之前我們看到 Neural Network 在影像的辨識與解析的強大威力,接著,我們就要開始研究『自然語言處理』(Natural Language Processing, NLP),它包括文字/語音的辨識、解析與生成,實際應用範疇很廣泛,請參閱自然語言處理一文,節錄如下:
我們先來觀察一個典型的『聊天機器人』(ChatBot)流程,如下圖: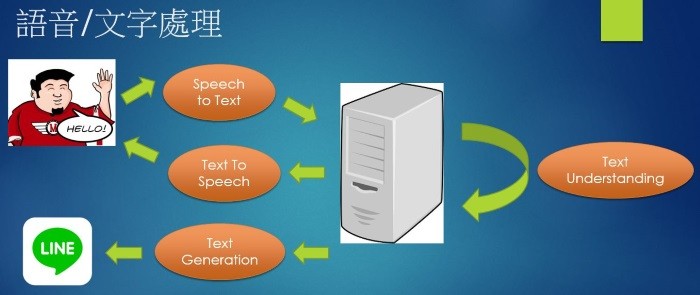
圖. 聊天機器人(ChatBot)文字/語音的解析及處理
上圖場景涵蓋的相關技術如下:
其中『 文本朗讀』(Text To Speech)技術已非常成熟,Windows平台提供 Microsoft Speech API (SAPI),Android/iOS 同樣也提供現成的函數可呼叫,其他『Text Understanding』、『Text Generation』、『Speech To Text』則有賴於AI技術的後援。
不像影像相對於點陣圖(Bitmap)的單純,人類的語言具高度曖昧性,一句話可能有多重的意思或隱喻,且隨著時代演進不斷變化,人們不斷創造新詞,語言學家越來越難建立規則(文法及語意學)來規範語文。另外,由於語文的不規則性,在放入模型解析之前,我們通常會先對輸入的語文做前置處理(Preprocess),包括:
資料清理(Data Cleaning):例如我們抓網頁資料,必須先清除 HTML 標籤(Tag),取出乾淨的本文。
標點符號(Punctuation):對語意沒有影響,通常會忽略他們。
分詞(Tokenize):英文較容易,一般以空白即可,但中文就比較困難。
Stop Words:例如英文的『the』、『as』、『to』、『from』...等介係詞或助詞,他們對語文大意的瞭解可能沒有太大的幫助,通常會忽略他們。
『詞嵌入』(Word Embedding):要交給電腦計算,將單字轉數值會比較容易處理,『詞嵌入』技術通常會將單字轉為實數,以形成連續的向量空間,比較有名的模型包括Word2Vec 及 GloVe。
相似詞整理:意義相近的單字或片語,在解析字句及分類時必須能呈現出來,Google Tomas Mikolov 創造 Word2Vec 模型,以向量(Vector)空間來定義單字(Word),就如之前介紹的『照片比對』計算Cosine,如接近1,就表示兩單字的意義相似。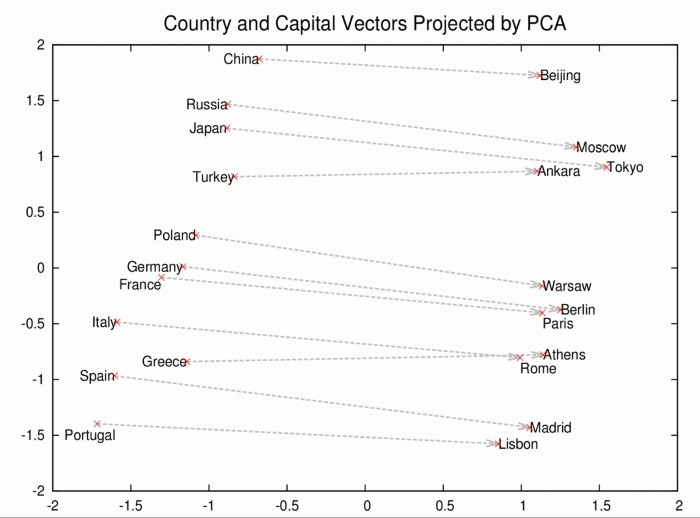
圖. Word2vec向量空間,圖片來源:Google Open Source Blog
『語料庫』(Corpus):要能訓練模型,必須要有大量的標註資料,NLTK (Natural Language Toolkit)工具箱同時提供完整的函數庫及大量的語料庫,各式的語料庫可透過下列指令下載:
安裝 NLTK 函數庫
pip install -U nltk
在DOS內輸入Python
import nltk
nltk.download()
或直接下載全部語料庫:
python -m nltk.downloader all
我們就來看幾個前置處理的程式碼。
from bs4 import BeautifulSoup
html='<h2 class="block-title">今日最新</h2>'
soup = BeautifulSoup(html, 'lxml')
soup.get_text() # 得到結果為 '今日最新'
from nltk.tokenize import word_tokenize
# 測試字句
sent = "the the the dog, dog some other words that we do not care about"
# 取出每個單字
list=[word for word in word_tokenize(sent)]
#得到結果為 ['the', 'the', 'the', 'dog', ',', 'dog', 'some', 'other', 'words', 'that', 'we', 'do', 'not', 'care', 'about']
# 去除重複,並排序
vacabulary = sorted(set(list))
#得到結果為 [',', 'about', 'care', 'do', 'dog', 'not', 'other', 'some', 'that', 'the', 'we', 'words']
# 求得每個單字的出現頻率
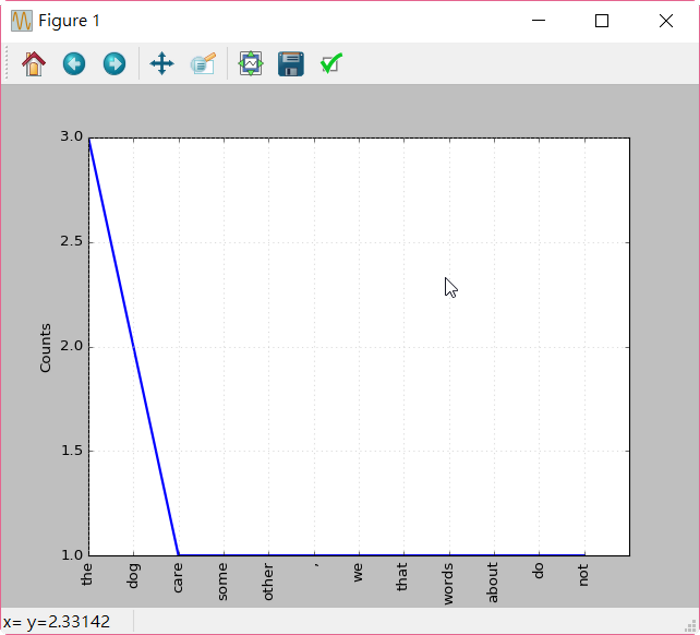
import nltk
freq = nltk.FreqDist(list)
#得到結果為 FreqDist({'the': 3, 'dog': 2, 'care': 1, 'some': 1, 'other': 1, ',': 1, 'we': 1, 'that': 1, 'words': 1, 'about': 1, ...})
# 作圖
freq.plot()
stopwords=[",","the"]
# 去除 Stop Words
list=[word for word in word_tokenize(sent) if word not in stopwords]
#得到結果為 ['dog', 'dog', 'some', 'other', 'words', 'that', 'we', 'do', 'not', 'care', 'about']
# 記得載入 WordNet 語料庫
from nltk.stem import WordNetLemmatizer
wnl = WordNetLemmatizer()
# 要指定單字詞性(pos)
print(wnl.lemmatize('ate', pos='v')) # 得到 eat
print(wnl.lemmatize('better', pos='a')) # 得到 good
print(wnl.lemmatize('dogs')) # 得到 dog
# 若要自動取得單字詞性(pos),請參考 http://www.zmonster.me/2016/01/21/lemmatization-survey.html。
雖然,利用語料庫很方便,但是還是會有點問題,例如:
'I saw two bigger dogs than this one.'
會變成
['I', 'saw', 'two', 'big', 'dog', 'than', 'this', 'one', '.']
saw 不會還原,因 saw 另一個意思是鋸的原形
'I ate two bigger cookies than this one.'
會變成
['I', 'eat', 'two', 'big', 'cooky', 'than', 'this', 'one', '.']
cookies 會還原為 cooky,而不是我們熟知的 cookie
要理解一段話,首先要從單字開始,進而到片語(Phrase)、句子(Sentence),加上文法(Syntax)、語意(Semantics)解析,我們才能理解這一段話的意義,如果要從這樣的導向(Approach)出發,我們可能要聘請語言學專家建置龐大的『規則引擎』(Rule Engine)才行,工程浩大,所費不貲,維護成本可能也是天文數字,反之,從另一種角度思考,可否與CNN一樣,改為提供大量字句,讓機器自我學習 ?
如果,我們把字句當作 input,餵入 Neural Network 模型,希望機器產生適當的回應,會有幾個問題要解決:
針對以上的語文特性,學者提出三個解決問題的演算法,分別為『循環神經網路』(Recurrent Neural Network, RNN)、長短期記憶網路(Long Short Term Memory Network, LSTM)及 GRU (Gated Recurrent Unit,查不到中文譯名),下一篇我們就一一來了解它們,並撰寫程式以及應用場域說明。



 iThome鐵人賽
iThome鐵人賽