詢問雲端廠商為何重啟電腦不會影響到我們的服務?
在思考Server一定會有意外,可能需要重啟,但是雲端廠商為何可以讓我們的服務不受影響的重啟服務
請問是這樣,這項技術需要如何學習呢?
舉例: 自己公司架設的 hyper-v 重啟,所有在內的虛擬機都會受影響
已邀請的邦友 {{ invite_list.length }}/5
不停機維護, 是高可用性機房維運的基本技能, 要不然哪來的 SLA > 99.9% 可用度;
這需要從架構就開始規劃, 包含各項硬體, 以及應用軟體都可能需要某些程度的配合.
而且這也不是甚麼新的概念, 1976 年的 Tandem 電腦就已經可以做到不停頓容錯了:
https://en.wikipedia.org/wiki/NonStop_(server_computers)
後期的小型系統, 1989 年的 SCO Unix 也有能力做到 Non-Stop 不停機服務
以上都已經是 30 年前的老系統了, 現代的電腦沒有理由辦不到.
當然現在的技術架構以及深度, 和以前大不相同, 但概念上並沒有太大差異,
問題只是在: 願意花多少錢, 來達到服務不停頓的程度? 錢掏出來都辦得到.
你用的 Hyper-V 也辦得到, Hyper-V Cluster 就是最簡單的不停頓容錯 (只是你公司沒有花錢把硬體架構建起來, 所以才沒有容錯能力), 微軟的公有雲只是將同樣技術擴充到 Azure Stack 階層, 做到: Storage, Network 都可以容錯.
一個可以不停頓的 Hyper-V Cluster 大概需要這些: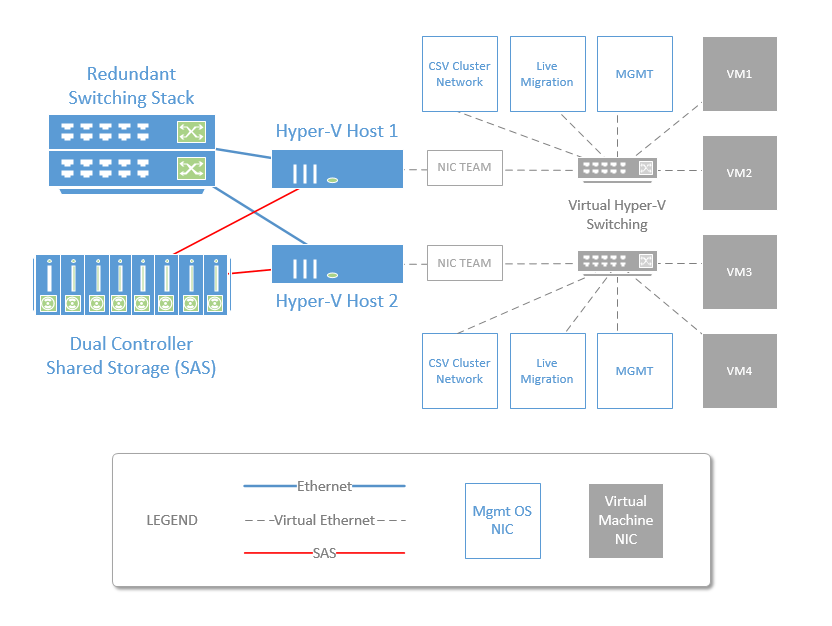
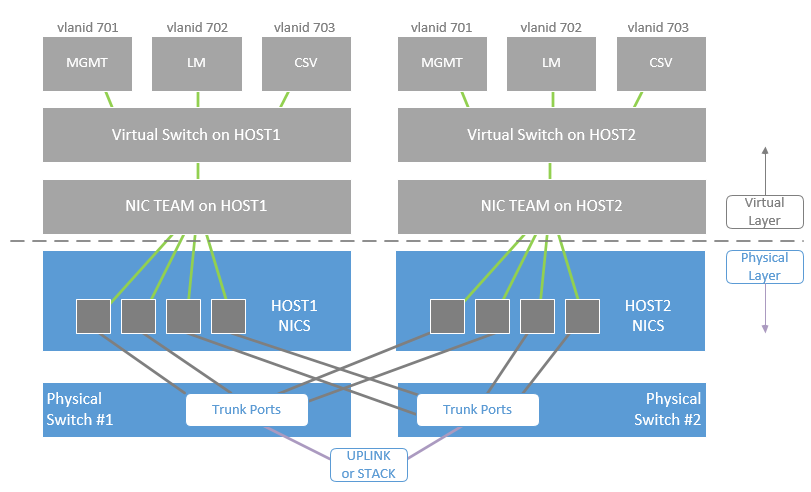
如果你想自己做的話,
下面是 Dell 的 Solution Guide, 教你如何建出一個 Hyper-V 的容錯叢集:
https://dl.dell.com/manuals/all-products/esuprt_electronics/esuprt_software/esuprt_virt_solutions/dell-soln-guides-for-ms-hyper-v_user's%20guide4_en-us.pdf
這裡涉及到一些虛擬化存儲的概念
拿vmware公司為例,旗下擁有的虛擬化存儲vsan就是一個存儲方案
能做到CPU,記憶體等與硬碟分離,有一套設備負責提供硬體支持,另外一套設備提供存儲支持
當使用的時候,硬碟都是掛載到不同的虛機上的
這樣類似快照,克隆,故障轉移等亦可以實現
至於說停機維護,一般類似提供硬體支持的設備和存儲支持都有集群,維護的時候都會確保有機器可用(因為不會全部機器都進入維護狀態
雲端的基礎架構,
基本上也是HCI(超融合),
在 HCI 架構下, Sever 及 Storage(HCI Local Storage) 都作到 HA,
甚至更高層級的 FT(容錯),
但以雲端公司的重啟來說,
通常一定是計畫性重啟,
基本上根本用不到HA及FT,
只是作虛擬機的事先搬遷(Motion),
虛擬機的搬遷是線上移動的,
移動過程基本上前端應用都不會有感覺,
所以你如果想學,基本上在 Hyper-v 的環境,
首先你得有設備,兩套 Server(基本上用 pc 練也ok)
HCI 架構的話磁碟數量要夠, SSD 必備(因為要當 Cache)
這樣在 Hyper-v 環境就可以透過 S2D 的架構把 HCI 建構起來
自己家的Hyper-V重啟,要完全不影響上面的VM也不是不可以呀!
一般公司在實務操作上通常會折衷啦,關鍵系統才會作即時移轉,不是那麼重要的系統就發個停機公告來處理。
