SMACK簡單的說就是由Spark、Mesos、Akka、Cassandra和Kafka這5項新興大資料技術組合成的SMACK架構。以前我在研究所時期,同學剛好研究的是Hadoop,所以有大概了解他主要在做什麼的,而Spark也大約是那個時間有聽到,更特別的是Spark比Hadoop更為強大的分散式運算Engine。他將資料存在記憶體中來重覆運算來藉此提升效能。更細節的部分,我也在之後的各篇中做個簡單的說明。
現在我們知道了Spark是運算的引擎,那其它四個技術分別又代表了什麼呢?先從Mesos說起,他是主要是服責叢集資源的管理,是分散式系統的核心,其實等同於Hadoop中Yarn的角色,細節的區別我也不清楚,但是還是有很多的人是持續使用Hadoop中的Yarn和HDFS技術,提到HDFS,簡單的說就是分散式的File System的概念,這個角色等同於SMACK的Cassandra的角色,目的就是資料儲存的作用。
Akka則是以Scala語言寫出的Actor模型庫,可用來建構一個能在JVM上執行的高同步、分散式、能自動容錯,並以彈性訊息驅動的應用。Kafka是一套分散式訊息提交系統,可以預先將進來的資料集合起來。(資料來源)[https://www.ithome.com.tw/news/102426]
這二個的角色,一開始來看,其實沒有很容易了解。下面用一張圖來說明。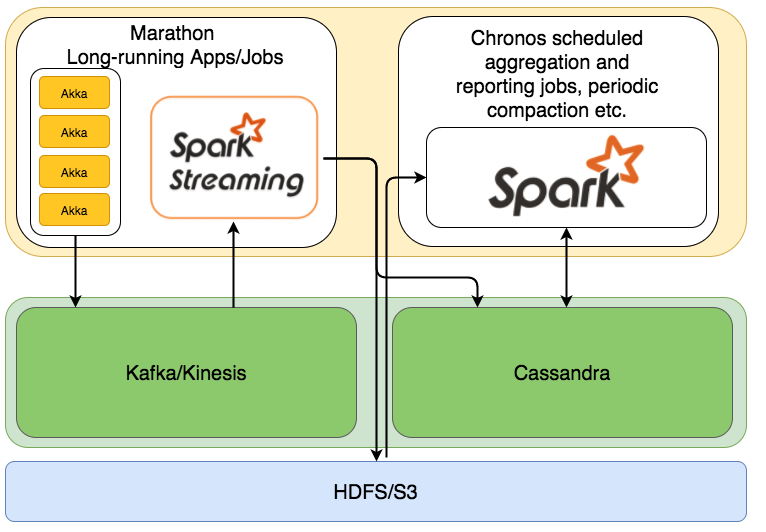
首先akka是比較像是資料收集的角色,讓我們可以大量從前端接受資料,Kafka是有點拿來當暫存的角色,當Spark的運算核心掛了,或是來不及處理的時候,能暫時存放資料,而Spark就是資料處理的角色,但,其實Spark會分成批次和是即時處理的部分,而Spark的資料來源可能是Kafka或是Cassendra,Cassandra可以當成是資料庫角色

