圖片來源:https://pixabay.com/en/books-spine-colors-pastel-1099067/ 和 https://pixabay.com/en/math-blackboard-education-classroom-1547018/
上一篇([04]Hadoop是什麼?)以一個非常高的overview看了Hadoop是什麼,在接下來將會把理論轉成實際操作,將建立一個Ubuntu 的 VM上面架設hadoop並且跑一個MapReduce的hello world程式,WordCount(算字數)。
等到跑完範例之後,將會在深入一點看hadoop的MapReduce和HDFS運作模式。
首先,從建立環境開始。
同步發表於我的部落格:http://blog.alantsai.net/2017/12/data-science-series-05-install-and-test-hadoop-part1.html (部落格的格式會漂亮一些,ithome不支援html好不方便)
整個操作會是在VM(虛擬機器)上面執行,並且因為Hadoop在linux世界比在Windows來的穩定,因此,會建立一個Ubuntu的環境,並且把Hadoop架設在裡面。
在接下來的lab將會用到以下幾個軟體/環境:
接下來使用到的機器規格如下:
任何虛擬機器軟體都可以,只是剛好用的是VMWare Player 14。
下載頁面
檔案大小約 90MB
其他版本的Ubuntu也沒問題 - 如果用的是Ubuntu 14,那麼只有等一下安裝openjdk的部分會有問題,其他都一樣。
基本上 v2.x 的都沒有問題,只是剛好手上有2.7.4所以沒有在下載新的。如果是v3.0那麼設定會不同
這個是用來測試map reduce的hello world程式:
WordCount2.jar
jane_austen.txt - pride and prejudice 前三章 - 測試算字數用
以上就是整個會用到的程式和環境,接下來就來看看如何建立hadoop環境。
基本上整個的環境建立大概可以分幾個部分:
由於截圖比較多,所以這篇會先介紹第一步和第二部的部分,hadoop安裝和測試將會在下一篇做介紹
首先先把VMWare Player安裝起來(下載頁面)
把VMWare Player執行起來,先建立VM:
建立VM
選擇下載的Ubuntu iso檔案位置(直接下載)
選擇iso檔案的路徑
設定帳號的部分,建議設定hduser,如果設定不同,在下面的修改需要作出對應修改。
帳號設定畫面
機器的名稱和儲存位置就隨意,只要可以識別即可
VM名稱
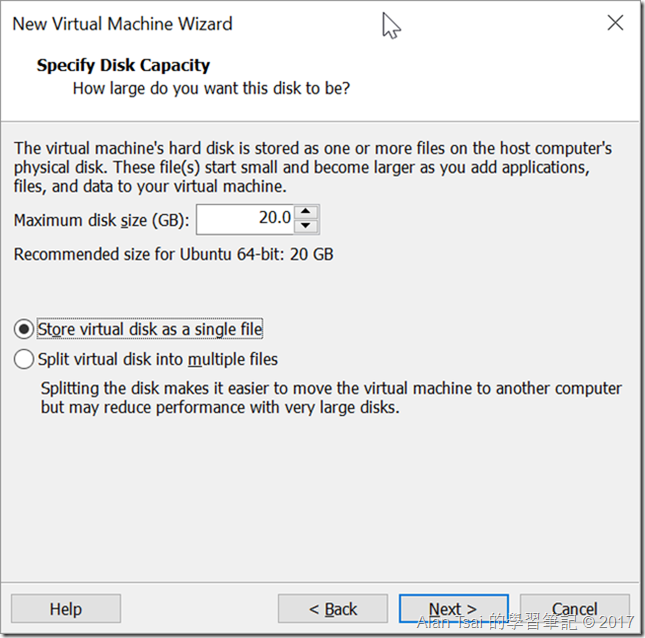
VM硬碟的部分,20GB不用動,下面那個選項建議改成第一個選項,原因是之後要複製比較方便。
設定硬碟
設定CPU和memory的部分需要透過:
最好 CPU 能夠給到 2+,Memory最好可以到4096 MB+ - 後面執行比較不會有問題(要不然需要在手動調整一些使用資源避免執行不起來)。
設定資源
接下來VMWare Player會自動安裝,如果有出現要不要安裝 VMWare Tool for linux,建議裝
安裝畫面
最後,安裝好之後,出現的就是登入畫面,直接輸入當初設定的密碼即可。
登入系統
設定Ubuntu環境
Hadoop是java的程式,因此需要先安裝Java - 正常來說Java 7就夠了,不過這邊會裝Java 8。
再來,要設定一些環境參數讓後面用到。
最後,會需要安裝ssh,因為啟動服務的時候會用ssh來溝通避免需要一台一台去啟動服務。
開啟Terminal
登入Ubuntu之後,開啟Terminal(快速鍵 Ctrl + Alt + t)。基本上後面會一直用到,所以記得這個快速鍵
更新package
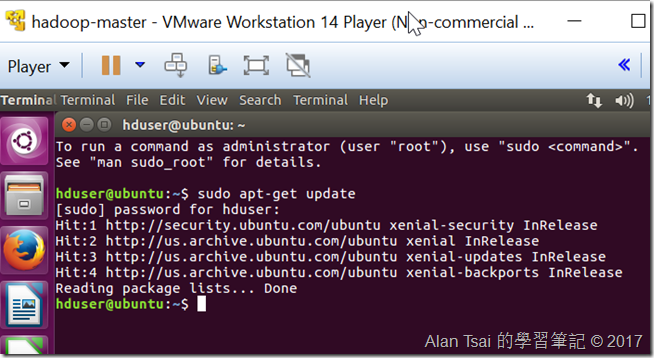
先更新目前package的情況,使用指令:sudo apt-get update
update畫面
安裝Java 8
在terminal執行:sudo apt-get install openjdk-8-jre openjdk-8-jdk
中間有需要輸入 y 才會繼續執行
設定環境參數
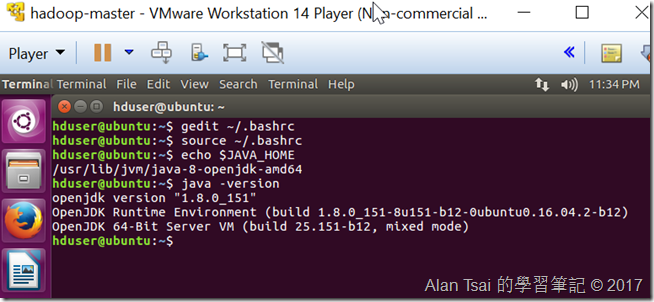
現在terminal執行:gedit ~/.bashrc,然後在檔案最後面加上:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
設定畫面
最後確認一下參數有沒有進入:
source ~/.bashrc
echo $JAVA_HOME
java -version
參數確認,並且java版本是1.8
安裝ssh server
為了能夠讓master和多個slave溝通,需要安裝ssh,再來設定ssh的key:
sudo apt-get install openssh-server
cd ~/.ssh/
su - hduser
ssh-keygen -t rsa
在產生key的部分,正常是要設定一個密碼比較安全,不過這個是測試用,所以就enter3次下去即可
產生key的畫面
key產生了之後,要把它寫出來並且測試ssh是否正常:
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
ssh localhost
exit
測試和退出的畫面
這篇介紹了建制測試環境的一些設定,由於圖片比較多因此把後半段hadoop的安裝/設定和測試放在下一篇。
工商服務
今年的團隊機制不知不覺就集合了10位隊(坑)友 - 大家幫忙多多關注別不小心我們就gg了 XD
** 一群技術愛好者與一名物理治療師的故事 提醒著我們 千萬不要放棄治療 **
沉浸於.Net世界的後端工程師,樂於分享,現任台中Study4成員之一。除了程式以外,就愛看小說。
歡迎有任何問題或者建議都可以告訴我,可以再以下找到我:
部落格:Alan Tsai的學習筆記
我的Linkedin
我的粉絲頁
我的github
我的Slideshare
我的Twitter