昨天提到的情感分析器,其運作方式大致上可以用這張圖表示
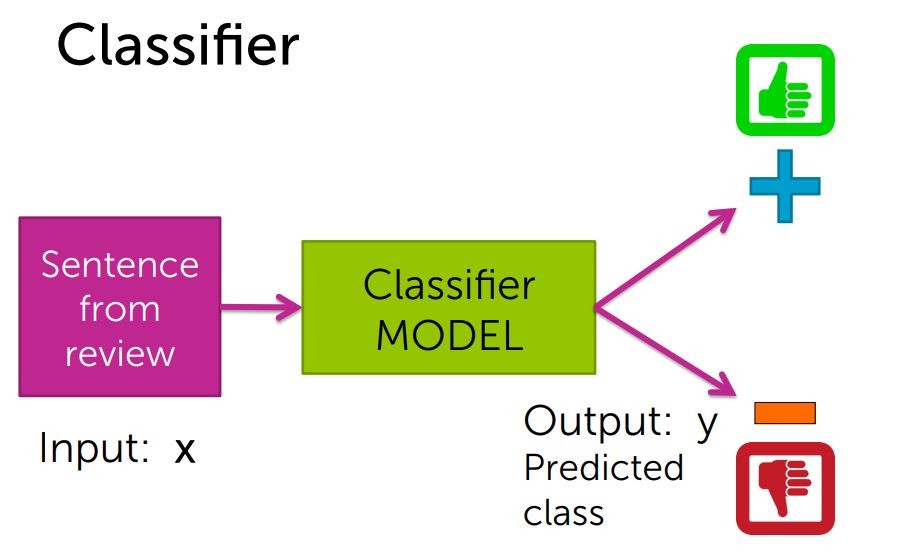
在得到輸入後經過分類最後輸出正類/負類兩種輸出結果
當然該分類模型不單單只能輸出二元的模型
還有非常多領域已經實際上應用到這個演算法的
最酷的還有他已經可以讀懂你的想法了,有一種稱為FMRI的技術,他獲得你大腦的影像,掃描你的大腦,預測你在閱讀什麼文字(此圖以Hammer與House),甚至在它分類理解之後,當你看著Hammer或House時,它也能判斷你現在望著何者
Linear classifiers 是最常見的分類器,那其classifiers mode是如何運作的呢?
在情感分析當中,想像一下一個簡單的狀況,我們有一個簡單的Threshold classifiers,分析我們的句子
input = '涼麵過譽,服務品質普通,味增湯好喝,溫泉蛋不錯吃'
List of positive words = ['不錯','好','棒','讚','驚豔','...']
List of negative words = ['普通','差','難吃','屎','過譽','...']
count positive & negative words in input:
List of positive words in inptu:
positive ++
List of negative words in input:
negative ++
if number of positive words > number of negative words:
ŷ = +
else:
ŷ = -
這時候就會碰到一些問題了
-字詞該從那裏取得?
-字詞該怎麼分配權重?(好、棒、讚,那一個好?難吃、屎、過譽,那一個壞?)
-單一個字詞沒辦法分類,像是好吃跟不好吃,其實差了一個字,但評價完全是相反的
第三個問題比較困難,會留到後面在解決
我們來看看在Linear classifiers,是怎麼運作的
它會將每一個word加入權值,並且排除無關的字詞
| Word | Weight |
|---|---|
| 驚豔 | 2.5 |
| 好 | 1.5 |
| 讚、棒 | 1 |
| 不錯 | 0.5 |
| 普通 | -1 |
| 差 | -2.1 |
| 過譽 | -3 |
| 難吃 | -3.5 |
| 屎 | -5 |
| 其他詞語 | 0.0 |
input = '涼麵過譽,服務品質普通,味增湯好喝,溫泉蛋不錯吃'
socre(x) = (-3) + (-1) + (1.5) + (0.5) = -2
if score(x) > 0
ŷ = +
esle score(x) <= 0
ŷ = -
這門課還是有一些Python的作業,但為了不耽誤發文的時程,所以我的打算是每天我還是會持續聽課,然後更新筆記
作業的部分利用周末六日來寫,所以作業的章節會跟上課的筆記不連貫
如果造成閱讀不便請見諒:D


