之前我們花了5天作完第一個實驗,從資料的匯入/清理(data cleaning)、模型訓練、模型評估、佈署到系統的整合,乖乖作過一遍,自覺收穫不少,在進行第2個實驗之前,心中有些疑惑,Google了一些資料,將問題與答案整理如下。
EDA(Exploratory data analysis,資料的探索與分析) 大部份的文章都是按字面翻譯成『探索式資料分析』,住要訴求,在開始建立模型前,先與資料培養感情,利用簡單統計與圖表,了解資料的特性與關聯。
ML Studio 確實缺乏EDA,雖然,ML Studio 在 『Visualize』選單中提供各個變數的直方圖(Histogram),但是,要作變數之間的關係分析,這部分好像比較缺乏。
依訓練資料是否標註(label)答案與否,分為『監督式學習』(Supervised Learning)與『非監督式學習』(Unsupervised Learning)。
『監督式學習』(Supervised Learning)依目標變數(Target vaiable, 即 Y)的性質,分為『迴歸』(Regression)與『分類』(Classification)。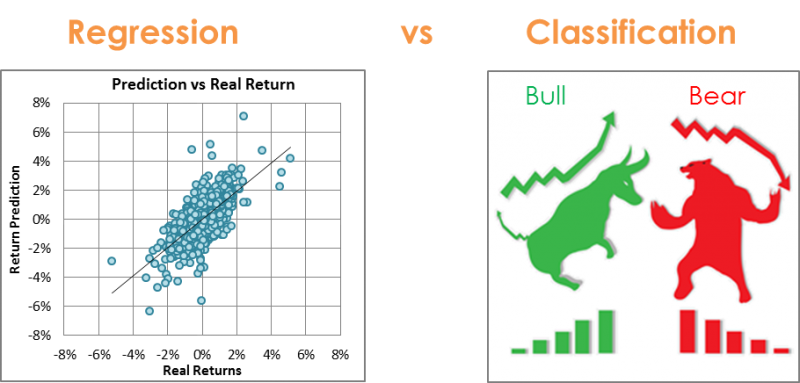
圖. 迴歸與分類,資料來源:Machine Learning: a brief breakdown
『非監督式學習』最常用的演算法用途為『集群分析』(Clustering),與『分類』(Classification) 類似,依訓練資料的特徵分為特定個數的集群。另一類用途就是『降維』(Dimensionality reduction),主要是特徵(自變數)過多或避免過度擬合,針對特徵作『特徵選取』(Feature Selection)或『特徵萃取』(Feature Extraction)。
『監督式學習』與『非監督式學習』區別,可以參看下圖: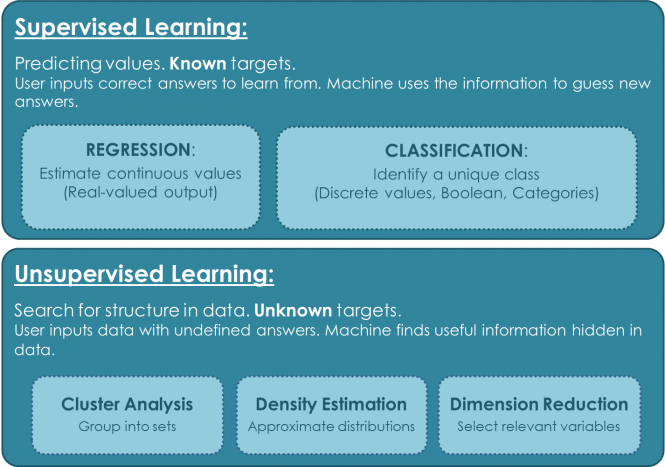
圖. 『監督式學習』與『非監督式學習』區別,資料來源:Machine Learning: a brief breakdown
可以參考Scikit-Learner這張圖: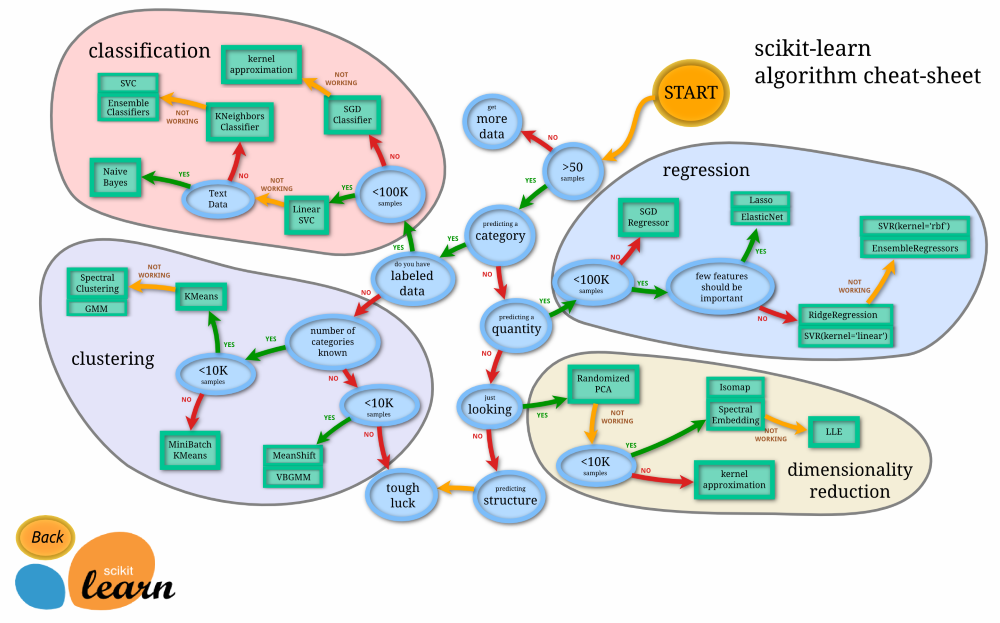
圖. 從『Start』開始看,依各種條件,建議使用哪一個演算法。
ML Studio 也有一張圖,如下: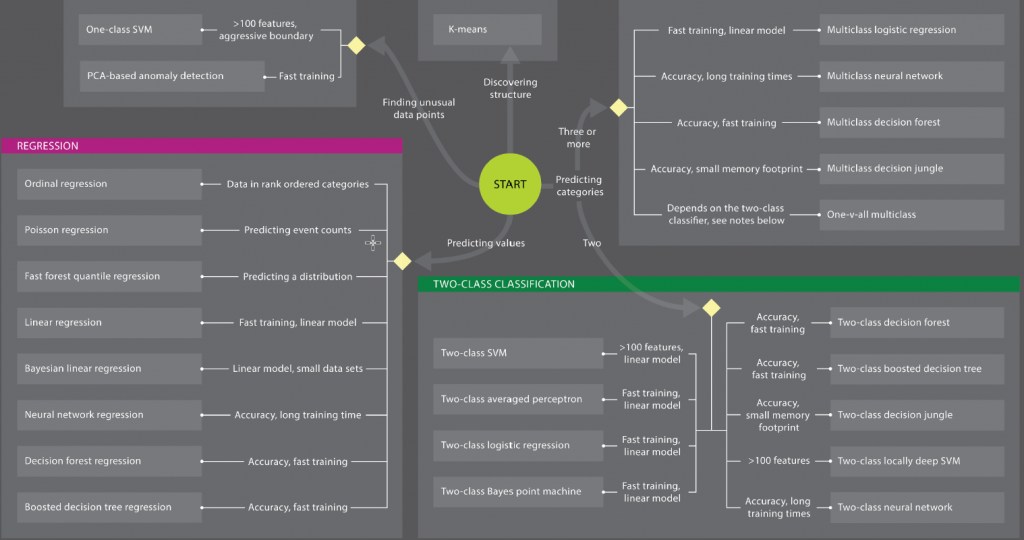
大家可以比較看看。
所以,下次我們就可以進行第二個實驗了,之前選擇『迴歸』,下次就選『分類』。
老師您好,請問一下azure除了提供machine learning的服務之外有沒有提供deep learning的服務,像是object detection、reinforcement learning、generative ai、anomaly detection這些。
有的,Azure稱為cognitive services,網址如下:
https://azure.microsoft.com/zh-tw/products/ai-services#Services
感謝提供資訊

