以下例子是用SVC來進行的~
一樣是沿用scikit-learn的乳癌資料庫,步驟跟之前的一樣,要注意svm.SVC要給兩個參數(參考),一個是C,懲罰分錯的weight;另一個是gamma,是指在一次訓練中,資料點影響力影響的「遠」或「近」,數值越低代表影響得越遠,越高代表影響得越近,意即越近的資料點所擁有的權重越大。
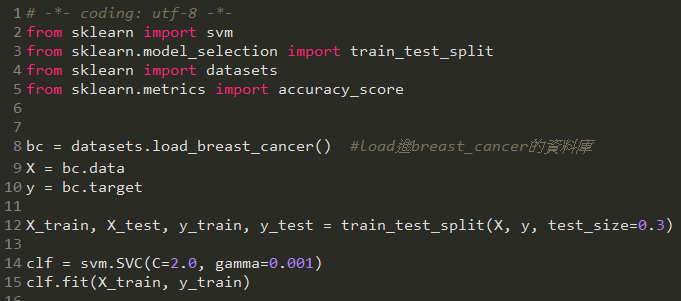
可以看一下SVC執行時所帶的參數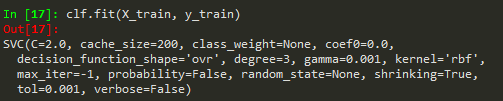


可以來調調看gamma值跟C值,gamma值越高的話代表越近的資料點權重越大,用訓練集訓練時可能會出現over fitting的結果。
圖片稍晚補~


 iThome鐵人賽
iThome鐵人賽