分群這個概念除了出現在資料分析以外,在機器學習領域也有相當多應用,簡單地解釋就是把一個未知的資料根據它的特性分成一個個的群組,這邊我想介紹的是K-means ,它的概念很簡單,首先你先設定k 數,然後就會有隨機k 個點散佈在資料中,然後中間會不斷地打散重新分配中心點,直到收斂為止。
第一,我們先把前一天的資料用address_LatLng_data 存下來。
address_LatLng_data <- result #將前一天的資料存到address_LatLng_data
然後因為每次K-means 都是隨機分配,為了讓我們練習的結果一樣,我必須先設定種子碼,就設定今天日期好了,接著我指定k 的數量為10,就能程式下去算。
set.seed(20180102)
kmeans = kmeans(x = address_LatLng_data[, c('Lat','Lng')], centers = 10)
y_kmeans = kmeans$cluster
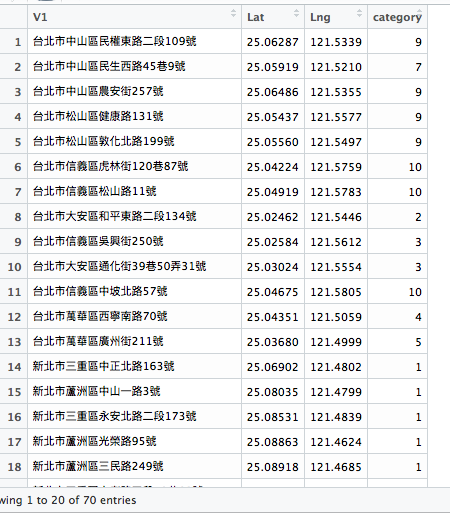
可以得到這70個地址的分類分別如下

然後將y_kmeans 整合到dataframe。
result <- address_LatLng_data %>%
ungroup() %>%
mutate(category = y_kmeans)
用表格表示很沒有感覺?那就畫在地圖上吧!
ggmap(get_googlemap(center=c(121.52311,25.04126), zoom=12, maptype='satellite'), extent='device') +
geom_point(data=result,
size=1.8,
aes(x=Lng, y=Lat, colour=factor(category)))
最後結果:
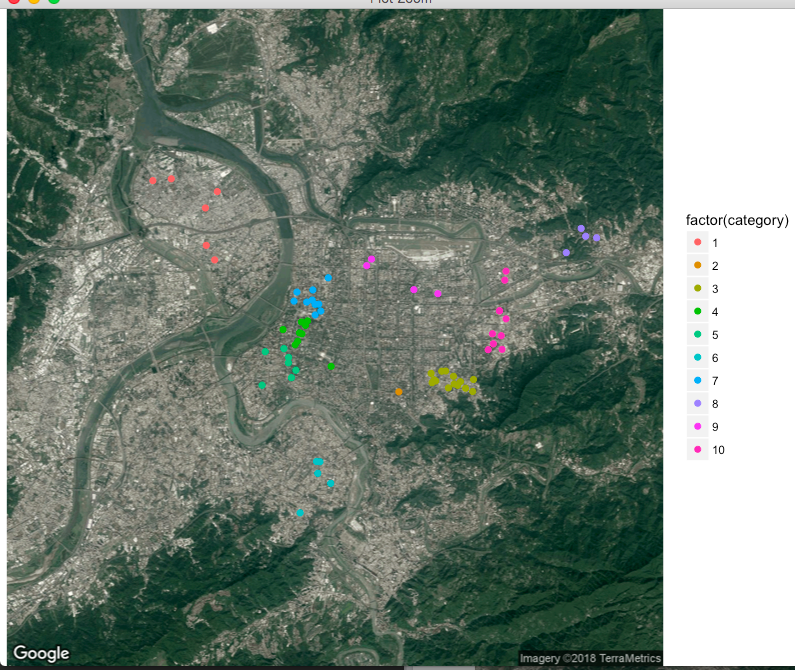
從地圖上可以看出所有的地址被分成10類了!!
ref:
day16原始碼



 iThome鐵人賽
iThome鐵人賽