前半段透過「傳感器」( 距離偵測、光線偵測...等 ) 的章節大致上告於段落,雖然還可以結合許多的傳感器做出千變萬化的創意,不過應用的方法都是大同小異,這個章節開始要慢慢進入「網頁前端」的領域,真正來透過一些網頁的服務或技巧,實現許多傳統物聯網比較難達成的應用。
首先來看到「語音辨識」,語音辨識的技術其實存在已久,而 Chrome 瀏覽器也早就將其納入預設的支援,由於是 Chrome 內建的功能,所以不需要額外載入其他資源就可以運行,但也很可惜的現在就只有桌上版的 Chrome 才支援 ( Android 版本指部分支援,iOS 版本則是尚未支援 ) ( 語音辨識文章可以參考我之前寫的:http://www.oxxostudio.tw/articles/201509/web-speech-api.html )
有興趣的人可以先到這個 demo 網站看看:https://www.google.com/intl/en/chrome/demos/speech.html ,下拉選單選擇自己要念的語言,按一下右上的麥克風,就可以開始玩語音輸入了。
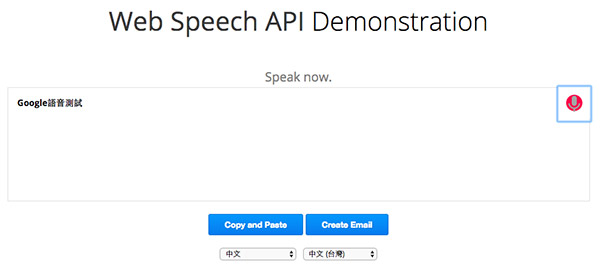
如果覺得直接寫程式碼太複雜,其實 Webduino Blockly 線上工具 ( https://blockly.webduino.io ) 也有提供語音辨識的功能,如果不想寫這麼多程式的,也可以直接用線上工具體驗看看。
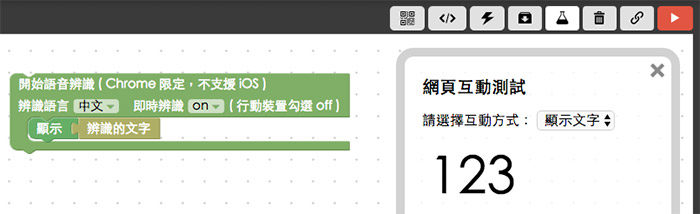
( 解答連結:https://blockly.webduino.io/#-K_3CKDKUO5_6lHnAyjN )
不過既然是鐵人賽,就是要講點真功夫,來看一下怎麼實作語音辨識,語音辨識一開始要判斷「webkitSpeechRecognition」有沒有存在瀏覽器裡,因為這是內建於瀏覽器的 api,從 webkit 的字樣我們也可以知道,Firefox 和 IE 應該就 GG 了,所以一開始的程式可以這樣寫:
if (!('webkitSpeechRecognition' in window)) {
// do something...
} else {
// do something...
}
if 裡面就可以放個 alert 或顯示文字作為警告,重點放在 else 裏頭,一開始我們要先建立 webkitSpeechRecognition 物件,接著我們才可以使用這個物件的屬性來做設定。
var recognition = new webkitSpeechRecognition();
再來我們來瞭解一下有哪些屬性可以用:
recognition.continuous=true/false
這個屬性是布林值,如果設定為 true,表示除非我們停止辨識,不然就會一直持續的辨識語音轉換為文字,如果設定為 false,在辨識一段話完成之後就會結束辨識。
recognition.interimResults=true/false
這個屬性也是布林值,如果設定為 true,表示在我們講話的當下就會即時辨識,不然就會在一段話結束之後,才會開始辨識。
recognition.lang="語系"
設定辨識的語系,如果是講中文,就要設定為「cmn-Hant-TW」,如果是英文,就可以設定為「en-US」,當然 Google 所提供的語系非常多,可以從上面範例連結的原始碼看到對應的語系喔!不過也是因為要連結到 Google 的語系資料庫,所以基本上沒有網路也就無法進行語音辨識了。
recognition.onstart=function(){}
「開始」辨識的時候要執行什麼函式。
recognition.onend=function(){}
「停止」辨識的時候要執行什麼函式。
recognition.start();
「開始辨識」的 API。
recognition.stop();
「停止辨識」的 API。
recognition.onresult=function(event){}
當「辨識有結果」的時候,要做什麼事情。
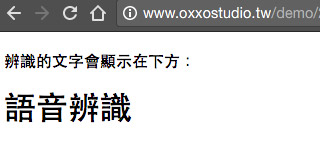
recognition.onresult 是進行語音辨識最關鍵的動作,所以我們要來解構一下語音辨識時的結果,用下面的範例來看看 event 長怎樣,當我們講話進行辨識的時候,就會印出 event。( 範例:http://www.oxxostudio.tw/demo/201509/web-speech-api-demo01.html )
var recognition = new webkitSpeechRecognition();
recognition.continuous=true;
recognition.interimResults=true;
recognition.lang="cmn-Hant-TW";
recognition.onstart=function(){
console.log('開始辨識...');
};
recognition.onend=function(){
console.log('停止辨識!');
};
recognition.onresult=function(event){
console.log(event);
};
recognition.start();

從印出來的結果可以看到,每一段話之間其實都存在著一個「isFinal」的屬性,這個屬性如果是 true,表示這段話結束,就會把這段話存為一個 result,因此我們可以從這邊發現幾個比較重要的 event 屬性如下:
event.results[i]
代表辨識了幾段話,每段話都會存在 results 這個陣列裡面,如果要獲取所辨識的值,可以直接用數字從陣列中取出。
event.resultIndex
表示目前辨識的這段語句,處於陣列的第幾個位置,其實跟 index 是很像的。
event.results[i].isFinal
承如上面所說的,等於 true 表示這段話判斷結束,等於 flase 表示還在判斷。( 如果是用手機的瀏覽器,就會都是 false,因此如果要用電腦瀏覽器來模擬手機的辨識狀態,記得要設為 flase )
event.results[i][j]
每個語句所辨識出來的結果,如果我們在一開始把 recognition.interimResults 設為 true,你就會發現同一句的辨識結果會有好幾個,因為在你講話的當下,就會開始進行辨識,如果是 flase,那麼就只會有一個結果。
event.results[i][j].transcript
每個語句所辨識出來的結果文字顯示。
event.results[i][ j].confidence
辨識的可信度,是一個由 0 到 1 的浮點數,表示辨識的準確度。
有了上面的屬性列表,我們就可以做一個即時辨識並把文字顯示在網頁上頭的範例:( 範例:http://www.oxxostudio.tw/demo/201509/web-speech-api-demo02.html )
var show = document.getElementById('show');
var recognition = new webkitSpeechRecognition();
recognition.continuous=true;
recognition.interimResults=true;
recognition.lang="cmn-Hant-TW";
recognition.onstart=function(){
console.log('開始辨識...');
};
recognition.onend=function(){
console.log('停止辨識!');
};
recognition.onresult=function(event){
var i = event.resultIndex;
var j = event.results[i].length-1;
show.innerHTML = event.results[i][j].transcript;
};
recognition.start();
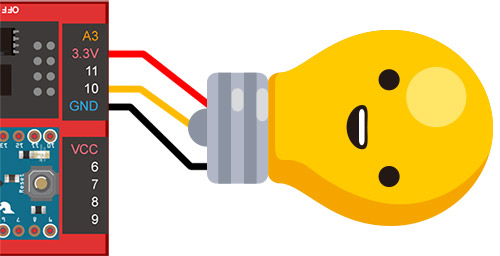
了解語音辨識的用法之後,接著就來看一下怎麼把語音辨識和智慧插座結合,燈泡接線圖很簡單,可以回顧一下前面 Day 03 - 智慧插座的介紹與組裝 和 Day 04 - 使用網頁操控智慧插座
一如往常,HTML 的部分先在自己的網頁內引入「 webduino-min.js 」還有「 webduino-blockly.js 」這兩個 JavaScript,在 body 的區域放入一個 h2 來顯示辨識出來的文字,然後放入兩張燈泡一明一暗的圖片,讓接收到語音辨識的時候,網頁上的燈泡也會發生反應。
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no">
<title>Webduino</title>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script>
<script src="https://webduino.io/components/webduino-js/dist/webduino-all.min.js"></script>
<script src="https://blockly.webduino.io/webduino-blockly.js"></script>
</head>
<body>
<h2 id="show"></h2>
<img src="http://example.oxxostudio.tw/it2016/it2016-day05-on.jpg" id="on">
<img src="http://example.oxxostudio.tw/it2016/it2016-day05-off.jpg" class="show" id="off">
</body>
</html>
CSS 的部分就只是寫個簡單的控制燈泡圖片有沒有出現而已。
img{
display:none;
}
.show{
display:block;
}
JavaScript 的部分一開始先設定一些變數,以及語音辨識的參數,比較特別的是我在這裡多設定一個非官方的屬性 recognition.status = true,因為語音辨識會在「切換分頁」或是「五分鐘內沒有接收到訊號」的情狀下中斷,因此多加一個判斷,讓「非使用者自行中斷」的情形發生時,又會自動啟動語音辨識。
至於接下來的判斷,因為只有「開燈」與「關燈」的字詞而已,所以這邊就單純使用 indexOf 來判斷,當然如果邏輯寫得更複雜,應該就能做出更好的判斷囉!
$(function(){
var led,
$show=$('#show'),
$on = $('#on'),
$off = $('#off'),
a = 0,
result;
var recognition = new webkitSpeechRecognition(); //new 一個語音辨識物件
//語音辨識參數設定
recognition.continuous = true;
recognition.interimResults = true;
recognition.lang = "cmn-Hant-TW";
recognition.status = true; //手動添加判斷,避免如果五分鐘沒有語音,就會自動停止
recognition.onstart=function(){
$show.text('語音辨識中...');
};
recognition.onend=function(){
if(recognition.status === true){
recognition.start();
}else{
$show.text('停止辨識!');
}
};
//裝置連線
boardReady('你的裝置 ID', function (board) {
board.systemReset();
board.samplingInterval = 250;
led = getLed(board, 10); //設定 LED 為 10 號腳
recognition.onresult=function(event){
var i = event.resultIndex;
var j = event.results[i].length-1;
result = event.results[i][j].transcript; //取出語音辨識結果
$show.text(result); //顯示語音辨識結果
if(result.indexOf('開燈')!== -1){
led.on();
$on.addClass('show');
$off.removeClass('show');
}else if(result.indexOf('關燈')!== -1){
led.off();
$on.removeClass('show');
$off.addClass('show');
}
};
recognition.start();
});
});
用 Chrome 打開網頁,就可以用講話來控制燈泡的亮滅囉。
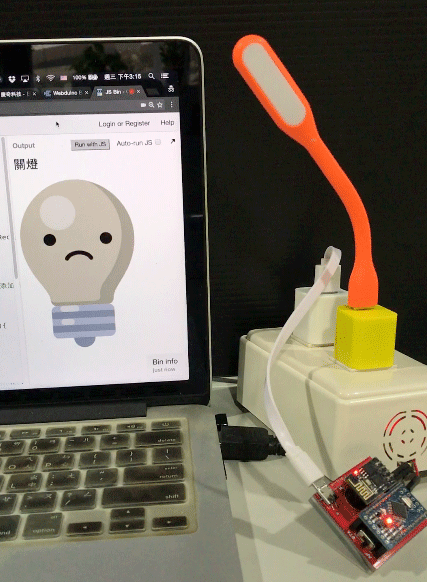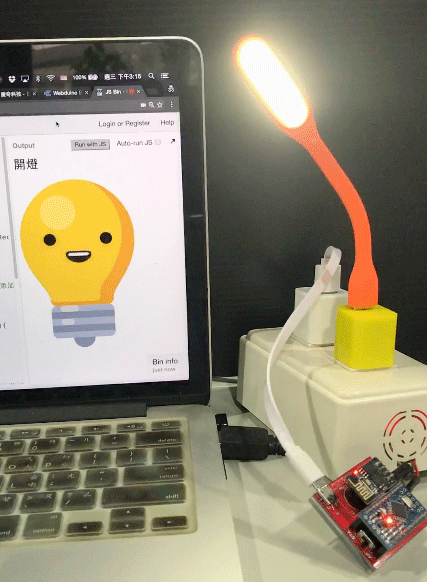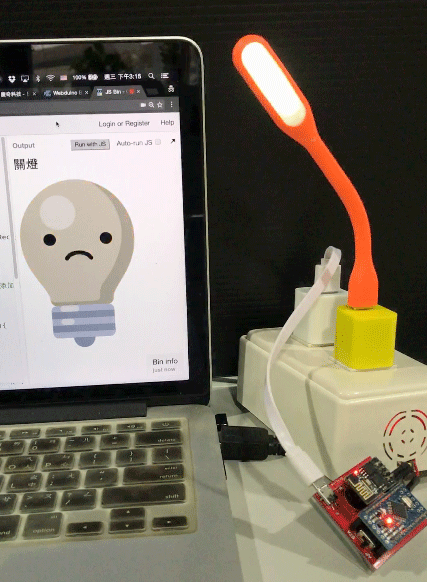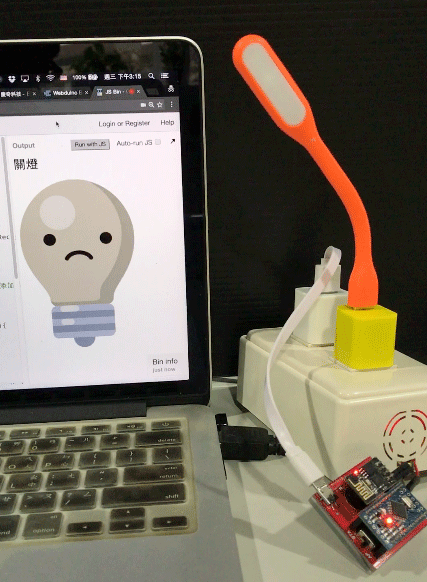
( 範例程式:http://bin.webduino.io/fayi/1/edit?html,js,output )
如果是用 Webduino Blockly 來完成,積木的長相就會像這樣: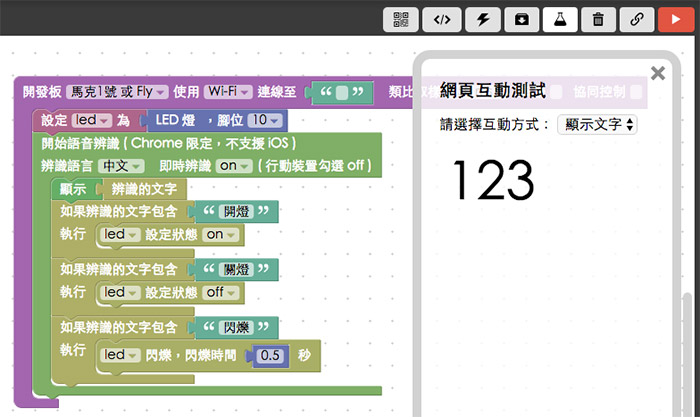
( 範例程式:https://blockly.webduino.io/#-K_3FH2s4Bt0IUe0Tcft )
其實語音辨識技術的難度並沒有很高,而且辨識度也滿好的,相信許多的應用都會使用到語音辨識的技術囉!( 其實像我自己用 line 聊天常常都會用語音輸入的方式 )
參考資料


