透過前兩篇, 我們了解了機器學習模型的兩個極端範例Under fitting與 Overfitting, 而Under fitting可以增加項次或是增加Feature即加入更多的資料來解決, 那麼Overfitting解決方式呢? 以林教授說法, 模型做得太好, 要對它懲罰跟踩煞車, 那這又是甚麼意思呢, 以底下四次方式子的來說
y=b0+b1X +b2X^2 + b3X^3 + b4X^4
懲罰就是要想辦法調整b1, b2, b3等係數, 踩煞車就是Regularization即在方程式後面加入一個函數, 以參數的方式做調整, 方程式概念如下
y=b0+b1X +b2X^2 + b3X^3 + b4X^4 + Regularization函數
關於Regularization, Andrew Ng與林軒田教授的課, 講解得非常清楚, 這邊就不贊述, 有興趣可以直接參考, 接下來看看實際的案例長甚麼樣子, 我們修改day06程式如下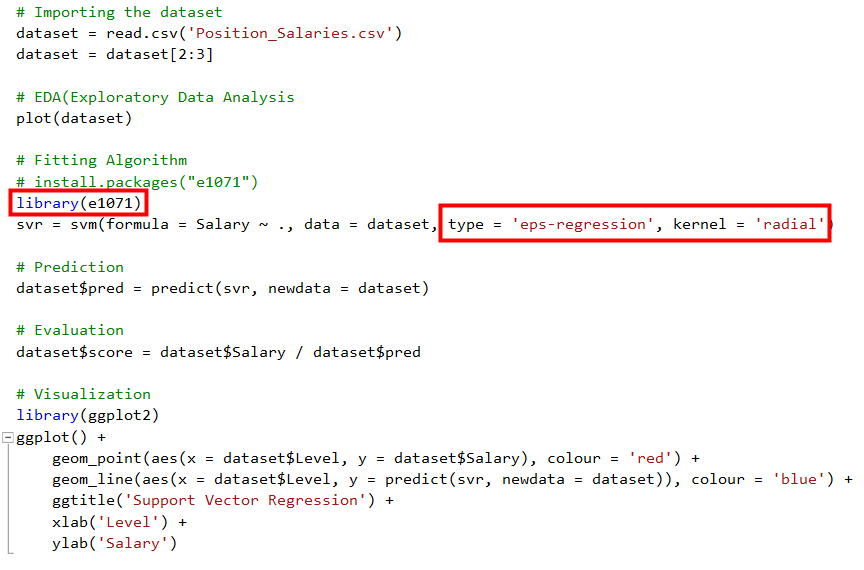
這邊用的是e1071套件, 特別一提的是這個是由台大林智仁教授所開源出來的libsvm ( https://www.csie.ntu.edu.tw/~cjlin/libsvm/ ), 也有Python與Java的版本, 而R的e1071套件則是libsvm的wrapper,讓我們可以直接透過e1071讓libsvm的核心幫我們算出SVM的模型, 另外這邊有兩個參數type與kernel要注意一下, 可以透過F1查找svm的使用方式, type的說明如下,因為薪資的這個範例是regression的類型, 所以這邊採用的是eps-regreesion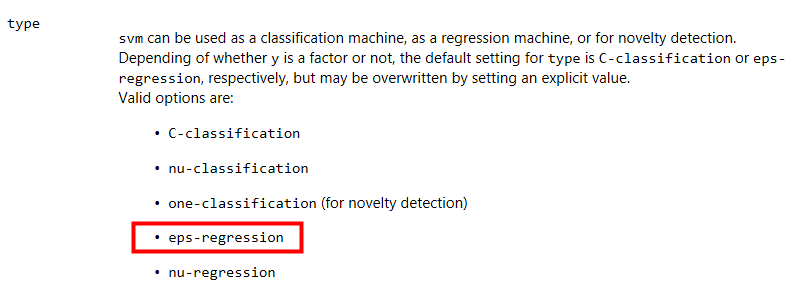
Kernel的說明如下, 這邊選擇的是radial basis即Gaussian kernel, 至於這些Kernel的說明可以參照Andrew Ng與林軒田教授的課程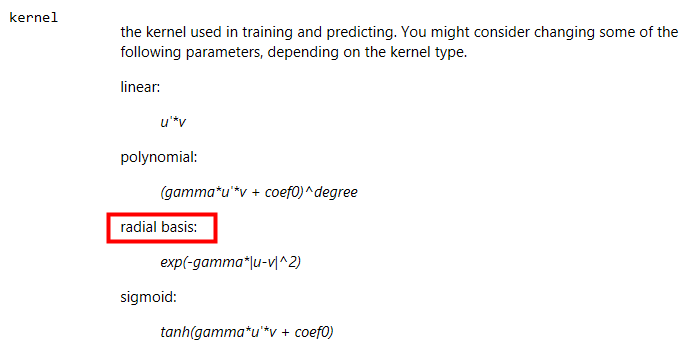
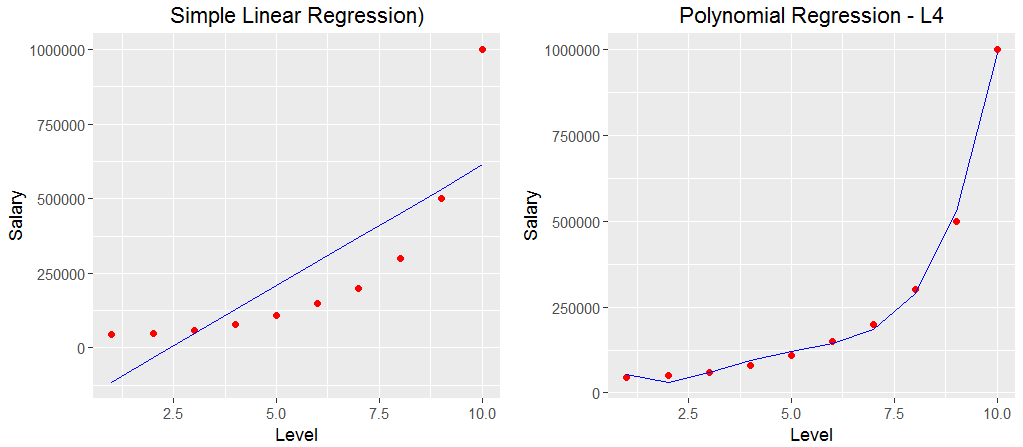
如同前兩篇一樣, 把視覺化結果叫出來看一下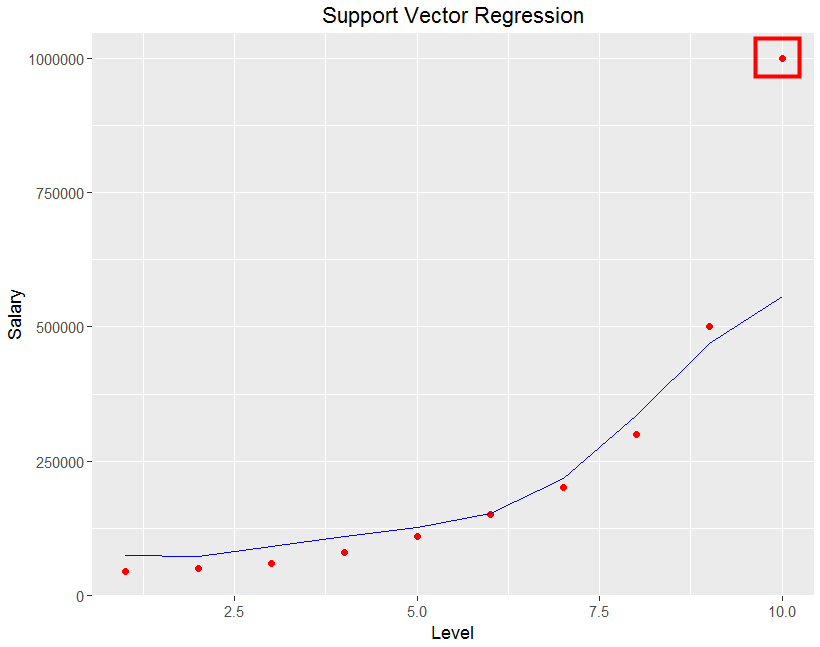
而上圖可以發現, 幾乎所有的點, 都靠近這條曲線, 只有Level 10的點,離這條線非常遠, 這就是在機器學習中, 我們希望模型可以做得好, 又不要做得太好, 因為做得不好就是Under fitting, 做得太好就是Overfitting, 而SVM排除了Level 10這個資料的Outlier(異常值), 就是為了避免做得太好, SVM是個好用的演算法, 裡面還有參數來控制Regularization,對於機器學習來說, SVM絕對是必學的演算法, 此時耳邊又想起田神說的那個胖胖的邊界(Soft Margin)
回到HR主管的需求與核薪表, 預測面試人員所要求的薪資與職位是否合乎預期?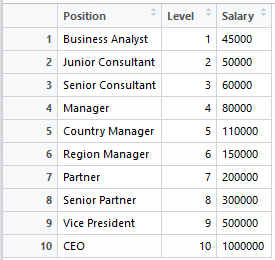
假若今天有人想來應徵Senior Consultant的職位, 期望薪資為165,000, 用人單位主管與HR主管審核履歷與面談後, 覺得該面試人員應該有介於Region Manager與Partner, 假定Level =6.5, 此時我們用SVM做出來的模型來做預測,程式碼與結果如下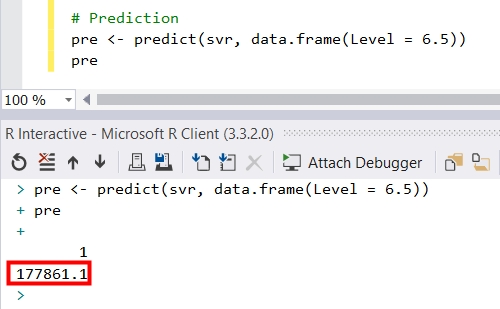
算出來為177,861, 結果就是錄取此人囉, 不過HR主管又提了個需求, 希望有個Web, 可以做為輸入介面與呈現預測結果, 在後面文章會有幾篇介紹R與Web的互動, 來完成這個需求


