上篇提到怎麼避免 Overfitting 的技巧,本文要帶給大家的是如何優化深度學習,提高模型的效能。
深度學習每一次參數的更新所需要損失函數並不是由一個資料點而來的,而是由一組數據加權得到的,稱為 batch。 batch 的選擇決定了梯度下降的方向,而 batch 的數量就是 batch size。:
Full Batch:batch size 為樣本總數。如果數據集較小,可以使用 Full batch learning 的形式,
Mini batch:解決上述方法的缺點,提高學習效率,將訓練集分成很多批(batch),對每一批計算誤差並更新參數,是深度學習中很常見的學習方式。
下圖左邊是 full batch 的梯度下降效果,右邊是 mini batch 的梯度下降效果,可以看到它是上下波動,但整體還是呈現下降的趨勢。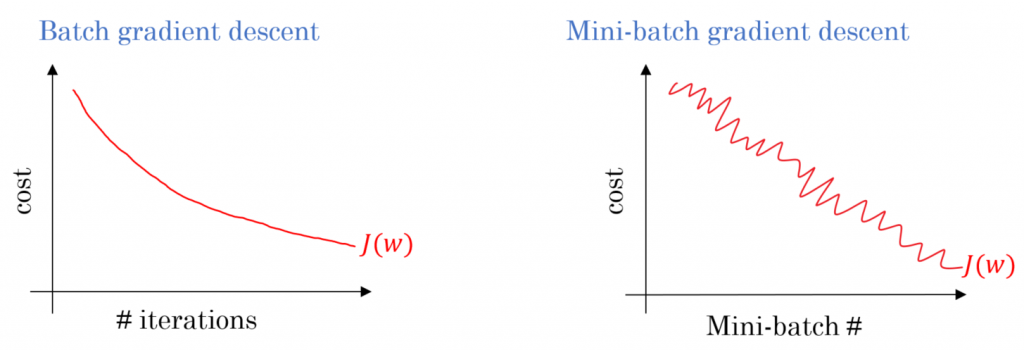
圖片來源:https://towardsdatascience.com/gradient-descent-algorithm-and-its-variants-10f652806a3
隨機梯度下降(SGD)在每個樣本上執行參數更新。因此,每個樣本都有學習。與 mini-batch 相比,它為學習過程增加了更多的噪音,有助於改善泛化錯誤,但會增加運行時間。
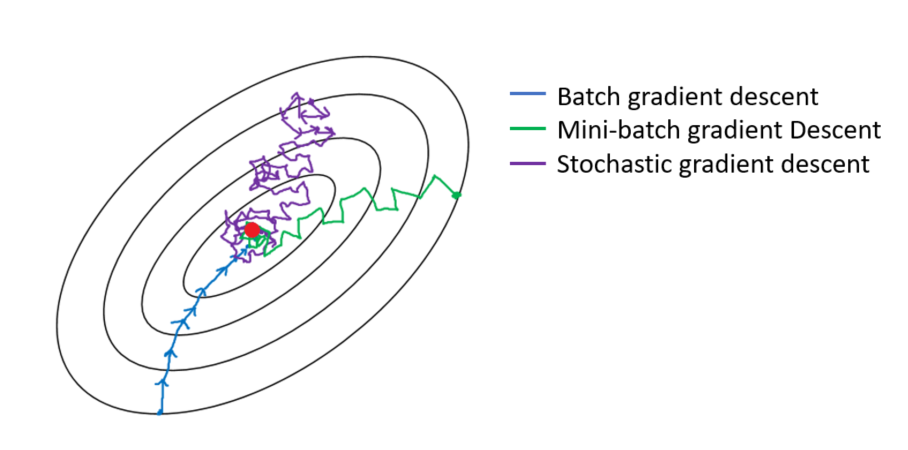
圖片來源:https://towardsdatascience.com/gradient-descent-algorithm-and-its-variants-10f652806a3
與物理慣性有關,想像球在碗內來回滾動的物理定律為基準來移動的畫面。momentum 基本思路是為了尋找最佳解而加入了「慣性」的影響,好處是振盪的幅度變小且縮短了到達一定地點的時間,另外有可能透過慣性來讓梯度下降跳出局部最小值(local minimum)。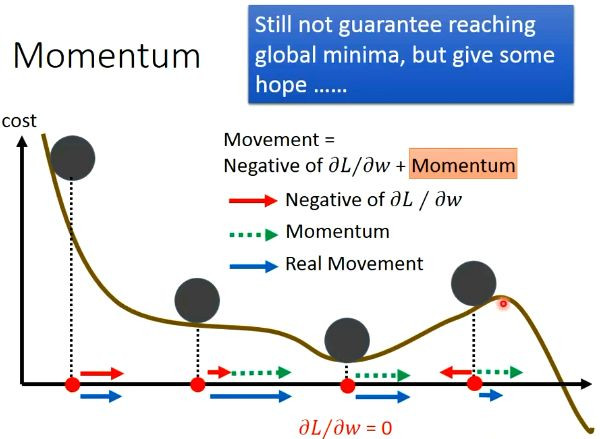
圖片來源:https://zhuanlan.zhihu.com/p/34240246
今天的內容先到這裡,下篇將繼續介紹深度學習中 Optimization 的更多技巧,例如如何動態調整學習率 (learning rate)等,大家繼續加油!

拖台錢好趴特呢:魯夫

