證是一個很難跨過得關卡,不過我不確定selenium取得的網頁內容是否就有包含正確的資訊,或許可以嘗試看看
如果要爬的網站是蝦皮這個需要開畫面登錄,建議用模擬瀏覽器行為的元件selenium,而不是requests
