支持向量機Support Vector Machines, SVM主要是在找出最佳的分類模型。
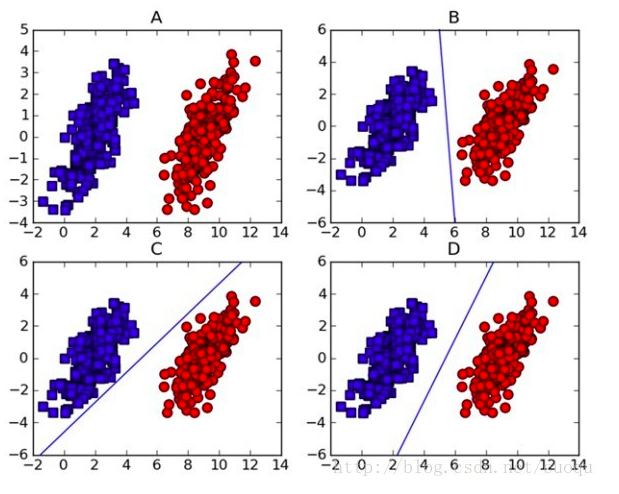
可以看到圖A有紅、藍兩堆數據點,如果要畫一條線,把這兩堆點分開,畫出來的結果可能是圖B到D,但是畫出來的線哪一條比較好呢?
一個簡單的想法是,如果我放更多數據點進去,這條線依舊可以把所有的數據點分好嗎?換句話說,這條線距離各個點的距離必須是最大的距離,這樣就算數據點進來越多,我的線依舊可以把數據點分好。
分隔線與各個點的距離稱作margin,訓練集的數據點的tuple稱之為support vector。
這個例子只是簡單的二維數據而已,試想一下我們的數據常常會有好幾個features,假設有三個feature好了,那畫出來的圖形就會是三維的,這時候我把數據點切開的就不在視線了,而是一個平面,因此,如果我有n維的feature,那我的切點就會是n-1維的。
這條分隔線可以寫成 W · X + b = 0,其中W代表向量,X代表訓練集(假設為二維X = (x1, x2)),b代表偏差值。則我們可以知道,在這條線跟所有數據點的距離為w0 + w1x1 + w2x2 = 0。因此在線上的點為w0 + w1x1 + w2x2 > 0,在現下的點為w0 + w1x1 + w2x2 < 0。(參考)


 iThome鐵人賽
iThome鐵人賽