目前有看過許多的k-means方法
不過大多數都是使用數據集或是只有使用2個特徵的csv
目前遇上了csv有37個特徵的問題 相望能用sklearn.cluster來做
和使用matplotlib來將結果可視化
不過一開始就卡住了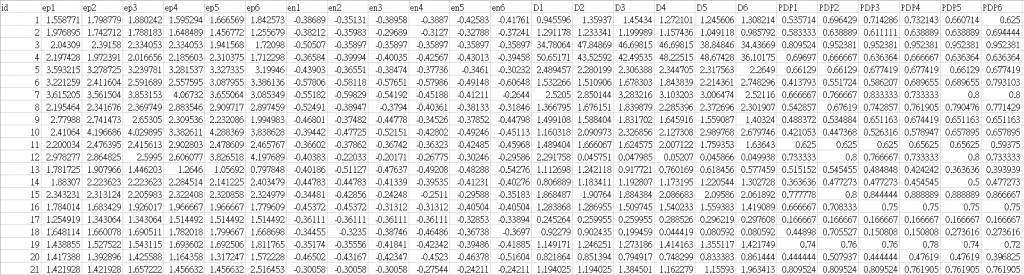
主要是想問一些觀念上的問題
1.sklearn.cluster來做K-Means是不是主要都是在處理二維的資料
2.三維以上的資料是不是需要先經過PCA降維後再進行處理
3.二維跟多維的複雜度?像我提供的例子有21間公司每間公司有37個特徵
已邀請的邦友 {{ invite_list.length }}/5
降維是重點,這樣子才能真的找出有意義的分群結果、達到資料探勘的目的。
從你的表單把比較重要的欄位挑出來,再去做分群,或許就能找到關聯性。
建議如下:
1.sklearn.cluster來做K-Means是不是主要都是在處理二維的資料
==> K-Means不限二維,再多維均可,只是計算較久。
2.三維以上的資料是不是需要先經過PCA降維後再進行處理
==> 不需要,通常是要作圖展示,才降為2或3維。
3.二維跟多維的複雜度?像我提供的例子有21間公司每間公司有37個特徵
==> 21筆/37個特徵,資料筆數太少,特徵過多(37度空間),會造成維度災難,所以,應進行特徵工程(特徵轉換、降維),才進行集群。
