本文將探討titanic資料中各欄位的資料尺度,並且校正不恰當的資料類型。
#匯入maplotlib做視覺化
import matplotlib.pyplot as plt
#讀取資料
data = pd.read_csv('data/train.csv')
我們可以透過Dataframe的describe方法,讓我們觀看各資料欄位的描述統計。描述統計可以幫助我們對觀測(observation)有初步的了解,通過給定該方法"include='all'"的參數才能看到所有欄位的描述統計,否則預設僅顯示資料類型為數字型的欄位。
| 敘述名稱 | 含意 |
|---|---|
| count | 欄位非虛值資料的計數 |
| unique | 共有多少值(不重複) |
| top | 出現最多的值 |
| freq | 值出現的頻率 |
| mean | 算術平均數 |
| std | 標準差 |
| min | 最小值 |
| 25% | 落在下四分位數的值的總計 |
| 50% | 落在中位數的值的總計 |
| 75% | 落在上四分位數的值的總計 |
| max | 最大值 |
上述的統計描述中,unique/top/freq此三項是針對非數字類型資料的統計描述,而mean/std/25%/50%/75%/max這些欄位針對數字型資料。因此只要是屬於非數字的類型如object/category,都不會有針對數字型的統計敘述,反之亦然。
先看看titanic的統計敘述:
data.describe(include='all')
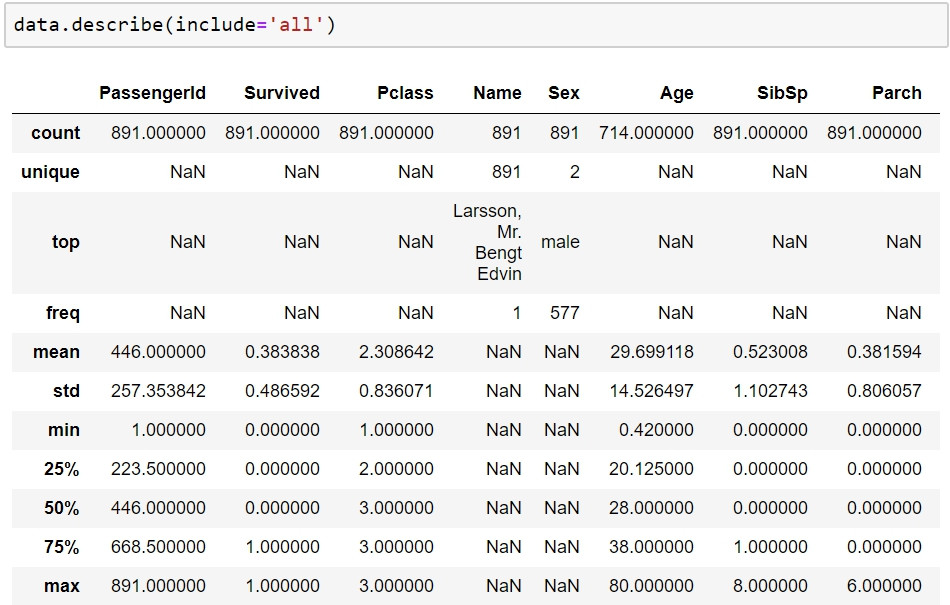
在讀取資料時,若無聲明每個欄位的類型,pandas自行將每個欄位轉換為特定的類型,例如int、float、object、category...等等。但是通常pandas自行的轉換會有不恰當的類型產生,例如將category類型誤轉為int類型。從上面產生的描述統計結果我們已經可以觀察到一些錯誤,第一個欄位PassengerId明顯是屬於名目尺度資料,但是居然有著算術平均數。錯誤的轉換將影響描述統計的結果,對錯誤的類型進行描述統計將會使其描述內容無意義,因此首先需要對每個欄位的資料尺度有所認知,才能為每個欄位設置正確的類型。
以下為各欄位的資料尺度以及應設置的資料類型:
|欄位 | 資料尺度 | 類型|
|---|---|
| PassengerId | 名目尺度 |category|
| Survived | 名目尺度 |category|
| Pclass | 次序尺度 |int|
| Name | 名目尺度 |category|
| Sex | 名目尺度 |category|
| Age | 等比尺度 |float|
| SibSp | 等比尺度 |int|
| Parch | 等比尺度 |int|
| Fare | 等比尺度 |float|
| Cabin | 名目尺度 |category|
| Embarked | 名目尺度 |category|
將每個欄位修正成正確的類型:
data.PassengerId = data.PassengerId.astype('category')
data.Survived = data.Survived.astype('category')
data.Pclass = data.Pclass.astype(int)
data.Name = data.Name.astype('category')
data.Sex = data.Sex.astype('category')
data.Age = data.Age.astype(float)
data.SibSp = data.SibSp.astype(int)
data.Parch = data.Parch.astype(int)
data.Fare = data.Fare.astype(float)
data.Cabin = data.Cabin.astype('category')
data.Embarked = data.Embarked.astype('category')
data.describe(include='all')
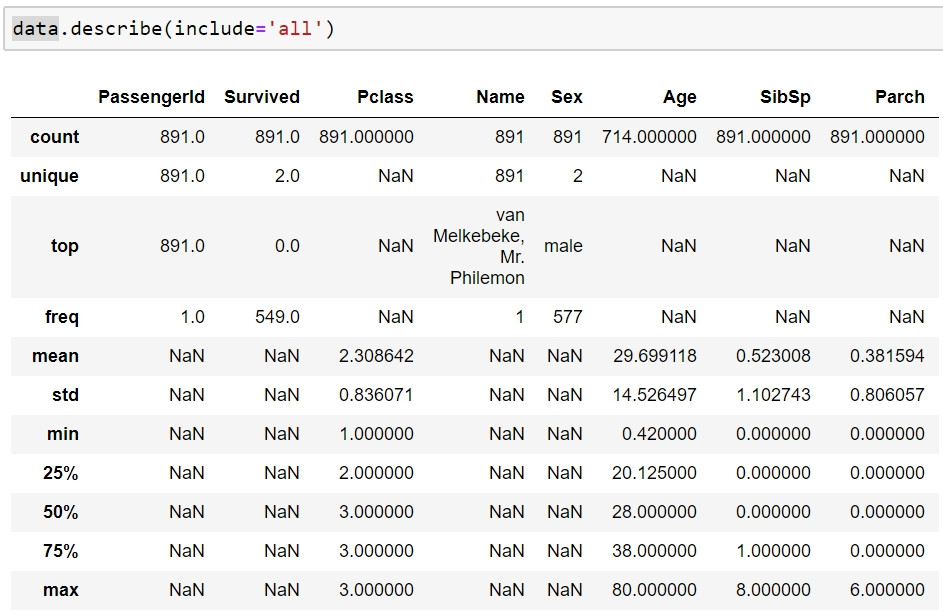
透過設定各欄位的正確類型,終於敘述統計都正常了,也因此我們可以程度上的理解每個欄位的基本情形。
以下是另一種在讀取檔案時就處理各欄位類型的設置方式:
column_types={'PassengerId':'category',
'Survived':'category',
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'category',
'Embarked':'category',}
data = pd.read_csv('data/train.csv', dtype=column_types)
下一篇文章將介紹各尺度資料的視覺化方式。

