面對超過海量的文字我們勢必得進行有效率搜尋與篩選才能迅速獲得需要的訊息
下載nltk內建文本
import nltk
nltk.download()
匯入剛下載的文本
>>> from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
在文本後用concordance()方法搜尋字串
>>>text1.concordance('god')
Displaying 25 of 25 matches:
linterable glasses ! EXTRACTS . " And God created great whales ." -- GENESIS .
. " That sea beast Leviathan , which God of all his works Created hugest that
. A . D . 1668 . " Whales in the sea God ' s voice obey ." -- N . E . PRIMER .
' S CONVERSATIONS WITH GOETHE . " My God ! Mr . Chace , what is the matter ?"
out me in the dark . " Landlord , for God ' s sake , Peter Coffin !" shouted I
of the word , to the faithful man of God , this pulpit , I see , is a self - c
orld . From thence it is the storm of God ' s quick wrath is first descried , a
arliest brunt . From thence it is the God of breezes fair or foul is first invo
ed over me a dismal gloom , While all God ' s sun - lit waves rolled by , And l
r . " In black distress , I called my God , When I could scarce believe him min
htning shone The face of my Deliverer God . " My song for ever shall record Tha
joyful hour ; I give the glory to my God , His all the mercy and the power . N
of the first chapter of Jonah --' And God had prepared a great fish to swallow
lesson to me as a pilot of the living God . As sinful men , it is a lesson to u
wilful disobedience of the command of God -- never mind now what that command w
ard command . But all the things that God would have us do are hard for us to d
ndeavors to persuade . And if we obey God , we must disobey ourselves ; and it
ves , wherein the hardness of obeying God consists . " With this sin of disobed
n him , Jonah still further flouts at God , by seeking to flee from Him . He th
n will carry him into countries where God does not reign , but only the Captain
onah sought to flee world - wide from God ? Miserable man ! Oh ! most contempti
at and guilty eye , skulking from his God ; prowling among the shipping like a
and turns in giddy anguish , praying God for annihilation until the fit be pas
. In all his cringing attitudes , the God - fugitive is now too plainly known .
forced from Jonah by the hard hand of God that is upon him . "' I am a Hebrew ,
搜尋兩個字串共同的上下文
text1.common_contexts(["father", "god"])
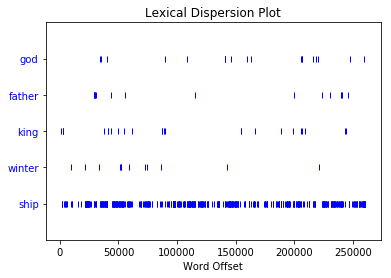
觀察字串分布在文本中的位置,可使用歷屆總統講稿觀察當中詞彙變化
text1.dispersion_plot(["god", "father", "king", "winter", "ship"])
對文本使用count()可得到出現次數
>>>text1.count('god')
20
將文本放進len()函數可得文本總字數
>>>len(text1)
260819
#文本總字數(不重複)
>>>len(set(text1))
19317
把單字出現次數除上文本總字數,可得單字出現在文本中的頻率
>>>text1.count('god')/len(text1)
7.668153010325168e-05
想知道文本中出現頻率最高的字可用FreqDist()將單字與次數做成dict,再用.most_common()以list呈現
>>>FreqDist(text1)
FreqDist({',': 3681, 'and': 2428, 'the': 2411, 'of': 1358, '.': 1315, 'And': 1250, 'his': 651, 'he': 648, 'to': 611, ';': 605, ...})
>>>FreqDist(text1).most_common(5)
[(',', 3681), ('and', 2428), ('the', 2411), ('of', 1358), ('.', 1315)]
可再將單字與次數做成累積頻率圖
>>>FreqDist(text1).plot(50, cumulative=True)

也可選出無重複過的單字
>>>FreqDist(text1).hapaxes()
可運用list(w for w in set(text1) if boolean)的格式找出符合條件的單字
搜尋長度>7而且出現次數>7的單字
>>>fdist5 = FreqDist(text5)
>>>sorted(w for w in set(text5) if len(w) > 7 and fdist5[w] > 7)
['#14-19teens', '#talkcity_adults', '((((((((((', '........', 'Question',
'actually', 'anything', 'computer', 'cute.-ass', 'everyone', 'football',
'innocent', 'listening', 'remember', 'seriously', 'something', 'together',
'tomorrow', 'watching']
搜尋text1內包含"app"且字尾是"ss"的單字
>>>appss = list(w for w in set(text1) if "app" in w and w.endswith("ss"))
>>>appss
['apprehensiveness', 'happiness', 'nappishness']
接著透過count()得到出現次數
>>>appcount = list(text1.count(w) for w in appss)
>>>appcount
[4,2,1]
也可以由FreqDist()完成
>>>list(FreqDist(text1)[w] for w in appss)
[4,2,1]
最後整理成字典
>>>dict(zip(appss, appcount))
{'apprehensiveness': 4, 'happiness': 2, 'nappishness': 1}
>>>text2[-2:]
['THE', 'END']
>>>fd5_freq = FreqDist(text5).most_common()
>>>print(fd5_freq)
[('.', 1268),
('JOIN', 1021),
('PART', 1016),
('?', 737),
('lol', 704),
('to', 658),
('i', 648),
...
接著要篩選只留下4個字母的單字,使用for in來處理
>>>list(w for w in fd5_freq if len(w)==4)
[]
依照直覺打出的code回傳的結果看來是錯誤的,w當中還有兩個元素,必須要加以指定
如果不想顯示次數,將for前面w改為w[0]即可
>>>list(w for w in fd5_freq if len(w[0])==4)
[('JOIN', 1021),
('PART', 1016),
('that', 274),
('what', 183),
('here', 181),
...
>>>for w in set(text6):
... if w.isupper():
... print(w)
STUNNER
BEDEVERE
DENNIS
GOD
CHARACTERS
PRINCESS
CRONE
...
>>>list(w for w in set(text6) if w.endswith('ize'))
>>>list(w for w in set(text6) if 'z' in w)
>>>list(w for w in set(text6) if 'pt' in w)
>>>list(w for w in set(text6) if w.istitle())
>>>sent = ['she', 'sells', 'sea', 'shells', 'by', 'the', 'sea', 'shore']
>>>list(w for w in sent if w.startswith('sh'))
>>>list(w for w in sent if len(w)>4)
>>>sum(len(w) for w in text1)/len(text1)
3.830411128023649
>>>def vocab_size(text):
... return len(set(text))
>>>vocab_size(text5)
6066
>>>def percent(word,text):
... fdist = FreqDist(text)
... a = fdist[word]
... b = len(text)
... return a/b
>>>percent('lol',text5)
0.015640968673628082
參考資料:Python 自然语言处理 第二版 https://usyiyi.github.io/nlp-py-2e-zh/1.html

