文章至今,終於可以直球對決,
讓小馬我用數學來定義,什麼是【大數據(Big Data)】?
解釋一:極大量數據,足以找出足夠「極其稀有的數據證據」。
造句:這樣的數據分析結果,必須透過Big Data,才有辦法做到。
造句:這兩個商品的關聯,必須透過Big Data,才有辦法發現。
例如我團隊執行出的極稀有且有趣的「抗菌洗手乳」與「親子票券關聯」。換句話說,只靠少量資料就能得到的分析,根本不能當作Big Data,而就只是單純的數據分析罷了。
解釋二:無法以人工處理的大量結構化資料
造句:系統裡存在的資料已經是Big Data等級,我無法以Excel來寫公式運算。
Excel2010版的儲存格上限是1,048,576列乘以16,384欄(以下以105萬筆資料較容易說明)。換句話說,例如,當交易筆數超過105萬筆,則無法存於同一張Excel工作簿,也無法利用Excel計算出……例如,某個會員總交易筆數……而勢必只能透過資料庫相關的程式處理(例如SQL)。
綜合了解釋一和解釋二......
再加上這個條件:我們都知道統計樣本最低極限是30筆。
這樣的數值也應該反映在我所謂的【極其稀有的數據證據】上。意思是,如果105萬筆資料以內,能得到超過30筆的某些商品關聯組合,則這樣做出來的關聯分析,並不符合【大數據(Big Data)】的定義,而就是單純的【數據分析裡的關聯分析結果】罷了。
容我說明得更清楚些,這個105萬筆資料,它的最底層是一筆訂單的多項商品,例如下圖這4筆訂單是10筆資料(而不是4筆):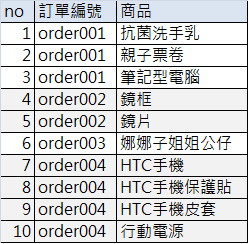
如果現在做的是【二個商品組合的關聯分析】,則你的【可用訂單樣本】(只購買一項商品的訂單不是你的可用訂單樣本,像上圖的order003就不能算,因為你在看的是二個商品組合),最多,只會有52.5萬筆的【可用訂單樣本】,不可能比52.5萬筆多,對吧?最棒最完美的狀況就是105萬筆資料,剛剛好都是每筆訂單購買二項商品,這樣你就有最大的樣本數:52.5萬筆訂單。
再來,發生【特定某二商品組合的次數】,在這52.5萬筆訂單中,最高,不能出現高於30次。
52.5萬筆訂單、商品組合出現30次(52.5萬筆訂單裡,只有30筆,出現了又買商品A又買商品B的狀況),而這個概念,不正是Support值嗎?
30/525000 = 0.000057143 = 0.0057143%
這個數字的意思代表:
當【二商品組合】的【
Support > 0.0057143%】時,表示只要不滿105萬筆資料,就可以得到30個以上的樣本;換句話說代表著,不需要Big Data,這個組合也會被人工能製作的關聯分析給發現。
再換句話說,當【二商品組合】的【
Support < 0.0057143%】時,表示必須超過105萬筆資料,才有機會得到30個以上的樣本;換句話說代表著,你需要Big Data,這個組合才會被關聯分析給發現並確認。
好的,接著我要用我自己本身非常討厭的代數去說明,在大部分的狀況下,向還沒了解自己所描述內容的人而言,用代數無疑是拉遠了彼此關係,用代數也無法解釋整個思考脈絡及源由。就像是你看到了Lift值的公式長這樣Lift(A,B) = P(B|A)/P(B) = P(A|B)/P(A),但你根本無法了解Lift值的概念是什麼。(好了...想murmur的就放番外篇吧......)
於是我們可以先得到這2條函數:
式1:
ESL / A = R
式2:S = n / R-->S*R = n
小馬理論給的限制是:
式3:
n < 30
才符合Big Data做出的關聯分析,將式子整理一下可得:
把【式2】帶入【式3】得【式4】
式4:S*R < 30-->S < 30/R
把【式1】帶入【式4】得【式5】
式5:S < 30*A/ESL
終於,我們把【大數據(Big Data)】的定義,用數學式子給決定下來了:
能被稱為【大數據(Big Data)】做出的關聯分析,必須符合
0 < Support < 30*A/ESL。
得證 #
(至於Confidence要多少...自己抓就好,反正雙向Confidence不管至少30%,至少40%還是要抓到至少80%,Lift都會爆表得高。)
怎麼使用呢?
例如我要做【2商品組合】,則跑出來的support值,必須0 < S < 0.005722% (30*2/1,048,576),才符合【大數據(Big Data)】做出的關聯分析。
好的,我們重新順一遍這個結論怎麼來的。考邏輯囉~
1.啤酒尿布被稱為大數據結論
2.因此關聯分析可視為定義大數據的元素
3.並非所有關聯分析都是大數據,例如我上面10筆訂單,也能做出關聯分析。
4.那要超過多少筆訂單,做出來的關聯分析,才算大數據?
5.應該先問,超過多少筆資料,才不是人工所能處理的範圍?
6.以最常的人工代表工具Excel有1,048,576列的限制(以下稱ESL)來看,
7.當資料筆數超過ESL,就符合大數據【必須系統處理,無法人工處理】的定義。
8.因此,當資料筆數小於等於ESL時,還能透過關聯分析發現的商品組合(次數>=30),
9.並不是大數據,而就單純是關聯分析的結果。
10.當資料筆數大於ESL時,才透過關聯分析發現的商品組合,
11.才是透過大數據得到的。
同一時間,因為這個Support值極低、Lift值極高,這種商品組合,絕對符合老闆想看到的分析之【重點2.大家不知:這個關聯並不是大家早就知道的關聯。】因為它們出現的次數非常非常少,大家肯定不知道了吧!?
當然,第6,7點,ESL這個臨界點,是否真能代表人工處理與系統處理的界線?難道用SQL處理就不算是人工處理?那從超過ESL的母體抽取不到ESL的樣本來做關聯分析,是算系統處理還是人工處理?Support值竟然設了上限而沒有設下限,只要>0?意思是只出現過1次也能算囉?
這就留待強者們後續的討論了,小馬僅以拋磚引玉之姿,拋出一條大方向,將【大數據(Big Data)】的定義從ESL的角度開始出發,最後以數學函式去做最終呈現。
希望有朝一日,集眾人之力,我們能很明確地教育下一代:
能被稱為【大數據(Big Data)】做出的關聯分析,
至少必須符合0 < Support < 30*A/ESL。
「不然我怎麼教小孩啊?」
前篇番外提到了【然後我們就有資料倉儲了】,但想當然爾......
羅馬不是一天造成,資料倉儲也不是。
公司建立資料倉儲(Data Warehouse以下稱DW)的過程,
也是一番陣痛後,才有後來穩定可用的DW。
這之間,建立了DBA團隊、廣泛使用PostgreSQL、導入了ETL tool: Trinity等等,
都是起因於全台門市不能結帳,實在是一件太震撼的事情。
話說回來,在已經有既定BI系統(用的是IBM Cognos)的架構下,
還願意為了數據分析、為了其他BI系統(Tableau),去做這麼一件事,
現在回頭想想,公司還真是從善如流,
小馬對於當年IT協理的景仰(能對大老闆遊說成功),也是更上層樓呢~
在這之後,因為已經有DW,照正常狀況,
應該要把Cognos使用的資料,也轉移成從DW出去,
但歷史包袱,哪是說動就能動的?
不轉則已,一轉轉不乾淨,那可是剪不斷理還亂。
說明一下我們的尷尬關係,
人家用著公司已經用了十幾二十年的BI(Cognos),
我這個新來的BI(Tableau)一副來者不善,
想要取代的態勢(雖然我從沒這種念頭),
所以兩方基本上是處在一種井水不犯河水、相敬如賓的情勢。
因此,Cognos使用者和Tableau使用者,也是各分兩派。
為了避免重工,基本兩個BI主要負責的領域不太相同,
例如Cognos負責門市業績、Tableau負責電商業績這樣。
不過難免偶有重疊的部分,再加上麻煩的是:
兩派使用者對於某些相同名詞的定義,可能是不同的,像是GMS、GMV...
我們兩方都是每日更新數據,
只是Tableau還有Tableau Server這一段,
因此資料更新時間會比較晚。
某天,我們部門需要某個不太熟且是使用Cognos的部門,
提供一份交易數據,原因就是前面提的那樣,這數字我們可能自己有,
只是我們需要另外一派使用單位,透過Cognos,所定義的某個數字。
小馬:「美美喔~ 你們那份報表好了沒啊?」
美美:「還沒啊~ 今天資料還沒有更新完呀~」
小馬:「那是因為你們很愛拉Excel公式,(從cognos)下載後還要自己動手整理過。」
美美:「經理就說要這樣啊~」
小馬:「如果你們交給我們做齁,那個公式我幫你下完,直接就可以跑出來,根本不用你再處理。」
美美:「我們現在用的這個,好像可以請負責的單位這樣處理,我們也在想要不要提需求。」
小馬:「蛤?他們(cognos)才不會這樣處理勒~ 他們只會給你們原始數據。阿(cognos)平常不是八點就會更新完?今天怎麼都快十點了還沒好?」
美美:「沒有啊,平常都是十點才會更新完。」
登愣~ 小馬我一愣...
因為Tableau很多報表是10點更新完,我彷彿懂了什麼...
小馬:「你那個數據,是不是從【XXXX報表】下載下來的?」
美美:「對啊~ 你怎麼知道~ 我們上個月開始用的時候,發現這邊的數字比較正確...然後啊...」
原來我要的數據,就在我自己身上。
值得開心的是,原來不知不覺中,我們又成功拉攏了一個使用者。


 iThome鐵人賽
iThome鐵人賽