圖片來源:https://pixabay.com/en/books-spine-colors-pastel-1099067/ 和 https://pixabay.com/en/math-blackboard-education-classroom-1547018/
在上一篇([03]Big Data到底是有多Big?)了解到了Big Data的3個V,也就是量、增長速度和多元格式的挑戰,這篇來看看讓管理一切變得有可能的軟體:Hadoop。
這篇將介紹Hadoop的由來,為什麼這麼重要,不同版本之間的差異,和基本架構。
同步發表於我的部落格:http://blog.alantsai.net/2017/12/data-science-series-04-hadoop-intro.html (部落格的格式會漂亮一些,ithome不支援html好不方便)
hadoop的logo - 黃色大象
相信對於Hadoop這個詞應該不會陌生,畢竟Hadoop不算是新的東西,自2006誕生以來已經有11年的時間,因為Big Data的關係,多多少少都會提到它。
Hadoop的誕生是因為Google release了一份paper,裡面描述了Google內部的MapReduce(運算)和Google File System(儲存)的運作概念,然後由Doug Cutting用Java把它實作出來,並且用他兒子的 黃色大象玩具的名字命名,因此Hadoop就誕生了。
基本上,Hadoop提供了一個用串聯一般電腦來達到處理Big Data所需要的儲存和運算。
這邊,一般電腦非常重要,因為意味著不需要超級電腦就可以裝。一般來說,Scale up(把單一硬體加大)永遠是比Scale Out(平行擴展多台串聯)還要來的貴很多。
因此,當提到Big Data的時候,都會提到Hadoop,因為Hadoop讓儲存大資料量和運算大資料量變得親民。
Hadoop,有兩個重要的核心:
Hadoop Distributed File System(HDFS) - 分散式儲存資料
MapReduce - 分散式運算
基本上Hadoop有3個版本:
0.x 和1.x 版本 - 基本上應該沒人再用了
2.x 版本
3.x 版本
除了大版號的差異之外,小版本之間也是有在maintain,下面可以看到光2.x版本就有4個不同branch。
目前有在maintain的版本
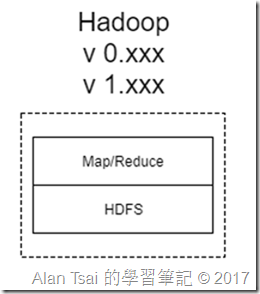
最早出來的版本基本結構如下:
0.x和1.x版本的架構
可以看到,當初只有兩個最重要的核心:
HDFS
MapReduce
其他第三方的應用,例如HIVE(hadoop上面的SQL)則需要自己處理和底層Hadoop的溝通。換句話說,假設別的套件之間要溝通,基本上做不到,或者要花很多工,因為兩者之間沒有一個共通的頻道。
還有另外一個問題是,Hadoop屬於一個Master多個Slave的架構,換句話說,當Master掛掉了,整個就掛掉了,因此有Single Point Of Failure的問題。
因此2.x出現了。
因為互相之間溝通困難的問題,因此在2.x版本多出了所謂的Yet Antoher Resource Manager (YARN)
因此架構變成了:
2.x的架構
在2.x之後,可以看到,MapReduce不直接架在HDFS上面,而是在YARN的上面,其他的軟體例如HIVE也是在YARN上面,這個時候如果兩邊需要溝通,YARN提供這個渠道。
在2.x也增加了所謂的Hig Availability和Federation的模式,避免第一版的single failure的問題。
3.x版本最近剛剛正式版release(2017/12/13),因此屬於非常新的版本。
這個版本要求JDK版本一定要在8以上,並且YARN和HDFS的部分都有做出了改變,例如本來HDFS預設會儲存3份提供可靠的Storage,這個已經改成了另外一種模式稱為Erasure Coding不止可以維持本來的容錯機制,並且需要的空間更少。
這個部分了解的不算太多,在接下來的操作也會主要focus在2.x版本,因此有興趣可以去官網看到最新的調整。
在這篇,用一個overview的方式快速介紹了Hadoop,了解了幾個重要的元素和Hadoop的幾個特色。
在下一篇要進入動手的階段(終於不是只有理論了),將會建立Ubuntu的VM並且把Hadoop架設起來,了解如何快速測試玩玩看Hadoop。
工商服務
今年的團隊機制不知不覺就集合了10位隊(坑)友 - 大家幫忙多多關注別不小心我們就gg了 XD
** 一群技術愛好者與一名物理治療師的故事 提醒著我們 千萬不要放棄治療 **
沉浸於.Net世界的後端工程師,樂於分享,現任台中Study4成員之一。除了程式以外,就愛看小說。
歡迎有任何問題或者建議都可以告訴我,可以再以下找到我:
部落格:Alan Tsai的學習筆記
我的Linkedin
我的粉絲頁
我的github
我的Slideshare
我的Twitter