目前在抓取頭條日報裡面完整的內容
是使用BeautifulSoup和requests來抓取
在輸出時遇到一個問題,同樣都是在某個標籤底下用<br>將文章內容作區隔
但是執行結果和其他新聞的不同
ePrice:
新聞網址: https://www.eprice.com.tw/mobile/talk/4693/5644362/1/
程式碼: https://ithelp.ithome.com.tw/questions/10203813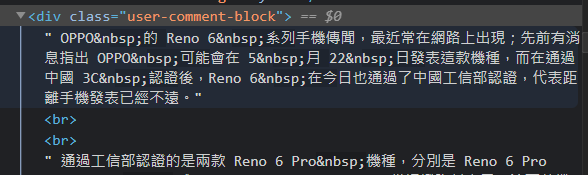
輸出結果<br>之間的文字有換兩行(兩個<br>)
頭條日報: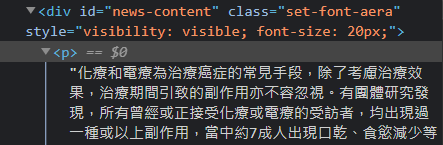
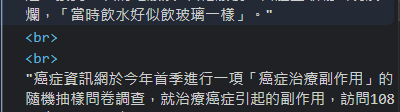
結果是連在一起,沒有換行
有人知道是什麼原因嗎? 該怎麼處理才能讓內容之間多空一行?
程式碼:
import json
from bs4 import BeautifulSoup
import requests
class crawlerClass:
def __init__(self):
print("init")
def StheadlineCrawler(self, url):
response = requests.get(url, verify=False)
soup = BeautifulSoup(response.text, "html.parser")
section = ""
for tag in soup.select('div#news-content p'):
if tag.get_text() != "":
section += tag.get_text()
section = section.strip()
section += "\n\n"
article = {'status': 0, 'content': section}
return json.dumps(article)
if __name__ == "__main__":
crawler = crawlerClass()
# ==== stheadline ====
url = "https://hd.stheadline.com/news/realtime/hk/2069820/%E5%8D%B3%E6%99%82-%E6%B8%AF%E8%81%9E-9%E6%88%90%E5%8F%97%E8%A8%AA%E7%99%8C%E6%82%A3%E8%80%85%E6%B2%BB%E7%99%82%E5%BE%8C%E6%98%93%E7%8F%BE%E5%8F%A3%E8%85%94%E5%89%AF%E4%BD%9C%E7%94%A8-%E5%8F%A3%E8%85%94%E6%BD%B0%E7%88%9B%E7%97%85%E4%BA%BA-%E9%A3%B2%E6%B0%B4%E5%A6%82%E9%A3%B2%E7%8E%BB%E7%92%83"
stheadlineJsonStr = crawler.StheadlineCrawler(url)
stheadlineContent = json.loads(stheadlineJsonStr, encoding="utf-8")
print("status:"+str(stheadlineContent['status']))
print(stheadlineContent['content'])
已邀請的邦友 {{ invite_list.length }}/5
把你的
if tag.get_text() != "":
section += tag.get_text()
section = section.strip()
section += "\n\n"
裡的第二行改一下,這樣就有斷行了
if tag.get_text() != "":
section += tag.get_text(separator="\n")
section = section.strip()
section += "\n\n"
輸出
化療和電療為治療癌症的常見手段,除了考慮治療效果,治療期間引致的副作用亦不容忽視。有團體研究發現,所有曾經或正接受化療或電療的受訪者,均出現過一
種或以上副作用,當中約7成人出現口乾、食慾減少等問題;另有逾半受訪者出現口腔疼痛。有鼻咽癌患者憶述,接受33次的電療及3次化療後,口腔至喉嚨出現潰爛
,「當時飲水好似飲玻璃一樣」。
癌症資訊網於今年首季進行一項「癌症治療副作用」的隨機抽樣問卷調查,就治療癌症引起的副作用,訪問108名癌症患者;當中69人有接受化療或電療。調查發現,96%的癌症病人在接受治療後,都會出現不同的口腔副作用。當中,近7成人曾經或正在接受化療和電療,所有人均出現過一種或以上的副作用;約7成人
出現口乾、食慾減少、味覺改變、體重下降的問題;約5成人出現口腔疼痛;約4成人感到口腔有鐵鏽味。
臨床腫瘤科專科醫生施俊健表示,化療和電療為不少癌症病人的主要治療策略,強調病人在治療期間需要有強健的體魄才能戰勝病魔,若因治療引起的口腔副作用而
未能進食或食量大減,以致身體不能獲得足夠的營養,反而會影響治療的預期效果。
他特別提到,約4成病人接受化療時會出現口腔黏膜炎,當中頭頸癌病人接受高劑量電療時,出現率更高達100%。他指,情況嚴重者會出現進食及吞咽困難,令病人
不能攝取足夠營養,導致免疫力下降或出現感染,治療有機會被迫中斷。
他建議,出現味覺改變的癌症患者可以採用有別於以往口味的香料烹調食物,或利用糖、檸檬汁和鹽平衡食物味道。同時亦可選擇一些清涼的飲品,以緩解口乾引來
的不適,但提醒病人須謹慎選擇,建議諮詢醫護人員意見。
三期鼻咽癌患者Dorothy曾是一名註冊護士,在前年5月確診鼻咽癌。她憶述,治療期間共接受過33次電療及3次化療,引致口腔喉嚨潰爛,出現吞咽困難及失去味覺
。由於有兩個月時間不能進食任何固體食物,只能依靠營養奶補充營養,熬過艱苦的治療。
Dorothy坦言,「當時飲水好似飲玻璃一樣,食物的味道完全改變了,例如蜜糖是鹹味,而鹽卻是無味道。」為緩解口腔不適,她改為食用一些較清新或冰凍的食物
。
謝謝你的回答,輸出的確有換行
但我的目標是每個段落之間能空一行
如果把那段指令改成section += tag.get_text(separator="\n\n")
多一個"\n"的話,發現有個段落間會變成空兩行
.........再加一行
section += tag.get_text(separator="\n\n")
section = re.sub(r'(\s*\n){3,}',"\n",section)
section = section.strip()
section += "\n\n"
這樣的效果好像還不錯
for tag in soup.select('div#news-content p'):
# 內容分行
contents = tag.get_text(separator="\n").splitlines()
# 跌代每一行
for line in contents:
# 各別去判斷每一行的情況
if tag.get_text() != "":
section += line
section = section.strip()
section += "\n\n"


