看懂Aggregate之後,再來的就簡單多了,繼續討論其他的聚合函數吧,還有:
SeqOp,用來聚合同分區的資料;Combiner,用來合併跨分區的聚合結果來產生最終結果:[Snippet. 19]AggregateByKey
KV中也有個AggregateByKey,類似的概念,只是資料聚合的單位最後是By Key:
格式:aggregateByKey(zero value)(SeqOp, Combiner)
直接看個求平均的例子吧:
scala> var data = sc.parallelize(List((1,3),(1,2),(1, 4),(2,3),(2,10),(3,6))) ①
data: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> data.aggregateByKey((0,0))( ②
(acc,value) => (acc._1+value,acc._2+1), ③
(acc1,acc2)=>(acc1._1+acc2._1,acc1._2+acc2._2)).collect ④
res1: Array[(Int, (Int, Int))] = Array((1,(9,3)), (2,(13,2)), (3,(6,1)))
①定義一個簡單的pairRDD
②zero value:在此為(0,0)的KV,後面以currying的方式接第二組參數
③SeqOp: 同一個partition且同一個key中疊加數據,前為總和,後為數量
④Combiner疊加每個partition
想要一條龍直接得到平均可以再後面加個mapValues進行處理:
scala> data.aggregateByKey((0,0))(
(acc,value) => (acc._1+value,acc._2+1),
(acc1,acc2)=>(acc1._1+acc2._1,acc1._2+acc2._2)).
mapValues(sumCount=> 1.0* sumCount._1/sumCount._2).
collect
res6: Array[(Int, Double)] = Array((1,3.0), (2,6.5), (3,6.0))
[Snippet. 20]Fold
大魔王打完了,接下來打打小怪吧XD~
fold簡單說是Aggregate的簡化版本,他讓Seq與Combiner帶入相同的reduce函式:
例如以下:
scala> val data = sc.parallelize(List(1,2,3,4,5,6))
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:24
scala> data.fold(0)((x,y)=>(x+y))
res7: Int = 21
scala> data.fold(0)(_+_)
res8: Int = 21
簡單吧,換個zero value玩玩:
scala> data.fold(10)(_+_)
res9: Int = 111
scala> data.mapPartitionsWithIndex(printPartitionInfo).collect
---------------[partID:1, val: List(1)]
---------------[partID:0, val: List()]
---------------[partID:5, val: List(4)]
---------------[partID:3, val: List(3)]
---------------[partID:2, val: List(2)]
---------------[partID:4, val: List()]
---------------[partID:7, val: List(6)]
---------------[partID:6, val: List(5)]
用昨天印出partition的函式看看,喔~原來RDD幫我們把data RDD切的這麼細,足足有8個partition阿。順便提一下,如果沒有指定平行度,預設平行度(也就是Spark幫你開幾個partition)會等於核心數量。OK,每個初始值都是10的話:10*8+21=101,再加上Combiner組合每個partition的zero value也是10:101+10=111。這個故事告訴我們要小心規劃partition以及zero value...。
[Snippet. 21]FoldByKey
差不多的概念,只是換成是ByKey:
scala> var data = sc.parallelize(List((1,3),(1,2),(1, 4),(2,3),(2,10),(3,6)))
data: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[14] at parallelize at <console>:24
scala> data.foldByKey(0)(math.max(_,_)).collect
res13: Array[(Int, Int)] = Array((1,4), (2,10), (3,6))
scala> data.foldByKey(5)(math.max(_,_)).collect
res14: Array[(Int, Int)] = Array((1,5), (2,10), (3,6))
[Snippet. 22]Reduce
Reduce則是再簡化版,連zero value都不用輸入了,就不用考慮zero value啦,這對初始值沒有需求的應用更好用~
scala> val data = sc.parallelize(List(1,2,3,4,5,6))
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[22] at parallelize at <console>:24
scala> data.reduce(_+_)
res15: Int = 21
[Snippet. 23]ReduceByKey
類似概念,只是處理對象是PairRDD,這邊一定要放一下wordCount致敬一下XD
scala>val words = Array("one", "two", "two", "three", "three", "three")
words: Array[String] = Array(one, two, two, three, three, three)
scala> val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
wordPairsRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[31] at map at <console>:26
scala>val wordsCountWithReduce = wordsRDD.
reduceByKey(_ + _).
collect()
wordsCountWithReduce: Array[(String, Int)] = Array((two,2), (one,1), (three,3))
[Snippet. 24]GroupBy
就跟DB中的GroupBy一樣,但要要透過函式自訂By啥東西(也就是Key值):
scala> val data = sc.parallelize(List(1,2,3,4,5,6,6,6,6))
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at parallelize at <console>:24
scala> data.groupBy(x=>x).collect
res19: Array[(Int, Iterable[Int])] = Array((1,CompactBuffer(1)), (2,CompactBuffer(2)), (3,CompactBuffer(3)), (4,CompactBuffer(4)), (5,CompactBuffer(5)), (6,CompactBuffer(6, 6, 6, 6)))
groupBy(x=>x)意思就是By每個元素啦
[Snippet. 25]GroupByKey
那GroupByKey就不用多說了...
scala> wordsRDD.groupByKey.collect
res22: Array[(String, Iterable[Int])] = Array((two,CompactBuffer(1, 1)), (one,CompactBuffer(1)), (three,CompactBuffer(1, 1, 1)))
試著用GroupByKey做wordCount吧:
scala> val wordsCountWithGroup = wordsRDD.
groupByKey().
map(w => (w._1, w._2.sum)).
collect()
wordsCountWithGroup: Array[(String, Int)] = Array((two,2), (one,1), (three,3))
OK,有沒有發現ReduceByKey跟GroupByKey感覺都可以ByKey做Aggregation,那該用誰?
DataBrick的knowledge base中在Avoid GroupBy文章中明確指出大部份情況你會希望使用ReduceByKey。
原因呢?直接上圖吧!
GroupByKey底層資料交換機制: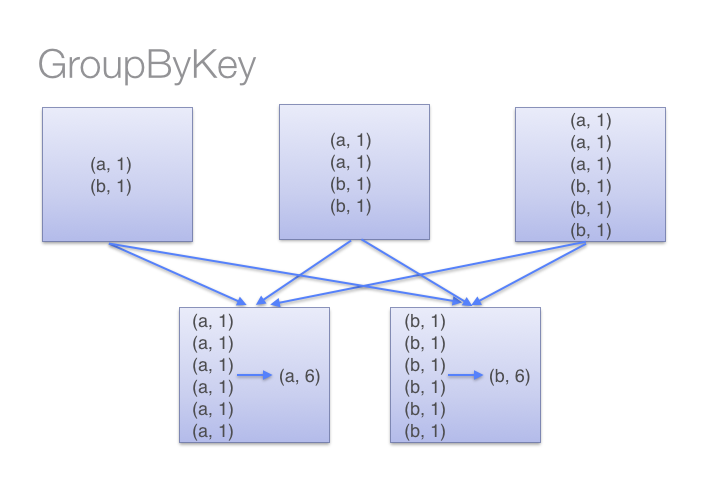
ReduceByKey底層資料交換機制: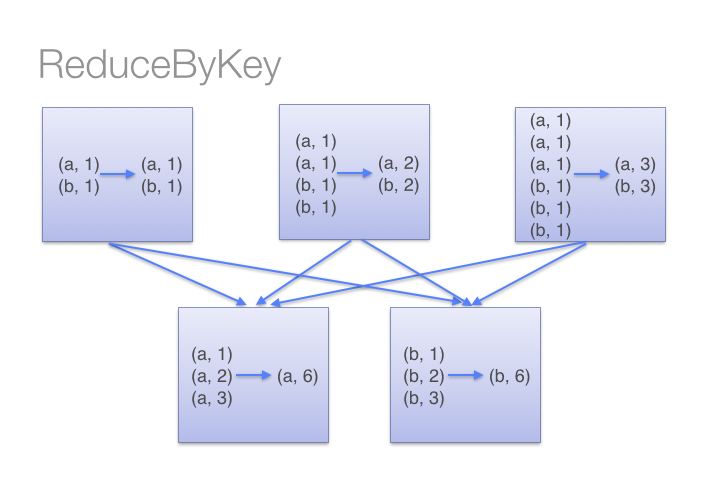
ReduceByKey在每個分區會先用reduce函式Aggregate一次,然後再shuffling資料做合併;而GroupByKey則會直接shuffling然後套一次reduce函式。有感覺了嗎?


