classifiers 做出分類,分辨那些句子是積極或消極
讓我們接著看classifiers是怎樣透過特地的Linear classifiers的原因
來做決策的
用一個簡單的例子,假設你只有兩個權值不為0的單詞(awesome:1.0/awful:-1.5)
在這種狀況之下,Score(x)就是由 1 * awesome - 1.5 * awful
接著假設有個評論這樣寫著 the sushi was awesome, the food was awesome, but the service was awful
我們可以畫出座標軸,再帶入公式,畫出它位於座標軸上的位置
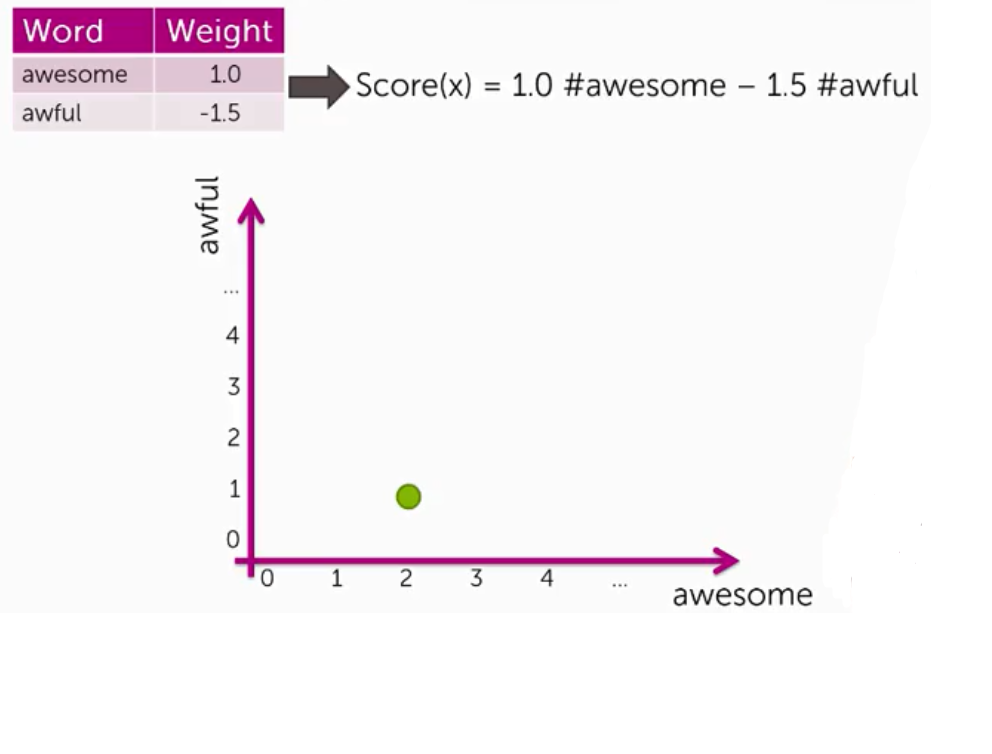
然後收集完所有的評論,並將之繪出,我們把Score(x) < 0 的標示為 '-' 反之亦然
但事實上,真正把+/-切開的,就是Score(x) = 0 的狀況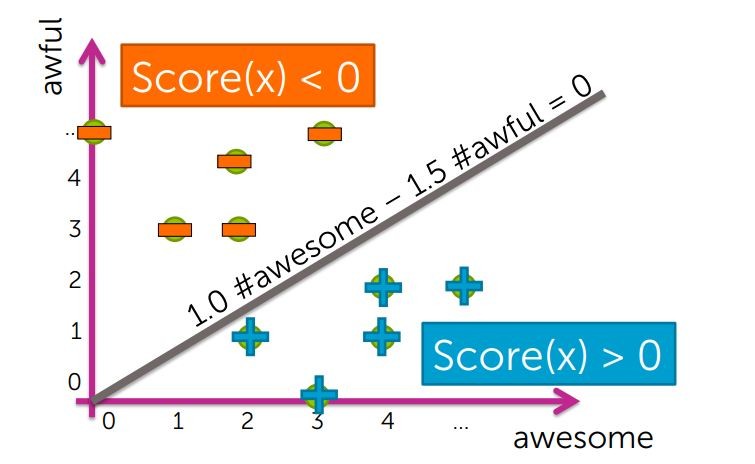
這個例子中的Decision boundaries是一條線,這就是我們稱它為Linear classifiers的原因
在回歸模型中,我們透過擬合一個回歸模型預測房價並用誤差平方何來測量模型的誤差
那在分類問題中,我們的誤差該如何判讀呢?
想像一下,我們一開始會有一個classifier,我們透過一組資料,而這些資料就是所有關於食物的評論,這些評論涵蓋了正反兩面的情緒,同樣的我們將這些評論分為訓練集與測試集
透過訓練集來訓練classifier,它會透過演算法來學習每個字的權重
接下來這些權重將被測試集裡的句子打分數,所以我們透過測試集來評估我們分類效果的好壞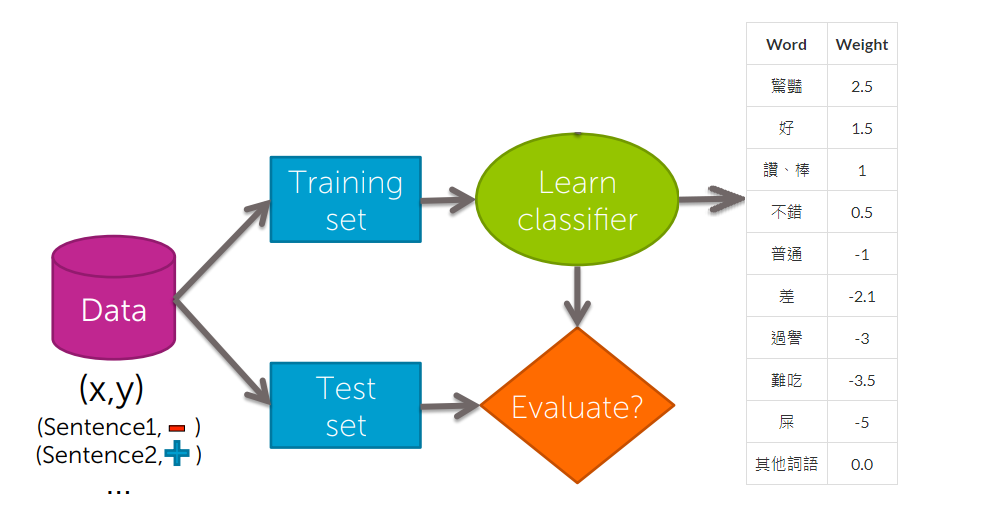
我們接著看,它是如何做評估的?
我們會從測試集中輸出一段句子,例如:味增湯好喝,這是一個正面的評價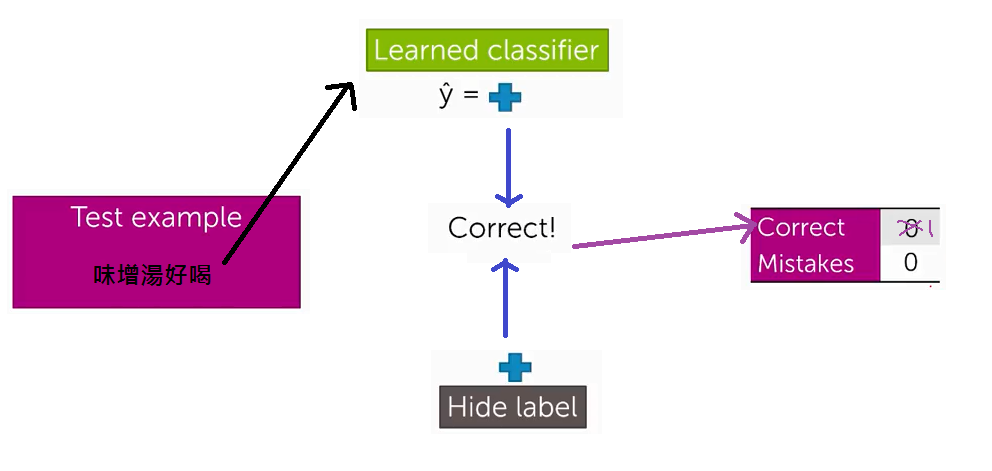
我們將句子交給classifier,但是我們把正面的標籤隱藏起來,最後比較classifier分析後的評價
如果正確則correct的值加一,而同樣的如果它判斷錯則mistake加一
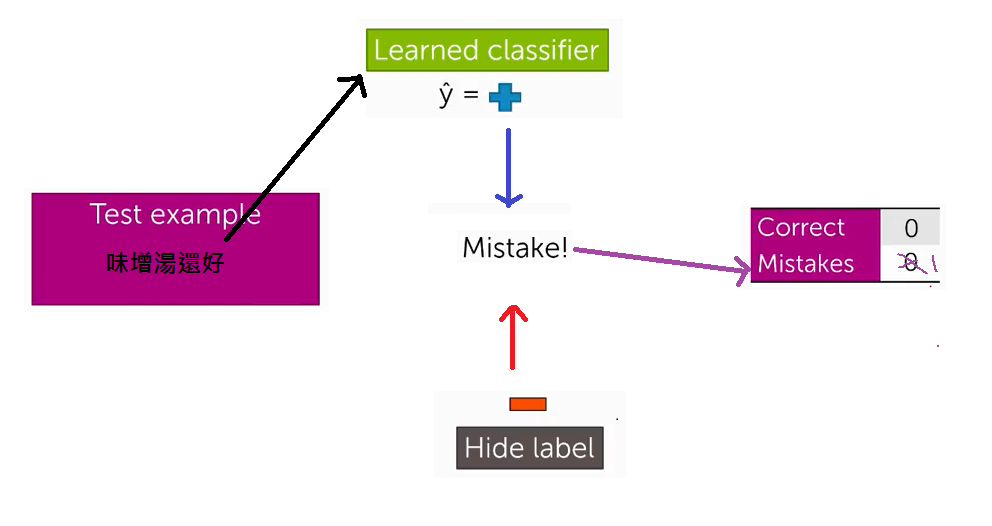
當我們把所有測試集的句子都跑過一次之後有兩種最常的量測分類效果的方法
我們從前面的誤差率或正確率來判斷一個classifier的優劣,那現實中真的存在好的誤差率/正確率?
我的意思是說,當你問我這個classifier到底有多好時?我該用何種判準來回答呢?
直覺上最先拿來比較的就是隨機猜測
但是比隨機猜測好就夠了嗎?到底要到什麼樣的程度才是有意義的?
假設有一個E-mail預測器,它的正確率約為90%,那這個實作有意義嗎?

因此要確認自己的實作是有意義的


