前面我們大致介紹完deep learning的架構了,那現在我們來介紹如何訓練。
看似一個龐大的網路,又沒有一個像樣的loss function,到底要怎麼訓練呢?
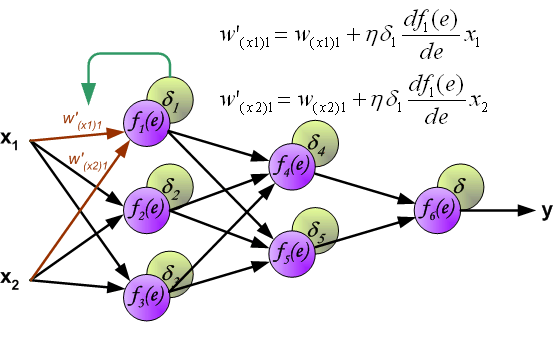
這邊我們介紹一個backpropagation algorithm,他其實gradient descent的延伸版本喔!
其實是這樣的,backpropagation分為兩個phase,但是其中有太多的數學跟微分方程我就不在這裡介紹了(謎:其實是你不想寫數學式吧!
剛剛說他沒有loss function其實是不對的拉!XD
他有loss function!而且用的error是mean square error方法 (MSE),跟前面講的least square方法有點像!
也就是將預測值跟實際值相減後平方的平均,通常前面為了保持微分項是一致的,會加個二分之一倍的係數。
在forward phase,會把資料從input layer讀進來,通常input layer不做任何的轉換。
要進入第1層的hidden layer之前會整個做一次線性轉換,也就是乘上權重的矩陣W^T*X,這裡的運算就相對於是將每個節點連結到下一個節點所做的乘上權重的運算,乘完之後就會進入hidden layer中進行一個非線性的轉換,f(W^T*X),這樣就算完成一次的運算了,運算的結果就當作這個節點的值,然後繼續往下傳。
Forward phase會做的事情就是把模型從頭算過一遍就會得到y',也就是最後的outcome。
什麼?你問我哪來每一層的W嗎?當然是一開始初始化的時候隨機生成的囉~~~
除非你對每一層的運算有做過pretrain,像是你可以用其他比較簡單的模型先train過一些參數,然後再套用到這邊來。
接著就會進入到backpropagate的phase了,這邊會用gradient descent的方法去逐步更新每個節點的權重。
要更新就要算出每個節點的error是多少,所以就會從最後一個節點開始做倒推,output layer本身並沒有做非線性的轉換,所以只需要將y'跟y去計算MSE就可以了,接著就會依照上圖給的gradient descent更新公式去更新最後一層的W了。
計算完最後一層的W之後,我們會回推倒數第二層的hidden layer,不過這邊就會用到一大堆的微分運算跟chain rule就讓我跳過吧!XD
如果想知道的朋友請看更詳細的文章,CS231n: Convolutional Neural Networks for Visual Recognition。
那其實不是所有neural network都可以用backpropagation去解的,有些還是unsupervised的,所以下次就介紹不同種的neural network吧!


