
在上一篇中, 我們很快出做出模型, 不管三七二十一把所有資料丟進去跑, 但是CEO的接下問題是哪幾項的資料才是關鍵呢? 找出重要的資料,在機器學習中有個專有名詞稱作Feature Selection(特徵選擇), 這項工作也是至關重要, Feature Selection做得好, 可以節省模型的運算時間, 提高模型的正確率等, 也有專門的書來討論這個議題
舉筆者最愛的資料集 IRIS(鳶尾花卉數據集)
https://zh.wikipedia.org/wiki/%E5%AE%89%E5%BE%B7%E6%A3%AE%E9%B8%A2%E5%B0%BE%E8%8A%B1%E5%8D%89%E6%95%B0%E6%8D%AE%E9%9B%86
僅以150筆資料, 可以準確預測鳶尾花的種類, 而原因無他, IRIS裡的花萼和花瓣的長度和寬度為其重要特徵, 接下來看一下用上一篇的範例如何實作Feature Selection?
先在EDA步驟裡, 看一下資料的相互關係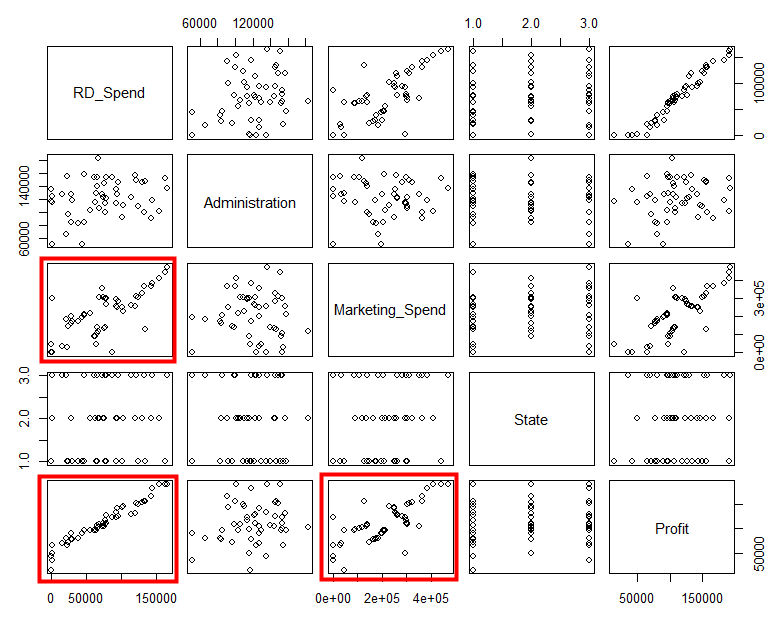
由上圖可以發現RD_Spend與Profit有強烈的相關性, 但Marketing_Spend與Profit, 似乎有相關, 但相較於RD_Spend與Profit, 就沒那麼強烈, 而RD_Spend與Marketing_Spend看起來似乎有點相關, 接下用summary()把模型的一些資訊叫出來看一下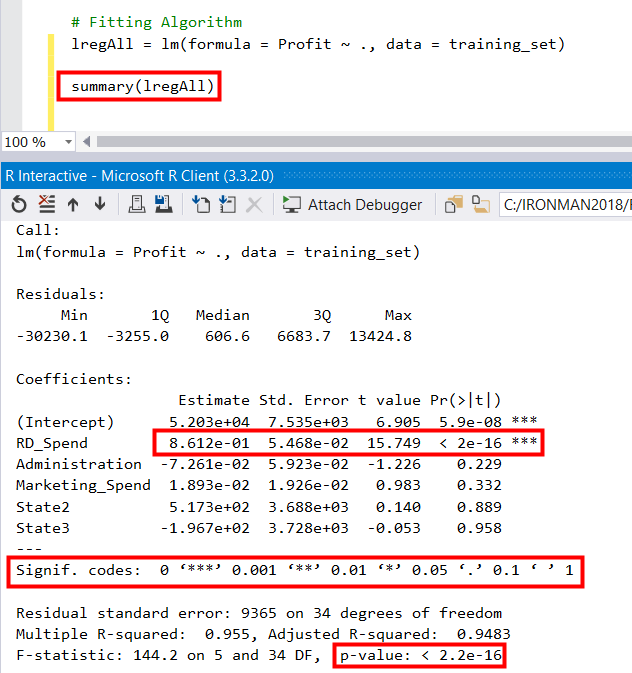
這些裡面包含了蠻多的統計名詞, 不了解可以翻一下統計的書籍, 這邊只針對筆者覺得重要的部分說明, 首先要來了解一下p value, 它是一種"無單位"的"通用"指標用來衡量某個虛無假設(null hypothesis)的顯著性而p值的"比較對象" 是顯著水準(significance level), 所以顯著水準就是上圖第二紅框,即
Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1
而且R很貼心的把顯著水準的高低用 * 表示, * * * 代表顯著水準高, 所以一眼馬上看出RD_Spend有 * * * 即代表它顯著, 為重要特徵, 而Marketing_Spend與Administration則是沒那麼顯著, State2與State3, 則更不用說, 接近1代表根本可以排除這個特徵, 不過這邊有人應該會好奇, 不是只有State嗎?為什麼跑出State2與State3, 還記得State利用factor()轉成categorical data, 在R裡會自動將categorical data轉成所謂的Dummy Variable(虛擬變數), 可參考底下這篇的解釋何謂Dummy Variable?
http://belleaya.pixnet.net/blog/post/30877354-%5B%E6%95%99%E5%AD%B8%5D-%5B%E7%B5%B1%E8%A8%88%5D-%E8%99%9B%E6%93%AC%E8%AE%8A%E6%95%B8-dummy-variable
所以根據上述的Inferential Statistics(推論性統計)來推論, RD_Spend是最影響Profit的特徵, Marketing_Spend與Administration則是只有一點點的影響, 寫到這, 結論已經出來了, 但是有沒有辦法來驗證我們的推論呢? 畢竟眼見為憑, 嘴砲無用啊! 其實我們可以上一篇用的cor()這個函數, 比較不同模型間, 實際與預測的相關係數來驗證, 修改上一篇的程式碼如下
跑所有資料的模型結果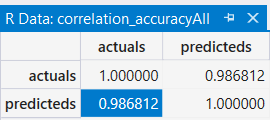
只跑RD_Spend的模型結果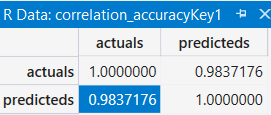
只跑RD_Spend, Marketing_Spend與Administration的模型結果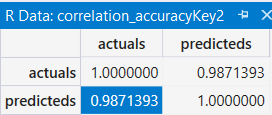
根據上面三個表格的比較, 可以發現只跑RD_Spend, Marketing_Spend與Administration的模型是比所有資料的模型來的優, 這也呼應day01所提的, 大家用的Library都一樣, 為什麼有的人做出來的模型就是比較準, 眉角在這啊! Feature Selection不可不慎~
所以可以有信心回答CEO的問題了, 而且還可以加以佐證, 不會被問倒而GG了
記錄完自己在RTVS實作機器學習的心得, 接下來回到本傳, 下一篇來介紹Microsoft R Client

