沒錯,前一天的教學還只是清理資料而已,真正的分析還沒開始,我們這邊會用到Apriori 演算法,那這邊有幾個名詞要先介紹
Support (支持度) : 意思是某特定種類在所有種類的比重,例如我有100名會員,其中有20名購買過雨具,則support(雨具) = 20% 。
Confidence (信賴度) : 意思是某A種類中,含有某B種類的比重,例如我有100名會員,其中40人買過涼鞋,而這40買過涼鞋者當中,又另有10人買過雨具,則confidence(涼鞋->雨具) = 10/40 = 25% 。
Lift (提升度) : 意思為某兩者關係的比值,如果小於1 代表兩者是負相關,等於1 表示兩者獨立,大於1 表示兩者正相關,公式為confidence(A->B) / support(B) ,帶入上述例子可表示成 lift(涼鞋->雨具) = 25/20 = 1.25 。
介紹完Apriori 的幾個名詞後,就可以啟動R 的套件。
#install.packages("arules")
library(arules)
然後讀取昨天整理好的資料。
dataset = read.transactions('output/apriori.csv', sep = ',', rm.duplicates = TRUE)
我們就會看到初始化訊息。
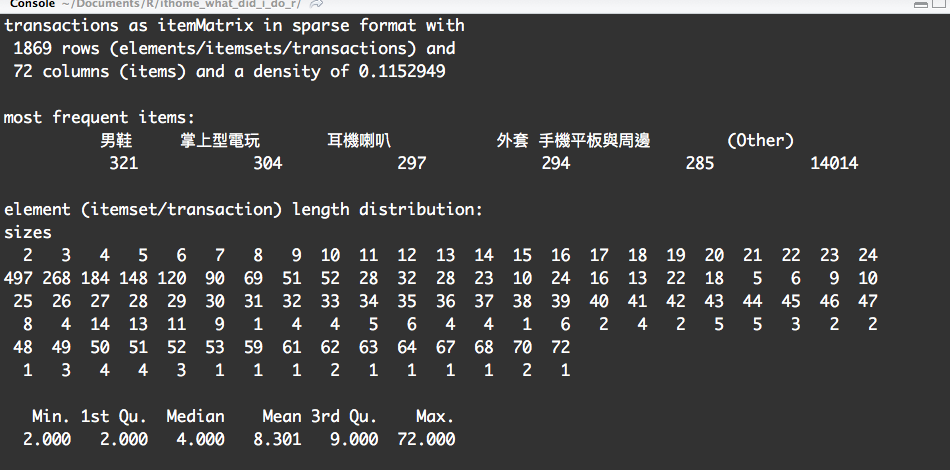
這邊簡單解讀,我們分析1869 筆資料,種共有72 種商品品項,其中最常出現的是男鞋,共出現了321 次,而各個會員中,曾經購買過2種品項者有497名、購買3種品項者268名,有一位使用者是超級購物狂72種品項都改過。
再來我們將各個品項的比重畫出他的支持度。
itemFrequencyPlot(dataset, topN = 72, names = FALSE, support = 0.01)
topN 設72,就是所有品項,names設為FALSE,避免圖表化出時,底下全部一堆字擠再一起,support設0.01代表如果該品項的支持度不到1%則不畫,然後我們就得到了下圖。
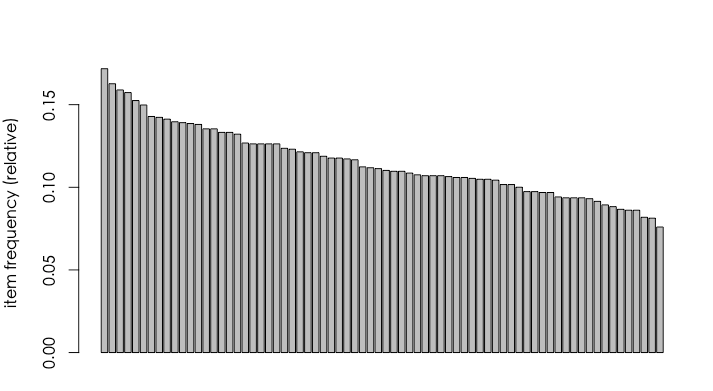
這邊可以看到最高support 的品項在15%左右,最低在8%附近,當然,我自己事後再分析時,發現我當初產生的測資有點太平均了,所以我之後的分析結果會有些缺發說服力,如果你自己的資料分析出來後support 分不差異比較大的,那麼恭喜你理論上會挖到比較有價值的資訊。
接著我丟給apriori 演算法去尋找規則,限制它這個組合支持度至少要高於5%,信賴度大於10%,最少要有2種品項。
rules = apriori(data = dataset, parameter = list(support = 0.05, confidence = 0.1, minlen=2))
最後演算法找到了42項規則,於是我們將它根據lift 高低印出前10筆。
inspect(sort(rules, by = 'lift')[1:10])
得到以下結果:
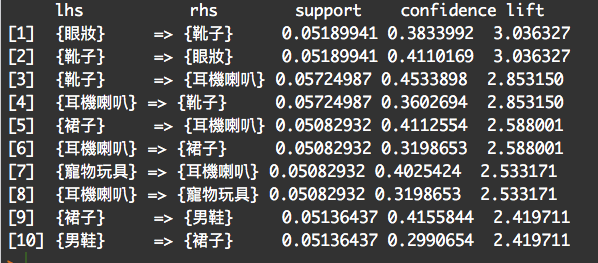
我們就拿第一筆:眼妝=> 靴子來看,這兩者品項同時出現佔所有商品品項5%,有買過眼妝的人中,有買過靴子的人佔了38%,買了眼妝的人也會買靴子的lift 為3.04。
以上就是Apriori 演算法,如果有什麼地方我敘述不清的,還請大家給點指教!
ref:
day10原始碼
您好:
看完您的文章覺得收穫很多,想請教解讀規則方面的問題
以第2、3個規則來說:
買了靴子再買眼妝的提升度為3,買了靴子再買耳機喇叭的提升度為2.8,再lhs項都相同的情況下,提升度是可以做比較的嗎?
比方說:買靴子再買眼妝因提升度較高,所以店員應以推薦此商品為主(只看提升度的狀況下)
可以,若以提升度為考量,我會這樣做結論。
了解,非常感謝您~
您好,
我遇到如圖片中的問題,執行了指令 dataset=read.transactions(.... 但結果並沒有如您文章出現 “我們就會看到初始化訊息。” , 而是出現 There were 50 or more warning (use warning() to see the first 50)
希望可以得到解答,是不是有可能哪裡漏掉了等等的問題。
感謝您~
請問你資料夾中確實有output/aprior.csv 這個檔案嗎?
dataset <- read.transactions('D:/output/apriori.csv', sep = ',',quote = "",rm.duplicates = TRUE)
summary(dataset)
加入quote=""就好了~同上;可能是R的版本不一樣才會有此差異


