今天這篇談談有關訓練的技巧部份
大家玩deep learning應該會碰到不少挫折,像是很難達到好的accuracy、訓練時間太久等等問題
我們今天就來講講如何用一些訓練技巧來處理這些問題
一般的Gradient descent方法是把所有資料一次做處理並且運算,但是當資料量太大的時候需要運算很久,而且收斂速度很慢。
這時候就有科學家想到,那我一次隨機從資料當中抽出一筆,根據這筆資料計算gradient,然後更新呢?
這個方法被稱為stochastic gradient descent,似乎有好那麼一點點,但是整個資料還是很大,要把整個資料跑完還是需要很多時間,如果沒有把資料都"看"過的話,就等於用了一部份的資料去訓練而已。
那如果我一次就拿一部份資料去訓練呢?這個方法稱為mini-batch,就是把資料切成若干小份,可能一個batch size會在10~100,甚至更大,取決於你的資料集大小跟你想要訓練幾個epoch,不過通常不要設太大。
Epoch就是一次的bachpropagation的流程,一次forward跟一次backward。
有可能是你的learning rate設的太大了,這樣雖然知道要往哪裡走,但是有可能會造成振盪。
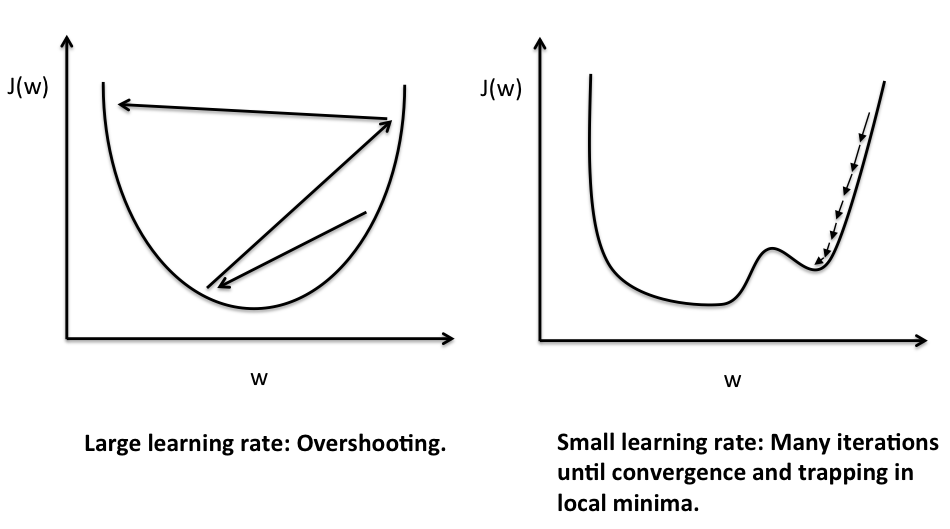
但是設太小又很花時間,每次都走很慢,怎麼辦呢?
那就讓learning rate根據不同的梯度大小調整就好了阿!讓learning rate跟梯度成正比,很陡的地方就用比較大的learning rate,比較緩的地方就用比較小的。
這種改進的演算法稱為Adaptive gradient descent,或稱Adagrad。
還有另外一種稱為RMSprop,他希望learning rate可以不只考慮當下的梯度,也參考最近幾次的梯度,所以他會將他走過的梯度拿來做平均,並且調整learning rate,大家可以看看下面的動畫就可以了解不同的學習速度囉!

取自Alec Radford's animations for optimization algorithms
在下降的過程當中有可能因為到了一個梯度接近0的地方,差一點點就可以繼續往下一個坡走了,這時候怎麼辦呢?
下降被困在這種地方真是太不科學了!乾脆引入物體的慣性(動量)到gradient descent的公式當中,所以更新的時候不是只有看梯度而已還多了慣性。
這樣改進的演算法稱為Adam,他採用了RMSprop跟momentum的方法。
這種演算法稱為Nadam,他用了RMSprop跟Nesterov momentum,不過由於這邊比較難講解,大家就可以自己google看看Nesterov momentum是什麼樣的一個東西囉!
以上這些演算法已經算很常見的了喔,各大框架都應該有。


