有關購買紀錄分析的系列文差不多接近尾聲,最後我想介紹的是Apriori 演算法,這演算法最常被用在分析校費者如果買了A 商品後會再去買B 商品的可能性分析,最經典就是「啤酒與尿布」問題,常見的應用像是新聞網站會有一區會像是「讀了這篇文章的人也讀了XXX」、我是電商網站「買了這樣商品的人同時也購買了OOO」等...
不過要再使用分析之前,我們必須先把資料變成可以套入演算法的格式,要套入本章介紹的演算法之前,你的資料結構必須長得像這樣。
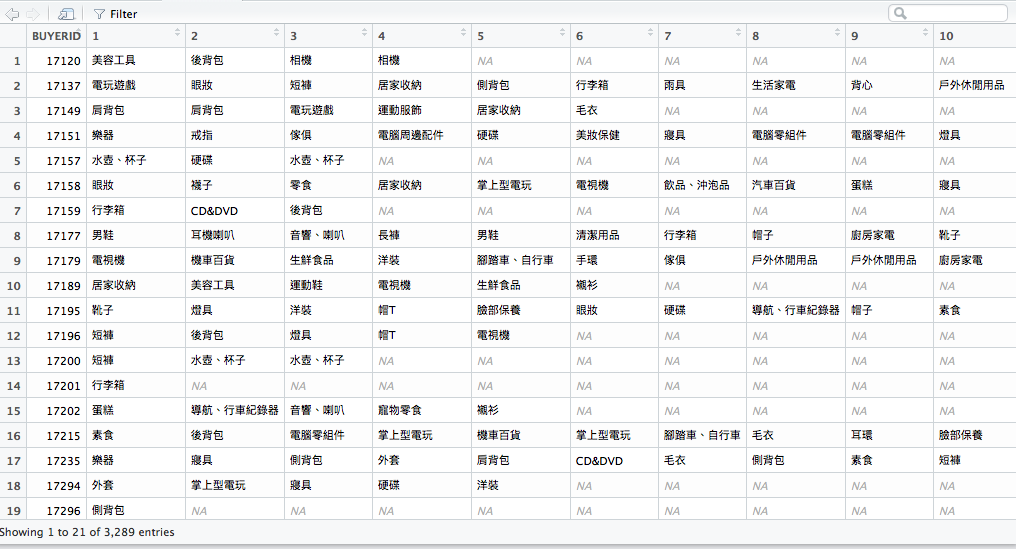
有了前幾天的練習,要把資料變成這種格式並不難,讓我們一步一步來複習。
首先,我們要把使用者和購買的品項分類
result <- orders %>%
separate(NAME, c("Category", "Brand"), sep="\\(") %>%
distinct(BUYERID, Category)
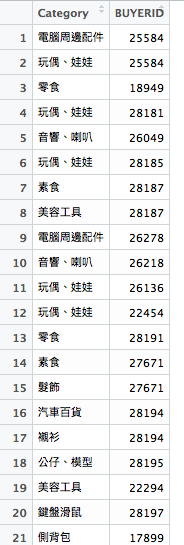
再來,我們又把某使用者購買過的商品變成一欄一欄的紀錄,這邊第一個會想到什麼辦法?答案是spread(),不過在開始之前我們必須先將每筆資料標上編號,所以用mutate() 加欄位,這邊可以用row_number()取得index。
result <- orders %>%
separate(NAME, c("Category", "Brand"), sep="\\(") %>%
distinct(BUYERID, Category) %>%
group_by(BUYERID) %>%
mutate(row = row_number())
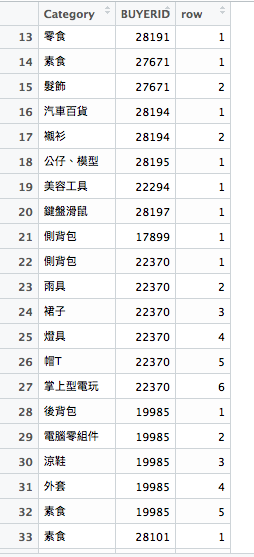
現在既然有了row index,就可以使用spread()切平資料囉!
result <- orders %>%
separate(NAME, c("Category", "Brand"), sep="\\(") %>%
distinct(BUYERID, Category) %>%
group_by(BUYERID) %>%
mutate(row = row_number()) %>%
spread(row, Category)
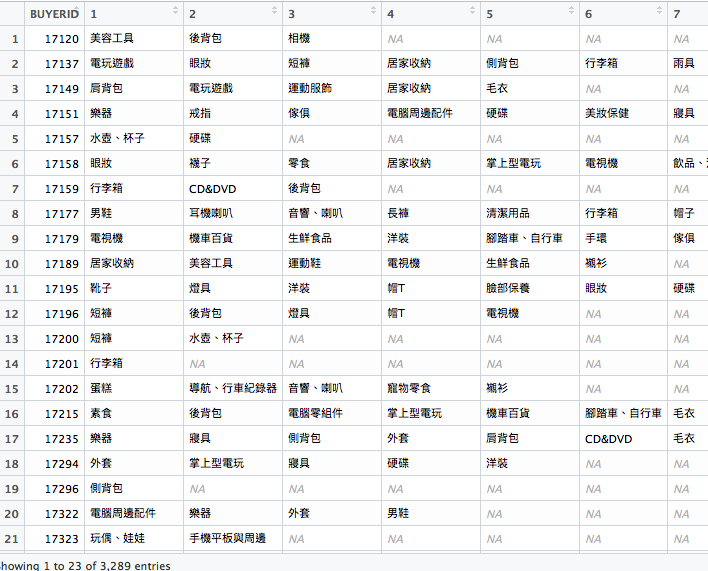
再來,我們不需要BUYERID,所以可以在用select() 來去除,不過由於一開始已經先group_by() 了,所以這邊要再使用ungroup() 處理,然後我在用filter_at()去除第二個欄位為NA的資料,畢竟只有買過單樣商品的人不需要分析嘛!
result <- orders %>%
separate(NAME, c("Category", "Brand"), sep="\\(") %>%
distinct(BUYERID, Category) %>%
group_by(BUYERID) %>%
mutate(row = row_number()) %>%
spread(row, Category) %>%
ungroup() %>%
select(-BUYERID) %>%
filter_at(2, all_vars(!is.na(.)))
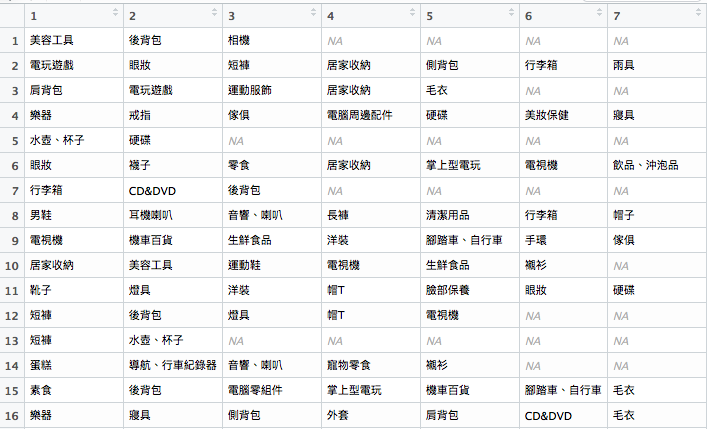
這個地方我們就先把資料匯出至output資料夾,至於該如何分析我會放在下一篇介紹!
write.table(result, file="output/apriori.csv", sep = ",", na = "", row.names=FALSE, col.names = FALSE)
ref:
day9原始碼



 iThome鐵人賽
iThome鐵人賽