各位版上前輩們好,近期操作到txt文字檔案碰到難題!
手邊有多份txt檔案如下顯示,我需要抓取每一份txt檔內
從Flow-Volume-Curve後面的每一行內容,並且在excel排列呈現~
如sr eff後面的0.96 1.13 118 0.15 89 -25
由於欄位不對稱(有些項目有空白會被拆分開),無法直接用資料剖析....
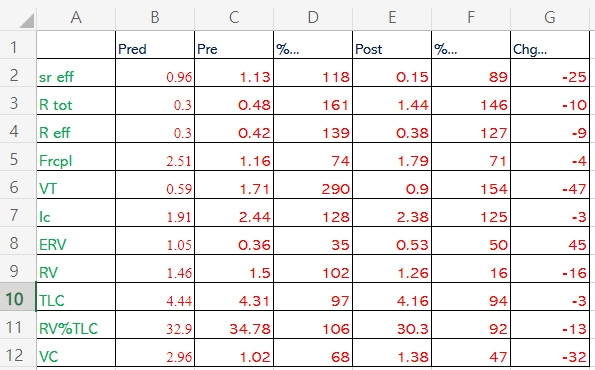
最終要輸出成excel檔案,如最底下的圖呈現
不清楚有那些方向和語法可以嘗試,希望能有前輩指點,謝謝
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
人 4 6 8 “Post
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
####Flow-Volume-Curve####
Pred Pre %... Post %... Chg...
sr eff 0.96 1.13 118 0.15 89 -25
R tot 0.30 0.48 161 1.44 146 -10
R eff 0.30 0.42 139 0.38 127 -9
Frcpl 2.51 1.16 74 1.79 71 -4
VT 0.59 1.71 290 0.90 154 -47
Ic 1.91 2.44 128 2.38 125 -3
ERV 1.05 0.36 35 0.53 50 45
RV 1.46 1.50 102 1.26 16 -16
TLC 4.44 4.31 97 4.16 94 -3
RV%TLC 32.90 34.78 106 30.30 92 -13
VC IN 2.96 1.02 68 1.38 47 -32
FVC 2.91 2.81 96 2.90 100 3
FEV 1 2.10 2.29 92 2.38 95 4
FEV1%F 81.65 82.08 1
PEF 6.18 6.64 107 5.43 88 -18
MEF 75 5.57 5.79 104 4.98 89 -14
MEF 50 3.93 2.68 68 3.10 79 16
MEF 25 1.71 0.88 52 1.03 60 17
MMEF 3.46 2.24 65 2.50 72 11
FIF 50 4.18 3.94 -6
Substance ventolin
#更新:
這邊是空白 Pred Pre %... Post %... Chg... ←此為行
sr eff
R tot
R eff
Frcpl
VT
Ic
ERV
RV
TLC
RV%TLC
VC
↑
此
為
列
因為txt檔的欄位不對稱(有些項目有空白會被拆分開,如sr off),
移植到excel無法用資料剖析處理,希望能用程式碼調整後匯出成excel
此外如第一個文字檔內容,在需要的資料之上還會有不需要的資訊,
擷取資料時需要跳過,自己有嘗試過正規表示式,奈何實力不足無法成功。
希望能將txt檔案匯出如上的型式,還是努力中..
我自己目前的輸出如下...行與列的1~6不能對其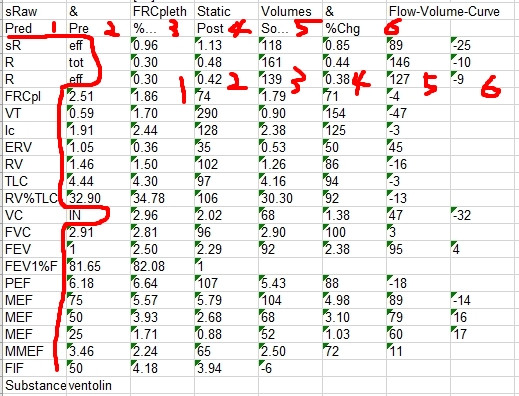
已邀請的邦友 {{ invite_list.length }}/5
基於您的問題敘述較為模糊,我無法確切的理解您的需求,不過依照我的認知所完成的code如下:
import pandas as pd
import numpy as np
import re
def readFile(path):
file = open(path, 'r+', encoding='utf-8')
content = file.read()
file.close()
return(content)
def process(content):
dataList = []
content = content.split('Flow-Volume-Curve')
if len(content) < 2:
return False
for row in content[1].split('\n'):
r = re.search(r' (([0-9]|\.|\-| )+)', row)
if r:
rowData = r.groups()[0].split(' ')
dataList.append(rowData)
return(dataList)
filePath = './textData.txt'
content = readFile(filePath)
dataList = process(content)
df = pd.DataFrame(dataList)
df.to_excel(filePath.replace('\\', '/').split('/')[-1].replace('.txt', '') + '.xlsx')
此處裡會先讀取文字檔
接著做數字提取
再另存(寫入)xlsx中
希望有幫助到您=^w^=
您好,我嘗試使用您的程式碼,會出現以下錯誤:ValueError: DataFrame constructor not properly called!
我google了一些對此問題的解法,改為:
import pandas as pd
import numpy as np
import re
def readFile(path):
file = open(path, 'r+', encoding='utf-8')
content = file.read()
file.close()
return(content)
def process(content):
dataList = []
content = content.split('Flow-Volume-Curve')
if len(content) < 2:
return False
for row in content[1].split('\n'):
r = re.search(r' (([0-9]|\.|\-| )+)', row)
if r:
rowData = r.groups()[0].split(' ')
dataList.append(rowData)
return(dataList)
filePath = './textData.txt'
content = readFile(filePath)
dataList = process(content)
df = pd.DataFrame(columns=['dataList'])
df.to_excel(filePath.replace('\\', '/').split('/')[-1].replace('.txt', '') + '.xlsx')
但是產生的excel內容為空白,若是有機會想再請教您,謝謝!
改好了,這次的功能調整:
.txt檔處理關於您所述的ValueError問題,我不太清楚你發生時所遇到的究竟是什麼狀況,但至少我在執行時是順利且無錯誤的。
'''
2023 © MaoHuPi
v2.0.1
https://ithelp.ithome.com.tw/questions/10212370
'''
DATA_DIR_PATH = './data'
DATA_START_AT = 'Flow-Volume-Curve'
DATA_END_AT = 'Substance ventolin'
OUTPUT_FILE_MIMETYPE = 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
import os
import pandas as pd
# import numpy as np
import re
mimetypeSettingsData = {
'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet': {
'function': 'to_excel',
'fileExtension': '.xlsx'
},
'application/vnd.ms-excel': {
'function': 'to_excel',
'fileExtension': '.xls'
},
'text/csv': {
'function': 'to_csv',
'fileExtension': '.csv'
}
}
def readFile(path):
file = open(path, 'r+', encoding='utf-8')
content = file.read()
file.close()
return(content)
def between(text, start, end):
text = text.split(start)
if len(text) < 2:
return False
text = text[1]
text = text.split(end)
if len(text) < 1:
return False
text = text[0]
return text
def removeMultipleChar(text, chars):
for char in chars:
text = text.replace(char, '')
return(text)
def process(content):
dataList = []
titleList = []
titleDone = False
content = between(content, DATA_START_AT, DATA_END_AT)
contentRows = content.split('\n')
contentRows.pop()
contentRows.pop(0)
for row in contentRows:
if removeMultipleChar(row, list(' \t\r\n')) == '':
continue
r = re.search(r' (([0-9]|\.|\-| )+)', row)
if r:
rowData = r.groups()[0]
rowName = row.replace(rowData, '')
rowData = rowData.split(' ')
dataList.append([rowName[:-1], *[float(value) for value in rowData]])
else:
if not titleDone:
titleList = row.split(' ')
titleList.insert(0, '')
dataList.insert(0, titleList)
titleDone = True
return(dataList)
def saveOutputFile(dataList, filePath):
if filePath[-4:] == '.txt':
filePath = filePath[:-4]
df = pd.DataFrame(data=dataList)
outputSettings = mimetypeSettingsData[OUTPUT_FILE_MIMETYPE]
filePath = filePath + outputSettings['fileExtension']
getattr(df, outputSettings['function'])(filePath)
print(filePath)
def processFile(filePath):
content = readFile(filePath)
dataList = process(content)
saveOutputFile(dataList, filePath)
DATA_DIR_PATH = DATA_DIR_PATH.replace('\\', '/')
if DATA_DIR_PATH[-1] == '/':
DATA_DIR_PATH = DATA_DIR_PATH[:-1]
for filePath in [path for path in os.listdir(DATA_DIR_PATH) if path.lower()[-4:] == '.txt']:
filePath = f'{DATA_DIR_PATH}/{filePath}'
processFile(filePath)
希望有幫助到您=^w^=
您好,感謝您提供的更新版本,此方式確實可行,且產生的為我所需要的樣式!萬分感激~
最後想和您詢問,這項程式碼僅能套用上述範例,當另外一種格式出現,就無法運作。
會出現AttributeError: 'bool' object has no attribute 'split'。
因此想和您請教,當格式發生轉換!我該如何調整您的程式法,重新自己分切段落呢?
此外,如下範例2,資料中有一條ID:54123456789。
除了表格外我是否能同時將此行列出呢?
非常感謝您上述提供的解決方案,若是能進一步指點我,更加感激,謝謝您!
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
ID:54123456789
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
Resistance & Reactance Spectra
Pred Pre %(Pre/Pred) Post %(Post/Pred) %Chg(Post/Pre)
R5Hz kPal(Lis) 0.34 0.59 15 0.50 18 -15
R20Hz KPa/(L/S) 0.8 0.41 147 0.40 13 -3
X5Hz kPal(Lis) -0.00 -4.15 4848 -0.14 420 -9
Fres. 1/s 19.92 18.35 -8
AX kPa/L 1.57 0.82 -40
R5-20 kPa/(L/s) 0.18 0.10 -43
VT L 0.37 0.87 234 0.94 254 8
CO5Hz 0.8 0.8 3
CO20Hz 1.4 1.0 -0
Level date 20-05-28 21-05-28
Level time 14:56 15:16
Substance ventolin
IOS-PREPOST-BRONCHODILATOR 1/1
之所以會發生您所提到的'bool' object has no attribute 'split'的錯誤,是因為我在betweenfunction 抓不到內容時返回了False。
稍微說明一下原先程式碼所做的事情(下方的標註部分為元程式碼最上方所定義的可修改變數):
讀取DATA_DIR_PATH資料夾下的檔案名稱,並篩選檔案類型
對於要處裡的文字檔逐一進行處理
取得DATA_START_AT與DATA_END_AT之間的文字
把取得的中間段文字進行逐行處理
取出該行中的前面部分作為該行的第一格
取出該行中的後面部分,以空格拆分,並作為該行的後續資料
輸出並以OUTPUT_FILE_MIMETYPE格式儲存
而當送入的.txt檔變成
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
ID:54123456789
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
Resistance & Reactance Spectra
Pred Pre %(Pre/Pred) Post %(Post/Pred) %Chg(Post/Pre)
R5Hz kPal(Lis) 0.34 0.59 15 0.50 18 -15
R20Hz KPa/(L/S) 0.8 0.41 147 0.40 13 -3
X5Hz kPal(Lis) -0.00 -4.15 4848 -0.14 420 -9
Fres. 1/s 19.92 18.35 -8
AX kPa/L 1.57 0.82 -40
R5-20 kPa/(L/s) 0.18 0.10 -43
VT L 0.37 0.87 234 0.94 254 8
CO5Hz 0.8 0.8 3
CO20Hz 1.4 1.0 -0
Level date 20-05-28 21-05-28
Level time 14:56 15:16
Substance ventolin
IOS-PREPOST-BRONCHODILATOR 1/1
時,會因為找不到原先設定的開頭「Flow-Volume-Curve」與結尾「Substance ventolin」而無法正常回傳。
而修改後的code如下:
'''
2023 © MaoHuPi
v3.0.0
https://ithelp.ithome.com.tw/questions/10212370
'''
DATA_DIR_PATH = './data' # 文本資料存放之資料夾
DATA_FILE_EXTENSION = '.txt' # 文本資料檔案之副檔名
DATA_START_AT = 'Pred' # 文本資料的資料區段固定開頭
DATA_END_AT = 'Substance ventolin' # 文本資料的資料區段固定結尾
EXCLUDE_START = False # 是否去除 資料區段開頭 那行
EXCLUDE_END = True # 是否去除 資料區段結尾 那行
OUTPUT_FILE_MIMETYPE = 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet' # 輸出檔案之格式
import os
import pandas as pd
import re
mimetypeSettingsData = {
'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet': {
'function': 'to_excel',
'fileExtension': '.xlsx'
},
'application/vnd.ms-excel': {
'function': 'to_excel',
'fileExtension': '.xls'
},
'text/csv': {
'function': 'to_csv',
'fileExtension': '.csv'
}
}
def readFile(path):
file = open(path, 'r+', encoding='utf-8')
content = file.read()
file.close()
return(content)
def between(text:str, start:str, end:str):
text = text.split(start)
if len(text) < 2:
return False
text = start.join(text[1:])
text = text.split(end)
if len(text) < 1:
return False
text = text[0]
return text
def removeMultipleChar(text, chars):
for char in chars:
text = text.replace(char, '')
return(text)
def valueProcess(value):
try:
value = float(value)
except:
pass
return(value)
def process(content):
dataList = []
titleList = []
titleDone = False
id = between(content, 'ID:', '\n')
print('ID: ' + (id if id else 'Undefined'))
content = between(content, DATA_START_AT, DATA_END_AT)
content = DATA_START_AT + content + DATA_END_AT
contentRows = content.split('\n')
if EXCLUDE_START:
contentRows.pop(0)
if EXCLUDE_END:
contentRows.pop()
for row in contentRows:
if removeMultipleChar(row, list(' \t\r\n')) == '':
continue
r = re.search(r' (([0-9]|\:|\.|\-| )+)', row)
if r:
rowData = r.groups()[0]
rowName = row.replace(rowData, '')
rowData = rowData.split(' ')
dataList.append([rowName[:-1], *[valueProcess(value) or value for value in rowData]])
else:
if not titleDone:
titleList = row.split(' ')
titleList.insert(0, '')
dataList.insert(0, titleList)
titleDone = True
return(dataList)
def saveOutputFile(dataList, filePath):
if filePath[-4:] == '.txt':
filePath = filePath[:-4]
df = pd.DataFrame(data=dataList)
outputSettings = mimetypeSettingsData[OUTPUT_FILE_MIMETYPE]
filePath = filePath + outputSettings['fileExtension']
getattr(df, outputSettings['function'])(filePath)
print('OUTPUT_PATH: ' + filePath)
print('')
def processFile(filePath):
content = readFile(filePath)
dataList = process(content)
saveOutputFile(dataList, filePath)
DATA_DIR_PATH = DATA_DIR_PATH.replace('\\', '/')
if DATA_DIR_PATH[-1] == '/':
DATA_DIR_PATH = DATA_DIR_PATH[:-1]
for filePath in [path for path in os.listdir(DATA_DIR_PATH) if path.lower()[-4:] == DATA_FILE_EXTENSION.lower()]:
filePath = f'{DATA_DIR_PATH}/{filePath}'
processFile(filePath)
本次針對功能的自訂義調整又新增了幾個選項(程式碼最前面的幾行大寫變數),並且已經附上註解,可針對需求再進行調整。
真心建議如果要寫python的自動化程式,就先把python的基礎學完,不然你會不知道要怎麼一個個步驟處理資料。而別人給你的程式碼有問題,或需要再做修改時,也無法直接讀懂其程式碼內容。
如果還有疑問,可以直接在IG私訊我(jhou5846),我會比較快看到並給出回復(致管理員,此非廣告文)。
希望有幫助到您=^w^=
data = '''
sr eff 0.96 1.13 118 0.15 89 -25
R tot 0.30 0.48 161 1.44 146 -10
R eff 0.30 0.42 139 0.38 127 -9
Frcpl 2.51 1.16 74 1.79 71 -4
VT 0.59 1.71 290 0.90 154 -47
Ic 1.91 2.44 128 2.38 125 -3
ERV 1.05 0.36 35 0.53 50 45
RV 1.46 1.50 102 1.26 16 -16
TLC 4.44 4.31 97 4.16 94 -3
RV%TLC 32.90 34.78 106 30.30 92 -13
VC IN 2.96 1.02 68 1.38 47 -32
FVC 2.91 2.81 96 2.90 100 3
FEV 1 2.10 2.29 92 2.38 95 4
FEV1%F 81.65 82.08 1
PEF 6.18 6.64 107 5.43 88 -18
MEF 75 5.57 5.79 104 4.98 89 -14
MEF 50 3.93 2.68 68 3.10 79 16
MEF 25 1.71 0.88 52 1.03 60 17
MMEF 3.46 2.24 65 2.50 72 11
FIF 50 4.18 3.94 -6
'''
def isData(val):
try:
float(val)
except:
return False
return True
for line in data.split("\n"):
line = [float(cell) for cell in line.split(" ") if isData(cell)]
print(line)
用 RegEXP 處理的範例如下:
test_content.txt 內容 :
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
人 4 6 8 “Post
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
####Flow-Volume-Curve####
Pred Pre %... Post %... Chg...
sr eff 0.96 1.13 118 0.15 89 -25
R tot 0.30 0.48 161 1.44 146 -10
R eff 0.30 0.42 139 0.38 127 -9
Frcpl 2.51 1.16 74 1.79 71 -4
VT 0.59 1.71 290 0.90 154 -47
Ic 1.91 2.44 128 2.38 125 -3
ERV 1.05 0.36 35 0.53 50 45
RV 1.46 1.50 102 1.26 16 -16
TLC 4.44 4.31 97 4.16 94 -3
RV%TLC 32.90 34.78 106 30.30 92 -13
VC IN 2.96 1.02 68 1.38 47 -32
FVC 2.91 2.81 96 2.90 100 3
FEV 1 2.10 2.29 92 2.38 95 4
FEV1%F 81.65 82.08 1
PEF 6.18 6.64 107 5.43 88 -18
MEF 75 5.57 5.79 104 4.98 89 -14
MEF 50 3.93 2.68 68 3.10 79 16
MEF 25 1.71 0.88 52 1.03 60 17
MMEF 3.46 2.24 65 2.50 72 11
FIF 50 4.18 3.94 -6
Substance ventolin
python 內容 :
import re,codecs
def detect_by_bom(path, default='utf-8'):
with open(path, 'rb') as f:
raw = f.read(4) # will read less if the file is smaller
for enc, boms in \
('utf-8-sig', (codecs.BOM_UTF8,)),\
('utf-16', (codecs.BOM_UTF16_LE, codecs.BOM_UTF16_BE)),\
('utf-32', (codecs.BOM_UTF32_LE, codecs.BOM_UTF32_BE)):
if any(raw.startswith(bom) for bom in boms):
return enc
return default
def read_data_from_txt(txt_file):
file_type= detect_by_bom(txt_file)
with open(txt_file,'rb') as f:
content = f.read().decode(file_type)
# 試著修正讀入非utf-8編碼文件檔會報錯的BUG
# 取得 介於 Pred Pre %... Post %... Chg... 到 Substance ventolin 之間的內容,用\n分割成串列(ls)
data_ls = re.findall('Pred Pre %... Post %... Chg...(.*)Substance ventolin',content,re.DOTALL)
if data_ls == []:
return []
else:
ls = data_ls[0].split('\r\n')
out_ls=[]
for i in ls:
if i != '':
# 每一行先不管空白,把文字跟數字分開
tmp = re.findall('(^[A-Za-z%]+.*[A-Za-z%].)(.*)$',i)
if tmp == []:
continue
else:
# 數字部份用" "分割成串列(tmp_ls)
tmp_ls=tmp[0][1].split(' ')
# 把 文字部份(標題) 插入 tmp_ls 的第一個元素
tmp_ls.insert(0, tmp[0][0].strip())
# out_ls 新增元素 內容為 tmp_ls
out_ls.append(tmp_ls)
return out_ls
txt_file = "test_content.txt"
result_ls = read_data_from_txt(txt_file)
for i in result_ls:
print(i)
執行結果 :
['sr eff', '0.96', '1.13', '118', '0.15', '89', '-25']
['R tot', '0.30', '0.48', '161', '1.44', '146', '-10']
['R eff', '0.30', '0.42', '139', '0.38', '127', '-9']
['Frcpl', '2.51', '1.16', '74', '1.79', '71', '-4']
['VT', '0.59', '1.71', '290', '0.90', '154', '-47']
['Ic', '1.91', '2.44', '128', '2.38', '125', '-3']
['ERV', '1.05', '0.36', '35', '0.53', '50', '45']
['RV', '1.46', '1.50', '102', '1.26', '16', '-16']
['TLC', '4.44', '4.31', '97', '4.16', '94', '-3']
['RV%TLC', '32.90', '34.78', '106', '30.30', '92', '-13']
['VC IN', '2.96', '1.02', '68', '1.38', '47', '-32']
['FVC', '2.91', '2.81', '96', '2.90', '100', '3']
['FEV', '1', '2.10', '2.29', '92', '2.38', '95', '4']
['FEV1%F', '81.65', '82.08', '1']
['PEF', '6.18', '6.64', '107', '5.43', '88', '-18']
['MEF', '75', '5.57', '5.79', '104', '4.98', '89', '-14']
['MEF', '50', '3.93', '2.68', '68', '3.10', '79', '16']
['MEF', '25', '1.71', '0.88', '52', '1.03', '60', '17']
['MMEF', '3.46', '2.24', '65', '2.50', '72', '11']
['FIF', '50', '4.18', '3.94', '-6']
小建議:
IT界有句古話 : GIGO
https://zh.wikipedia.org/zh-tw/%E5%9E%83%E5%9C%BE%E8%BF%9B%EF%BC%8C%E5%9E%83%E5%9C%BE%E5%87%BA
昨天我的回覆已經達到上限了,以下是sample code:
import re
import openpyxl
def export_Excel(filename, data):
_workbook = openpyxl.Workbook()
_sheet = _workbook["Sheet"]
for i in range(len(data)):
for j in range(len(data[i])):
_sheet.cell(i+1, j+1).value = data[i][j]
_workbook.save(filename)
def read_Source_File(filename):
flag = False
context = []
with open(filename, "r", encoding="utf-8") as fp:
line = fp.readline()
while line:
if(flag):
context.append(line)
if("Flow-Volume-Curve" in line):
flag = True
line= fp.readline()
fp.close()
return context
if __name__ == "__main__":
context = read_Source_File("samplefile.txt")
result = [context[0].split(" ")]
result[0].insert(0, "") # shift column name right
for item in context[1:-1]:
one_row = []
key_position = re.search("[ ][0-9]*", item).span()[0]
the_first_column = item[:key_position]
one_row.append(the_first_column)
one_row.extend(item[key_position+1:].split(" "))
result.append(one_row)
export_Excel("out.xlsx",result)
好多高手都已經回答正確答案了,小弟也學習前輩的code,自己改寫如下:
test.txt檔案:
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
人 4 6 8 “Post
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
####Flow-Volume-Curve####
Pred Pre %... Post %... Chg...
sr eff 0.96 1.13 118 0.15 89 -25
R tot 0.30 0.48 161 1.44 146 -10
R eff 0.30 0.42 139 0.38 127 -9
Frcpl 2.51 1.16 74 1.79 71 -4
VT 0.59 1.71 290 0.90 154 -47
Ic 1.91 2.44 128 2.38 125 -3
ERV 1.05 0.36 35 0.53 50 45
RV 1.46 1.50 102 1.26 16 -16
TLC 4.44 4.31 97 4.16 94 -3
RV%TLC 32.90 34.78 106 30.30 92 -13
VC IN 2.96 1.02 68 1.38 47 -32
FVC 2.91 2.81 96 2.90 100 3
FEV 1 2.10 2.29 92 2.38 95 4
FEV1%F 81.65 82.08 1
PEF 6.18 6.64 107 5.43 88 -18
MEF 75 5.57 5.79 104 4.98 89 -14
MEF 50 3.93 2.68 68 3.10 79 16
MEF 25 1.71 0.88 52 1.03 60 17
MMEF 3.46 2.24 65 2.50 72 11
FIF 50 4.18 3.94 -6
Substance ventolin
code:
# 先找出讀取檔案的起始和結束行
import pandas as pd
import re
file = 'test.txt'
# 設定空的索引
indexes = []
with open(file) as f:
lines = f.readlines()
for i, line in enumerate(lines):
# 搜尋檔案要讀取的起始位置
if line.startswith('Pred Pre %... Post %... Chg...'):
# 找到起始位置後,下一行才開始讀取
s = i+1
# 搜尋檔案要讀取的結束位置
elif line.startswith('Substance ventolin'):
e = i
indexes.append((s, e))
else:
pass
# 設定空的list儲存要整理的英文名字
result_name = []
# 設定空的list儲存要整理的數據
result_data = []
# 讀取起始和結束位置中間的資料
for line in lines[s:e]:
# 這邊是用ccutmis前輩的Regex來尋找與切割資料:
temp = re.findall('(^[A-Za-z%]+.*[A-Za-z%].)(.*)$', line)
# 原始資料中的英文名存到result_name
result_name.append(temp[0][0])
# 原始資料中的數據存到result_name
result_data.append(temp[0][1].split(' '))
df_name = pd.DataFrame(result_name)
df_data = pd.DataFrame(result_data)
# 將以上的2個dataframe 串接
df = pd.concat([df_name, df_data], axis=1)
# 將欄名修正為「col_1......, col_x」
df.columns=['col_' + str(x) for x in range(1, len(df.columns)+1)]
df
結果如下: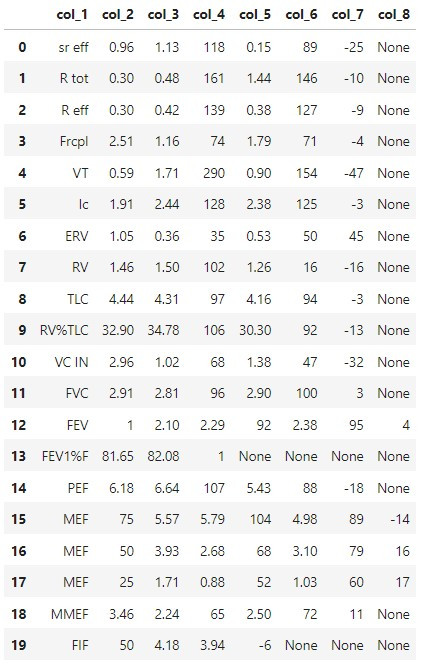
請問您是要一個text檔輸出成一個excel?還是多個text檔整理完後,輸出成一個excel?
將一個資料夾內的所有text檔,輸出成excel~
至於一個excel(不同sheet),或是個別一個excel都是可以的! 想和您請教~
您的提問,直接寫成文章回覆比較清楚:
https://ithelp.ithome.com.tw/articles/10311564

