
圖片來源:https://pixabay.com/en/books-spine-colors-pastel-1099067/ 和 https://pixabay.com/en/math-blackboard-education-classroom-1547018/
上一篇([06]建立Hadoop環境 -下篇)透過VMWare Player把Ubuntu裝好並且一些相關環境設定到,等於把hadoop的基礎環境建立好了。
這篇將延續上篇的環境,把Hadoop建立上去,並且讓Hadoop跑一個hello world的範例。
同步發表於我的部落格:http://blog.alantsai.net/2017/12/data-science-series-05-install-and-test-hadoop-part1.html (部落格的格式會漂亮一些,ithome不支援html好不方便)
整個操作會是在VM(虛擬機器)上面執行,並且因為Hadoop在linux世界比在Windows來的穩定,因此,會建立一個Ubuntu的環境,並且把Hadoop架設在裡面。
在接下來的lab將會用到以下幾個軟體/環境:
接下來使用到的機器規格如下:
任何虛擬機器軟體都可以,只是剛好用的是VMWare Player 14。
下載頁面
檔案大小約 90MB
其他版本的Ubuntu也沒問題 - 如果用的是Ubuntu 14,那麼只有等一下安裝openjdk的部分會有問題,其他都一樣。
下載頁面
直接下載(約1.4GB)
基本上 v2.x 的都沒有問題,只是剛好手上有2.7.4所以沒有在下載新的。如果是v3.0那麼設定會不同
下載頁面
直接下載(約254 MB)
這個是用來測試map reduce的hello world程式:
WordCount2.jar
jane_austen.txt - pride and prejudice 前三章 - 測試算字數用
基本上整個的環境建立大概可以分幾個部分:
這篇會介紹第三步和第四部的部分
先用firefox下載(直接下載)hadoop到Downloads資料夾
下載最後位置
在Terminal(快速鍵 Ctrl + Alt + t)裡面執行以下指令:
cd Downloads
sudo tar -zxvf ./hadoop-2.7.4.tar.gz -C /usr/local
cd /usr/local
sudo mv ./hadoop-2.7.4/ ./hadoop
sudo addgroup hadoop
sudo chown -R hduser:hadoop hadoop
這個的作用是把它解壓縮出來,放到/usr/local/hadoop的位置,並且設定執行權限
解壓縮完成看到hadoop資料夾
設定 hadoop/etc/hadoop/core-site.xml
用Terminal執行:gedit /usr/local/hadoop/etc/hadoop/core-site.xml
在 Configuration裡面輸入:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
這個是在設定NameNode位置在哪裡 - NameNode之後會介紹,但是基本上就是主控HDFS的Master。
修改core-site.xml的截圖
修改hadoop-env.sh
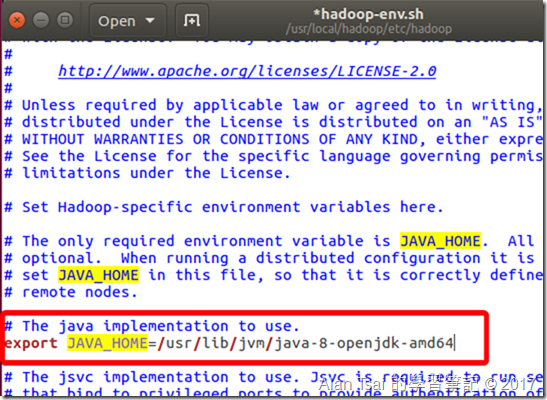
這邊要把${JAVA_HOME}的值寫進去(理論上應該不需要才對,因為我們之前有設定參數,但是好像吃不進去,所以要寫死進去)
在Terminal執行:gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到:export JAVA_HOME=${JAVA_HOME}然後把它改成export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
修改之後的結果
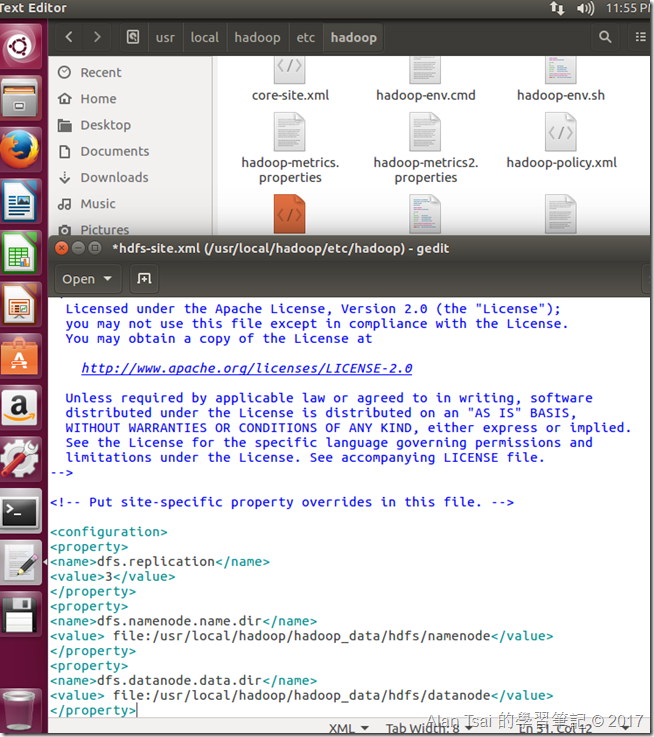
設定hdfs-site.xml
這邊設定的是:
每一個在HDFS的檔案要replicate幾份 - 預設都是3
NameNode儲存位置
DataNode儲存位置
在Terminal執行:gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml,然後在Configuration裡面加入:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value> file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property
修改畫面
修改yarn-site.xml
這邊修改的是yarn的設定,在Terminal執行gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml,在Configuration裡面加入:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
這邊後面兩個,yarn.nodemanager.resource.cpu-vcores 和 yarn.nodemanager.resource.memory-mb 是設定使用到的資源,如果後面執行不太起來要注意這個值和VM給的資源。
修改完的畫面
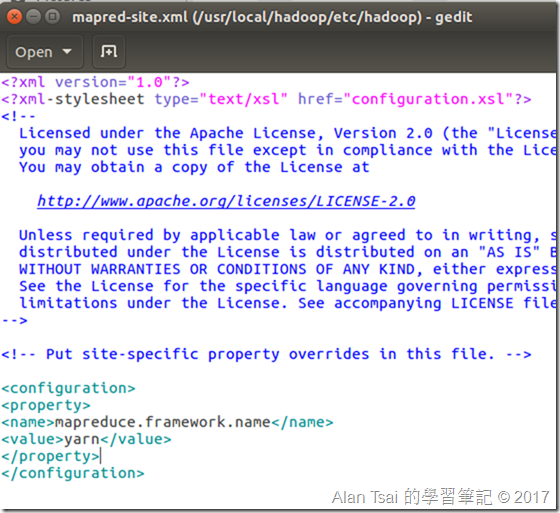
修改marped-site.xml
這個檔案預設不存在,所以要從template把它先復製出來。
在Terminal輸入:
cd /usr/local/hadoop/etc/hadoop
sudo cp mapred-site.xml.template mapred-site.xml
cd ~
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
打開了之後,把configuration改成:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
完成設定
建立HDFS用到的目錄
在Terminal輸入:
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
sudo chown -R hduser:hduser /usr/local/hadoop
這個將會建立hdfs的相關資料夾
以上就是hadoop的安裝和設定,接下來只需要把它run起來即可。
格式化HDFS
在Terminal執行:
hadoop namenode -format
hadoop datanode -format
中間可能會問是否確定繼續執行,記得要輸入yes
啟動yarn和hdfs
在Terminal輸入:
start-yarn.sh
start-dfs.sh
這個是在Master上面執行,會自動透過ssh的方式把所有Slave也一起啟動。
還有兩種啟動方式:
start-all.sh 和 stop-all.sh - 這個已經被deprecated 不過同等於上面兩個在一起執行
hadoop-daemon.sh namenode/datanode 和 yarn-deamon.sh resourcemanager - 這個是手動在各個節點裡面手動啟動對應服務
確認啟動process是否正常
在Terminal上面執行:jps
檢查執行的服務
這邊會看到5個服務:
在真的分散式架構,前3個只會在Master出現,後面兩個只會在Slave出現
服務啟動成功之後可以在Firefox輸入:
http://localhost:8088 - 這個是ResourceManager的web界面
http://localhost:50070- 這個是NameNode的web界面 - 換句話說是hdfs的畫面
ResourceManager的畫面
NameNode的畫面
執行Hadoop的Hello World - WordCount
首先先把 WordCount2.jar和jane_austen.txt下載到Downloads裡面。
下載完的畫面
把檔案複製到 hadoop的HDFS裡面,在Terminal輸入:
cd ~/Downloads
hadoop fs -mkdir -p /user/hduser/input
hadoop fs -copyFromLocal jane_austen.txt /user/hduser/input
可以用hadoop fs -ls /user/hduser/inpu檢查複製進去的檔案。
執行WordCount的程式,hadoop jar wordcount2.jar WordCount /user/hduser/input/jane_austen.txt /user/hduser/output
執行WordCount
檢查執行結果:hadoop fs -cat /user/hduser/output/part-r-00000
看到最後計算結果
如果要在執行一次計算,需要先把hdfs裡面的output砍掉,要不然會執行不了。指令是:hadoop fs -rm -r /user/hduser/output
如果執行有問題,或者run不起來,可以試試重開機,然後從測試Hadoop裡面的格式化HDFS開始重新做一次。
在這篇把整個Hadoop建立完成,並且執行了一個map reduce的word count程式計算出pride and prejudice前3章的字數計算。
在這篇建立出來的hadoop是所謂的pseudo-distributed mode,換句話說Master和Slave在同一台機器,但是實際運作上會有Master對上多個Slave。
不過在進入這種分散式模式之前,需要在了解一些hadoop細節。
在下一篇,將會在針對hadoop裡面的分散式模式在做更詳細一點介紹,包含yarn和hdfs裡面對應的process。
工商服務
今年的團隊機制不知不覺就集合了10位隊(坑)友 - 大家幫忙多多關注別不小心我們就gg了 XD
** 一群技術愛好者與一名物理治療師的故事 提醒著我們 千萬不要放棄治療 **
沉浸於.Net世界的後端工程師,樂於分享,現任台中Study4成員之一。除了程式以外,就愛看小說。
歡迎有任何問題或者建議都可以告訴我,可以再以下找到我:
部落格:Alan Tsai的學習筆記
我的Linkedin
我的粉絲頁
我的github
我的Slideshare
我的Twitter












 iThome鐵人賽
iThome鐵人賽