各位大神好,最近在跑python爬蟲時遇到了小問題...
我目前想要做的是利用google新聞抓取關鍵字的文章
先附上完整程式碼!
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
import requests
import re
root="http://www,google.com/"
link="https://www.google.com/search?q=%22%E7%AC%AC%E4%B8%80%E9%8A%80%E8%A1%8C%22+%22%E4%BA%BA%E5%B7%A5%E6%99%BA%E6%85%A7%22&rlz=1C1ONGR_zh-TWTW1005TW1005&tbm=nws&sxsrf=ALiCzsaa2NjFEfMPoCbW-iEcf93a2YMwrg:1664123062079&ei=toAwY_m5BMOUr7wPt-CQ0Ac&start=0&sa=N&ved=2ahUKEwj57Oi_rbD6AhVDyosBHTcwBHo4HhDy0wN6BAgBED8&biw=1536&bih=722&dpr=1.25"
next=soup.find('a',attrs={'aria-label':'下一頁'})
print(next['href'])
next=next['href']
link=root+next
print(link)
主要的問題是在最後要跳轉下一頁時 發現顯示錯誤
在debug時先試著將網址輸出看是否有誤
能夠發現在輸出蘭顯示的是沒有錯的
但是把網址點下去的時候卻無法跳轉...
後來才發現點下去後的網址改變了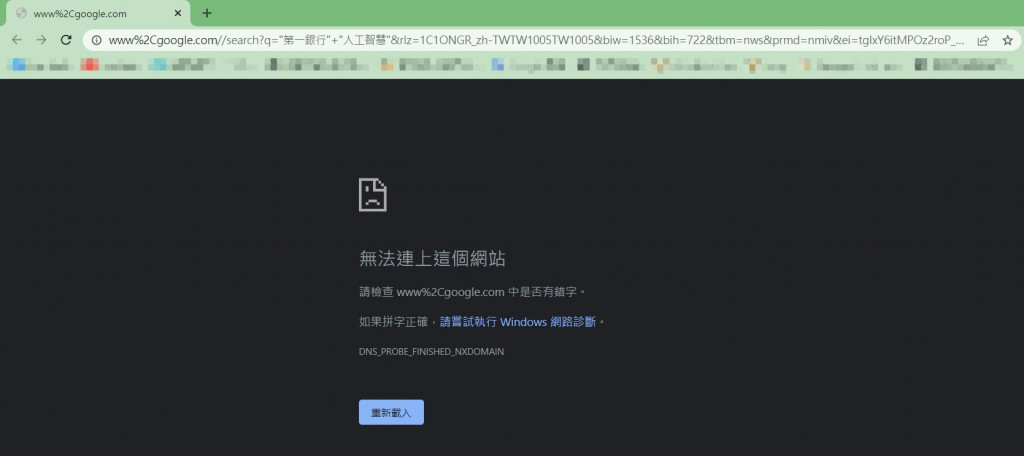

原本的.跳轉後變成%2C
有大神可以解釋一下為什麼會變成這樣嗎?
或是應該要怎麼改才能正確顯示呢?
感謝大家的幫忙!!!!!!
已邀請的邦友 {{ invite_list.length }}/5
程式碼中
root="http://www,google.com/"
這個寫錯了
倒數第二行中有
link=root+next
造成網址輸入錯誤
你打 http://www,google.com/ 幹嘛用逗號 (,)?
