聚合(Aggregation)功能無論是資料處理或分析中不可或缺的功能。無論是最常見的avg、sum、min、max,count等或是自定義的聚合,接下來就來個Spark中的聚合函數大亂鬥吧~
Spark中常見的聚合函數大概有下列這些:
看了是不是有點頭暈....不過不緊張:依複雜度由繁到簡為下:
CombineByKey=>Aggregate系列=>Fold系列=>Reduce系列=GroupBy系列
CombineByKey是以上其他集合函數的底層實作,我們有機會再來看他。
讓我們由繁到簡,倒吃甘蔗吧!
在講Aggregation之前必須說明,因為RDD是一個分散式的資料集合,也就是說一個RDD的資料實體會被分割存放在不同的節點上,而這些被分割的資料集通常被稱為Partition*直接上張圖吧:
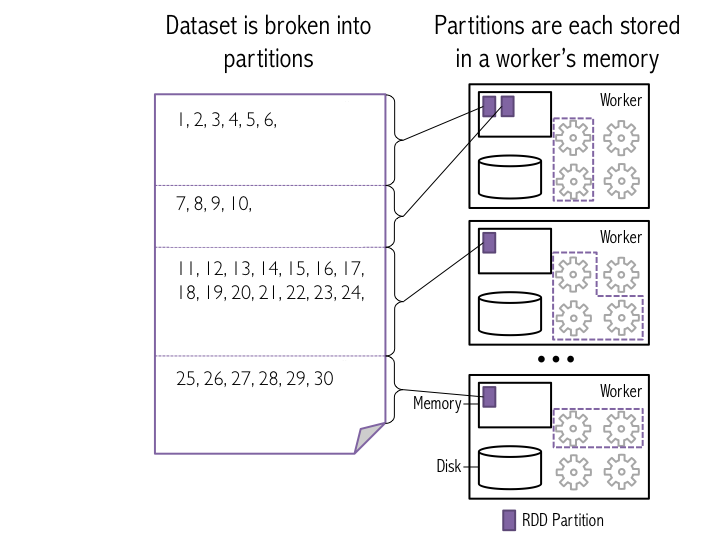
圖片來源:http://datascience-enthusiast.com/Python/Apache_Spark1.html
[Snippet. 18]Aggregate
aggregate總共必須提供3個參數:
同一partition內的進行reduce函數1操作),如此每個分區會得到一個單一結果
合併不同分區的單一結果,得到最後的結果)知道為何要提分區了吧,因此之後在使用Aggregate時要有兩階段的思維:
zero value會在兩次reduce中作為初始值進行疊加,3個參數在Aggregate中的格式為:aggregate(zero Value)(func1, func2),看到兩個()參數有想到啥嗎?沒錯currying的寫法。
*其實稱作fold函數比較精確(因為有帶zero value)
先看個用aggregate簡單求平均(且為單1分區)的例子吧:
scala> val nums = sc.parallelize(List(1,2,3,4,5,6)) ①
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val (sum,num) = nums.aggregate((0,0)) ②
(
(acc,number) => (acc._1 + number, acc._2 + 1), ③
(par1,par2) => (par1._1 + par2._1, par1._2 + par2._2) ④
)
sum: Int = 21
num: Int = 6
①定義一個簡單的RDD
②zero value:在此為(0,0)的KV
③reduce函數1:
因為初始值是KV,所以reduce的input為一組(acc,number)的KV,然後遍歷整個List。(acc._1 + number, acc._2 + 1)運算過程大概如下:
初始值遇到1:(0,0)=>(0+1,0+1)=(1,1)
繼續遇到2:(1,1)=>(1+2,1+1)=(3,2)
繼續遇到3:(3,2)=>(3+3,2+1)=(6,3)
繼續遇到4:(6,3)=>(6+4,3+1)=(10,4)
繼續遇到5:(10,4)=>(10+5,4+1)=(15,5)
繼續遇到6:(15+6,5+1)=(21,1)
④reduce函數2:不同分區的資料如何merge所用的reduce函式,如果有分區的話,想必一定是不同分區的sum與sum相加,num與num相加吧,所以為(par1._1 + par2._1, par1._2 + par2._2)
再看另外一個有分區的例子吧:
scala> var data = sc.parallelize(List(1,2,3,4,5,6), 3) ①
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at parallelize at <console>:24
def printPartitionInfo(index: Int, iter: Iterator[(Int)]) : Iterator[Int] = { ②
println("---------------[partID:" + index + ", val: " + iter.toList + "]")
iter
}
data.mapPartitionsWithIndex(printPartitionInfo).collect
scala> data.mapPartitionsWithIndex(myfunc).collect
---------------[partID:1, val: List(3, 4)]
---------------[partID:2, val: List(5, 6)]
---------------[partID:0, val: List(1, 2)]
res7: Array[Int] = Array()
scala> def interPartition(a:Int, b:Int) : Int = {a * b} ③
interPartition: (a: Int, b: Int)Int
scala> def crossPartition(a:Int, b:Int) : Int = {a + b} ④
crossPartition: (a: Int, b: Int)Int
①如何定義一個3個分區的RDD?sc.parallelize(List(1,2,3,4,5,6), 3) XD
②檢查一下分區的資訊,這是為了範例準備用,可以跳過看結果即可:
分區0:(1,2)
分區1:(3,4)
分區2:(5,6)
③reduce函數1:interPartition:簡單的疊乘(同區)
④reduce函數1:interPartition:簡單的疊加(跨區)
OK,如果zero value為10,結果為何?想一下吧
scala> data.aggregate(10)(interPartition,crossPartition)
分析:
分區0:(1,2)=>1012=20
分區1:(3,4)=>1034=120
分區2:(5,6)=>1056=300
分區0,1,2=>10+20+120+300=450答對了嗎?



 iThome鐵人賽
iThome鐵人賽