各位前輩好,我是最近在學習Python的新手,若有敘述不完全的部分敬請告知
我現在在分析一個大型的檔案,使用python3,我想擷取的部分大概是這樣
ORIGIN
1 data data data data data.........
61 data data data data data........
121 data data data data data.....
//
irrelative irrelative irrelative irrelative irrelative irrelative
irrelative irrelative irrelative irrelative irrelative irrelative
ORIGIN
1 data data data data data.........
61 data data data data data........
121 data data data data data.....
181 data data data data data ......
//
簡單來說 我想擷取的部分是被'ORIGIN'與'//'給框住的部分 並且分段 每組data的長度不一 有40行的資料也有超過300行的 然後有多段資料
目前嘗試過https://ithelp.ithome.com.tw/questions/10202583
當中JaphenChen大大的方法 但只能順利print第一筆資料
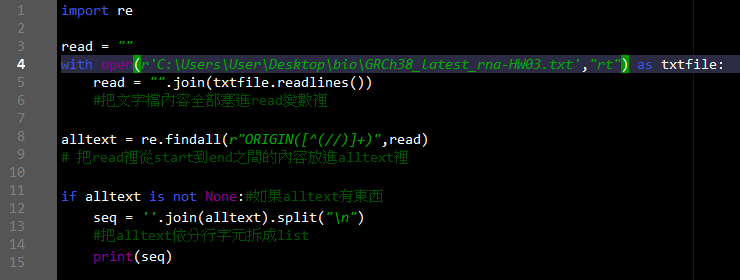
於是改用findall 再用join去拆解list 結果Spyder炸了 所以也不太確定結果究竟如何
麻煩各位大大協助指教
已邀請的邦友 {{ invite_list.length }}/5
with open("./ORIGIN.txt", "r") as f:
lines = f.readlines()
indexs = []
result = []
for index, line in enumerate(lines):
if line.startswith(r"//"):
indexs.append(index)
pairedIndexs = zip(indexs[0::2],indexs[1::2])
for startIndex, endIndex in pairedIndexs:
result.append(lines[startIndex: endIndex+1])
print(result)

 iThome鐵人賽
iThome鐵人賽