今天,我們要一口氣把原始的英文文字,轉成文字雲的底階資料。
- 對原始資料初步清洗(改成適合mining的長相)
- 把要分送到不同位置的字串給切開
- 把要收納資料的倉庫給建立起來
- 把【控制項】建立好
- 建置【迴圈方程】並執行
- 製作文字雲底階資料
這次要用的是在「Text Mining - Wiki」的說明,如下圖紅框位置,如果你願意數一下,會發現裡面總共有225個單字。(小馬我有數過了......)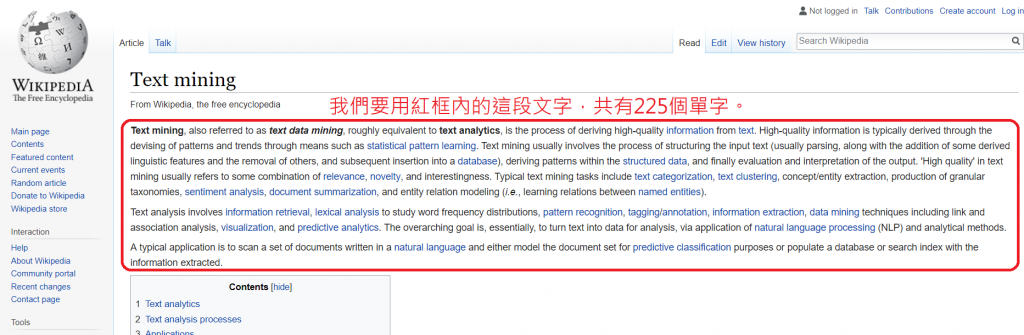
所有標點符號都當作區隔單字的標記,當然這麼做有一點點小問題,例如我會把【i.e.,】當成【i】和【e】2個單字、把【high-quality】當成【high】和【quality】2個單字。但這總之是資料清洗的範疇,要怎麼運用,視不同狀況有不同的標記判斷方式。
在這次的目標,總之我們就是要把225個單字給完全切開來,並且計算哪個單字出現了幾次;換句話說,我將每個單字出現的次數加總,應該要等於225才對。
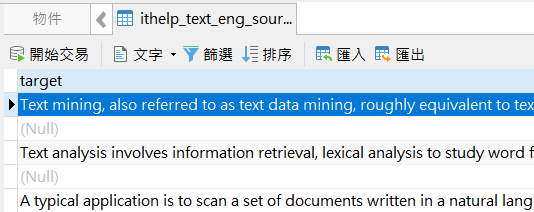
如上我將資料匯入,我們只會針對target這欄位做後續的動作,會發現這資料有點醜,中間還有null,不過不用擔心,在後續的處理,都會把這些問題給解決掉。也因此,不用太在意你匯入的資料是幾筆,這也是外迴圈的好處,每次的迴圈,都是批次把資料處理完畢,1筆也是、1000筆也是。只要確保這階段,你想處理的文字都是在相同欄位(target)即可。
DROP TABLE IF EXISTS ithelp_wordcloud_t1_source;
CREATE TABLE ithelp_wordcloud_t1_source as
select lower(TRANSLATE(target,'-,./()''/',' '))||' end' target
from ithelp_text_eng_source
;
select * from ithelp_wordcloud_t1_source
針對第一步的處理,上面SQL有3點要說明:
系統程式可不會自動判斷大小寫,【Text】和【text】對系統來說是兩個不同的單字,因此,加上了lower()把所有英文字母都變成小寫。
每個字串最後面加了' end',還記得昨天提的drink嗎?當沒有空格,空格位置變成0,會導致最後一個單字收不進去,既然如此,我們就自建最後一個單字,讓最後一個單字是我們加上的end(記得end的前面一定要有空格),就能解決囉!
「一定要加' end'嗎?」
「不一定~你想加' love'也可以啊......」
「那可以加' big data'嗎?」
「不行啊~這樣你的big會被當成收納資料收進去......」
英文非常貼心的已經有空格,幫我們把每個單字給區隔開來,然而有時候還是會遇到,是用別的標點符號做區隔,例如【tagging/annotation】,所以不如這樣,我們就把全部的標點符號,都換成空格吧!TRANSLATE()那段就是在做這樣的事情,把全部的標點符號,都改成半形空格。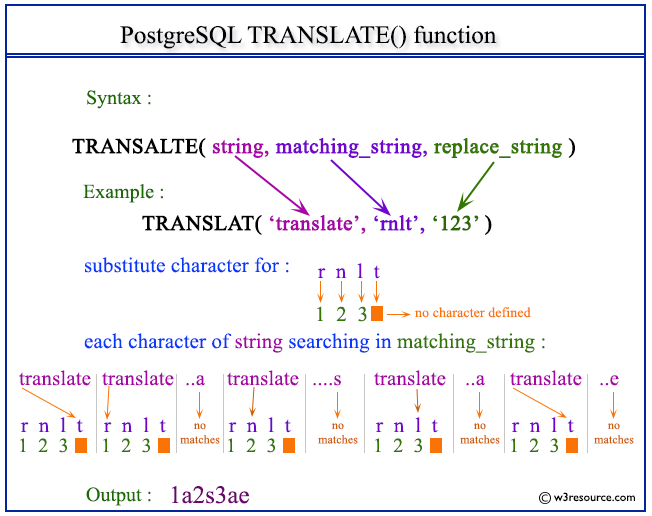
上圖是TRANSLATE()的用法,原圖出自w3resource,以前都要無止盡的REPLACE(REPLACE(REPLACE(...,現在用TRANSLATE()方便多了呢!
透過上述SQL,就能做出適合接著mining的長相:只剩下小寫單字和空格。
DROP TABLE IF EXISTS ithelp_wordcloud_t2_processing;
CREATE TABLE ithelp_wordcloud_t2_processing as
select *,
STRPOS(target,' ') tag,
LEFT(target,STRPOS(target,' ')-1) goal,
SUBSTRING(target,STRPOS(target,' ')+1) next_target
from ithelp_wordcloud_t1_source
;
select * from ithelp_wordcloud_t2_processing
針對第二步的處理,上面SQL有3點要說明:
在上一篇的舉例中,這3個欄位內容分別就是:
在這次的實際範例裡,就會如下:
DROP TABLE IF EXISTS ithelp_wordcloud_t3_goalwarehouse;
CREATE TABLE ithelp_wordcloud_t3_goalwarehouse as
select goal
from ithelp_wordcloud_t2_processing
where goal is not null and goal not in ('') and tag > 0
;
select * from ithelp_wordcloud_t3_goalwarehouse
建出goal的倉庫(goal-warehouse),當然在這次的執行中,我們只會把第一次跑出來的goal給放進去。這個步驟的好處是,之後產生的goal,只要insert進來即可,而且一旦後面有什麼地方做錯了,想從頭來過,就再依序執行1,2,3,一切就能恢復成第一次跑完的狀態。
也因此,小馬強烈建議,上面的這三個步驟,必須分開建立好,後面執行起來才不會亂;也能因應一旦自己哪個環節沒寫好,結果insert了一堆不是自己想要的內容進去goal-warehouse時,可以快速的重新來過。
在這個步驟裡,我們限定了幾個where去篩選,包括收進goal-warehouse的單字必須不是null,必須不是空白,必須tag>0。tag>0的重點,在於每一列的字串長度不同,我仍舊必須依照每一列分別各自跑到0的時候去限制,否則已經跑完的那一列,會因為迴圈還在繼續跑(因為其他列還沒跑完),導致跑完的那列最後一個單字會不斷被我收進去。
我們的第四步,原本是要做這件事:
DROP TABLE IF EXISTS ithelp_wordcloud_t1_source;
CREATE TABLE ithelp_wordcloud_t1_source as
select next_target target
from ithelp_wordcloud_t2_processing;
和步驟3很像,都是從t2拿某個欄位,去建下一份table。
但此時我們發現,建的table是前面步驟1已經建好的t1,這告訴我們,上面這段SQL,已經必須開始放進迴圈裡面了,不能再獨立執行了。再換句話說,接著的步驟4,5,6,7,8,9......其實是將步驟1,2,3重複第一次、將步驟1,2,3重複第二次......
是昨天暴的雷呢~
--t1
DROP TABLE IF EXISTS ithelp_wordcloud_t1_source;
CREATE TABLE ithelp_wordcloud_t1_source as
select next_target target
from ithelp_wordcloud_t2_processing;
t1就是原本打算進行的步驟4。和原本t1的差別,在於第一次的t1來自source並且做了些清洗,但這次的t1來自t2,而且直接選用了next_target這個欄位當作target。
--t2
DROP TABLE IF EXISTS ithelp_wordcloud_t2_processing;
CREATE TABLE ithelp_wordcloud_t2_processing as
select *,
STRPOS(target,' ') tag,
LEFT(target,STRPOS(target,' ')-1) goal,
SUBSTRING(target,STRPOS(target,' ')+1) next_target
from ithelp_wordcloud_t1_source
第二次開始的t2,仍舊是原汁原味的步驟2。
--t3
INSERT into ithelp_wordcloud_t3_goalwarehouse
select goal from ithelp_wordcloud_t2_processing
where goal is not null and goal not in ('') and tag > 0;
但第二次開始的t3可不一樣囉,第一次的t3把goal-warehouse建起來,第二次之後,只需要insert,不能再drop + create,不然之前存好的,會都被刪掉。
上面這三串,加起來就是要放在迴圈query裡面的內容。
但在寫這個迴圈function之前,我們還有一個很重要的事情要做。
設計控制項,才是真正的第4步驟,上面提的假第4步驟,先放在心裡不要忘記就好。
DROP FUNCTION IF EXISTS ithelp_wordcloud_1();
CREATE OR REPLACE FUNCTION ithelp_wordcloud_1()
RETURNS INTEGER as
$BODY$
BEGIN
RETURN tag
from (
select MAX(tag) over (PARTITION BY 1) tag
from ithelp_wordcloud_t2_processing
) A
group by tag
;
END
$BODY$
LANGUAGE 'plpgsql';
我們的目標,是要讓迴圈執行到每一列(每一筆資料)的tag都歸0為止,換句話說,只要有某一筆資料的tag還沒歸0,迴圈就不能停止。因此夾在BEGIN...END中間的那串,就是要找到全部資料中最大的tag,並且針對它group by,就可以跑出唯一一筆資料,同時也是我們設計好的RETURNS INTEGER,目的是當這個最大的tag也是0的時候,迴圈就會停止。換句話說,是當ithelp_wordcloud_1() > 0 的時候,才執行迴圈。
因此這個ithelp_wordcloud_1(),將會被我們放在等下要建立的迴圈之上。
----------以下開始ithelp_wordcloud_2的設定----------
DROP FUNCTION IF EXISTS ithelp_wordcloud_2();
CREATE OR REPLACE FUNCTION ithelp_wordcloud_2()
RETURNS VOID as
$BODY$
BEGIN
----------以下開始【控制項】設定----------
WHILE ithelp_wordcloud_1() > 0
----------以上結束【控制項】設定----------
----------以下開始【迴圈內容】設定----------
LOOP
--t1
DROP TABLE IF EXISTS ithelp_wordcloud_t1_source;
CREATE TABLE ithelp_wordcloud_t1_source as
select next_target target
from ithelp_wordcloud_t2_processing;
--t2
DROP TABLE IF EXISTS ithelp_wordcloud_t2_processing;
CREATE TABLE ithelp_wordcloud_t2_processing as
select *,
STRPOS(target,' ') tag,
LEFT(target,STRPOS(target,' ')-1) goal,
SUBSTRING(target,STRPOS(target,' ')+1) next_target
from ithelp_wordcloud_t1_source;
--t3
INSERT into ithelp_wordcloud_t3_goalwarehouse
select goal
from ithelp_wordcloud_t2_processing
where goal is not null and goal not in ('') and tag > 0;
END LOOP
----------以上結束【迴圈內容】設定----------
;
END
$BODY$
LANGUAGE 'plpgsql';
----------以上結束ithelp_wordcloud_2的設定----------
- 看到真步驟4的控制項ithelp_wordcloud_1()放的位置了嗎?
- 看到假步驟4的t1,t2,t3內容放在LOOP...END LOOP中間了嗎?
- 看到這次不是
RETURN SETOF,也不是RETURN INTEGER,而是RETURN VOID了嗎?
VOID正如這個字的本意,當你執行上面設定好的function: ithelp_wordcloud_2()
--記得要去執行,上面一大串的工作才會進行喔~
select ithelp_wordcloud_2();
你會覺得什麼事情都沒發生,因為它既不是要返回給你一張table,也不是要返回給你一個整數,而是返回給你一股空虛。
好啦~ 其實當然不空虛,背後已經默默執行完t1,t2,t3好幾次了,
那要去哪看呢?當然是我們t3建出來的倉庫囉~
select * from ithelp_wordcloud_t3_goalwarehouse
你就會發現完整的225單字,已經被整整齊齊放在goal-warehouse裡了。就如同這份Excel檔案(.xlsx)的內容一樣。
DROP TABLE IF EXISTS ithelp_wordcloud_t6_goal;
CREATE TABLE ithelp_wordcloud_t6_goal as
select A.*
from(
select
goal,
SUM(1) cnt
from ithelp_wordcloud_t3_goalwarehouse
group by goal
) A
--where cnt >=2 and goal not in ('the','and','of','to','a','is','in','into','or','for','as','with')
order by cnt desc
;
select * from ithelp_wordcloud_t6_goal
我相信拿到那份Excel,後面你一定就會處理了。t6做的內容也不過如此,就是針對goal去group by,計算出現的次數。於是,我們就達成了最終目標:製作文字雲底階資料。
文字雲,小馬一樣是透過多年的好夥伴「Tableau」製作:
然而我接著要談的這件事,我自認,非常重要。
如果是一路跟著系列文的朋友,相信已經看了我不少次的呼籲:
做資料處理,唯一選擇SQL。
文字雲的底階資料處理也是一樣,或許市面上,有非常多的軟體或網站,你隨便一篇文章丟進去,它就能幫你跑文字雲。但這也正是非SQL處理資料的缺點,一旦看到不如預期的雲產生,要對它做處理是比較麻煩的。但SQL不一樣,舉例t6,單字只出現過1次的,我就不看了,或是介係詞,我就不看了,非常非常簡單就能被我where篩選掉。
當我現在有個電商網站,但我不知道哪個關鍵字很常被搜尋,不知道應該要放哪個字眼在網頁上當作快速連結,難道我必須透過其他軟體,匯出Excel,再把Excel給後台人員,讓他們去看Excel的內容,人工將這個字眼建上去?如果現在用的是SQL,只要我透過原始資料,處理完,就可以直接匯入後台資料庫,直接產生,不用再繞路或產生落地資料。換句話說,大家拿到建好的ithelp_wordcloud_t6_goal就能直接使用。
最前面提到的關聯分析也是相同概念,當我現在要發廣告Email給消費者,內容要有高度關聯的商品組合,如果不透過SQL,這段要做成自動化,那是多麼麻煩的繞路工程?但當SQL可以直接幫你選出lift值最高的組合,不就幾乎等於從資料庫拿組合了嗎?
最重要的是,SQL語法,有比其他語言還難嗎?肯定是沒有的。
剩下3天,我們要運用至今所述,包括【外迴圈+內迴圈】,製作【中文文字雲的底階資料】。
上一篇:
SQL迴圈實作 -6.英文文字雲的處理工廠1
下一篇:
SQL迴圈實作 -8.中文文字雲的處理工廠1


 iThome鐵人賽
iThome鐵人賽