目前在抓取ePrice新聞裡面完整的內容
是使用BeautifulSoup和requests來抓取
在抓取時遇到一個問題,就是目標tag中,底下的內容之間是用<br>隔開的
舉例來說,新聞內容都放在<dd class="normal first-thread">底下
的<div class="user-comment-block">裡面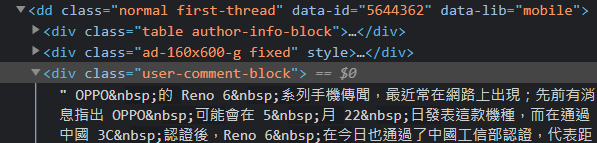
但是之間都是用<br>來做換行
因此沒辦法用排除特定標籤或文字的方法來對裡面的內容做處理
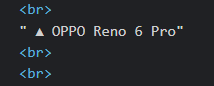
由於也會出現圖片註解或特定文字需要排除
圖片註解:
特定文字:
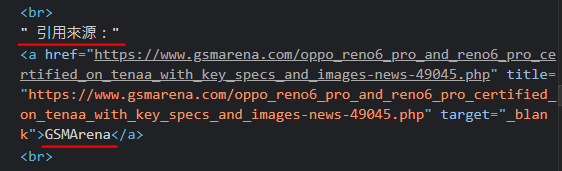
想請問有沒有方法可以將同一個標籤底下用<br>隔開
且含有特定文字(EX: ▲、引用來源)的內容排除?
程式碼:
import json
from bs4 import BeautifulSoup
import requests
class crawlerClass:
def __init__(self):
print("init")
def EpriceCrawler(self, url):
response = requests.get(url, verify=False)
soup = BeautifulSoup(response.text, "html.parser")
section = ""
for tag in soup.select('dd.normal.first-thread div.user-comment-block'):
if tag.get_text() != "":
section += tag.get_text()
section = section.strip()
section += "\n\n"
article = {'status': 0, 'content': section}
return json.dumps(article)
if __name__ == "__main__":
crawler = crawlerClass()
# ==== Eprice ====
url = "https://www.eprice.com.tw/mobile/talk/4693/5644362/1/"
epriceJsonStr = crawler.EpriceCrawler(url)
epriceContent = json.loads(epriceJsonStr, encoding="utf-8")
print("status:"+str(epriceContent['status']))
print(epriceContent['content'])
PS: 有時候執行結果會出現亂碼,可先忽略不管
已邀請的邦友 {{ invite_list.length }}/5
soup.select('dd.normal.first-thread div.user-comment-block')拿到的是整個文章了,所以你用 tag.get_text() != ""一定會True,所以要先把文章分為一行一行的,然後再去判斷
def EpriceCrawler(self, url):
...
...
section = ""
excepts = ['▲', '引用來源']
for tag in soup.select('dd.normal.first-thread div.user-comment-block'):
# 內容分行
contents = tag.get_text().splitlines()
# 跌代每一行
for line in contents:
# 各別去判斷每一行的情況
if line == "":
continue
for e in excepts:
if e in line:
break
else:
section += line
section = section.strip()
section += "\n\n"
...
...
你的想法把在成對的<br>tag內且符合某些條件的內容刪掉,這是不太合理的判斷方式,因為<br>本來就不成對,無法得知誰跟誰是一對。
照我幫你改的那一篇<BR>斷行那篇,你可以再引用re.sub做特定字串代換
import re
#................. 你的程式
section += tag.get_text(separator="\n")
section = section.strip()
section = re.sub(r"^\s*引用來源[::]*.*$","",section)
section += "\n\n"
用正則表達式做特定字串代換真的很好用
這樣就可以
section = re.sub(r"^\s*引用來源[::]*.*$","",section)
好像不行,我的輸出結果還是有出現
section += tag.get_text()
section = section.strip()
section = re.sub(r"^\s*引用來源[::]*.*$", "", section)
section += "\n\n"
使用 CSS 和偽元素 ::before 或 ::after:您可以使用 CSS 來使用偽元素 ::before 或 ::after 隱藏 標記之間的特定內容。 aa route planner
使用 CSS 和偽元素 ::before 或 ::after:您可以使用 CSS 來使用偽元素 ::before 或 ::after 隱藏 標記之間的特定內容。67 clicker
在爬蟲過程中,如果你想要在同一個標籤內排除特定文字的內容,可以使用Python的BeautifulSoup paper minecraft 來處理。
這樣的方式應該可以有效地排除含有特定文字的內容,並確保你的爬蟲能正常工作
that's not my neighbor
