const inputStrings = ["(1) 教育類", "(2) 科學類", "(3) 語言類"];
const regex = /\(\d+\)\s*(.*)/;
inputStrings.forEach(inputString => {
const match = inputString.match(regex);
if (match) {
const result = match[1];
console.log(result);
}
});
以上代碼,取自 ChatGPT
首先,我先推薦你一個網站:https://regex101.com/
你可以到上面自己做 regex 相關的實驗,如下面附圖: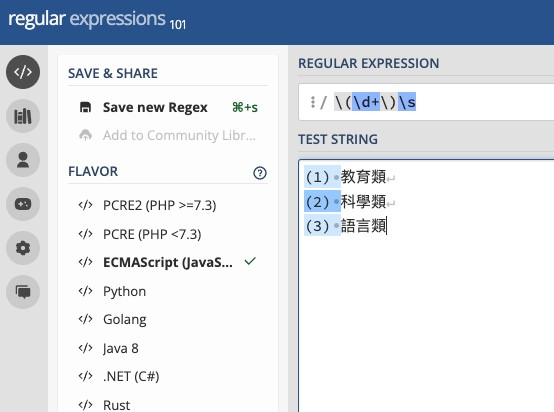
接著是你的問題:
"(1) 教育類" => "教育類"
"(2) 科學類" => "科學類"
"(3) 語言類" => "語言類"
我這邊使用 JavaScript 的取代方式作為範例:
let text = "(1) 教育類";
let modifiedText = text.replace(/\(\d+\)\s/, "");
console.log(modifiedText); // "教育類"
在這裡,正則表達式 /(\d+)\s/ 的含義是:
所以 /(\d+)\s/ 的整體含義就是匹配一個左括號,接著是一個或多個數字,然後是一個右括號,最後是一個空格。
然後,我們就使用這個正則表達式來替換掉原來的文字中匹配到的部分,替換為空字符串(即刪除這部分)。這就得到了我們想要的結果。
你至少說是哪個語言...
python的話我會用name group做。
https://ideone.com/7RvV8S
其他語言不一定支援。
import re
testWords = ["(1) 教育類", "(2) 科學類", "(3) 語言類"]
pat = re.compile(r"\(\d\)\W(?P<type>.+)")
for w in testWords:
m = pat.search(w)
print(m.group("type"))
using System;
using System.Text.RegularExpressions;
class Program
{
static void Main(string[] args)
{
string[] inputStrings = { "(1) 教育類", "(2) 科學類", "(3) 語言類" };
string regexPattern = @"\(\d+\)\s*(.*)";
Regex regex = new Regex(regexPattern);
foreach (string inputString in inputStrings)
{
Match match = regex.Match(inputString);
if (match.Success)
{
string result = match.Groups[1].Value;
Console.WriteLine(result);
}
}
}
}
可以直接用 ChatGPT 改寫成 C# 解法,供參考
