當開始興致勃勃的嘗試畫魔法陣,搭建神經網絡模型時,也許會遇到下面的情形:
哥布林之吶喊:我明明在訓練集表現很好啊,為什麼實際上線時結果卻崩潰了(抱頭)
那你應該是遇到 Overfitting 了。
Deep Learning 不是萬能的,例如其中一個限制就是 Overfitting: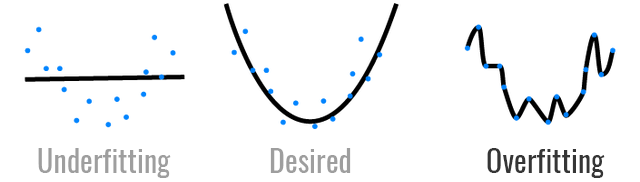
圖片來源:https://hackernoon.com/memorizing-is-not-learning-6-tricks-to-prevent-overfitting-in-machine-learning-820b091dc42
深度學習常遇到的問題是:難以概括看不見的數據。神經網絡具有大量的權重雖然可以很好地抓出訓練集中的特徵,卻也容易導致過度擬合的現象。若碰見資料不均的情況(例如在某些類別中沒有足夠的數據),雖然模型在訓練集的表現佳,但在測試集(即從未見過的數據)可能表現極差,表示此模型沒有足夠泛化(generalization)。
這是機器學習中最佳化(optimization)和泛化(generalization)之間的 trade-off 。
如何避免模型能夠 Overfitting 呢?最簡單的做法是:「搜集更多資料」。如同前面提到,資料不均或資料過少都有可能讓模型對於那些未知的數據分佈無法掌握,資料的收集可以降低 Overfitting 的風險。在資料分析任務中,更多的數據往往能提高模型的準確性,且減少過度擬合的可能性。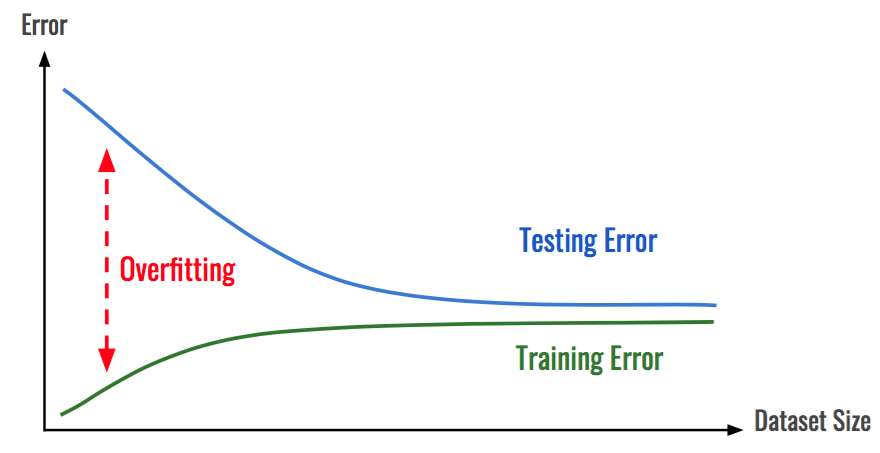
圖片來源:https://hackernoon.com/memorizing-is-not-learning-6-tricks-to-prevent-overfitting-in-machine-learning-820b091dc42
BUT!訓練模型最難過的就是這個 BUT!
事情不總是這麼順心如意,在實際場域下,你最常遇到的問題大概就是客戶無法提供大量資料,或是資料本身是 skewed distribution。因此,接下來要介紹在 Deep Learning 中的幾個常用技巧:
Dropout
透過减少神經網絡的層數、神經元個數等方式,可以限制神經網絡的擬合能力,而 Dropout 的處理方式是隨機關閉一些神經元,如下圖:
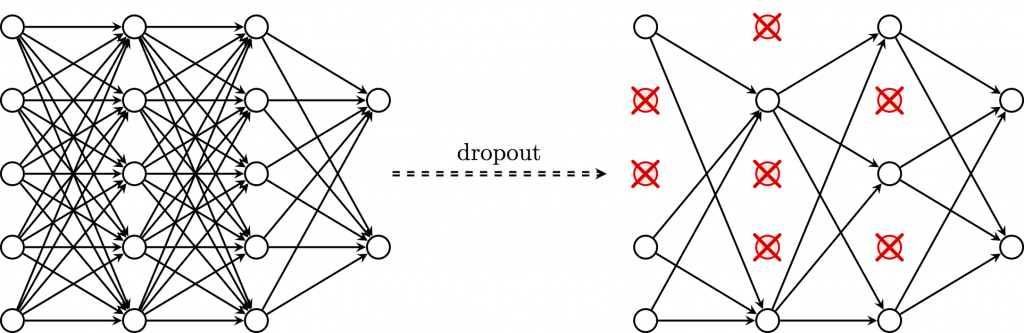
圖片來源:https://github.com/PetarV-/TikZ/tree/master/Dropout
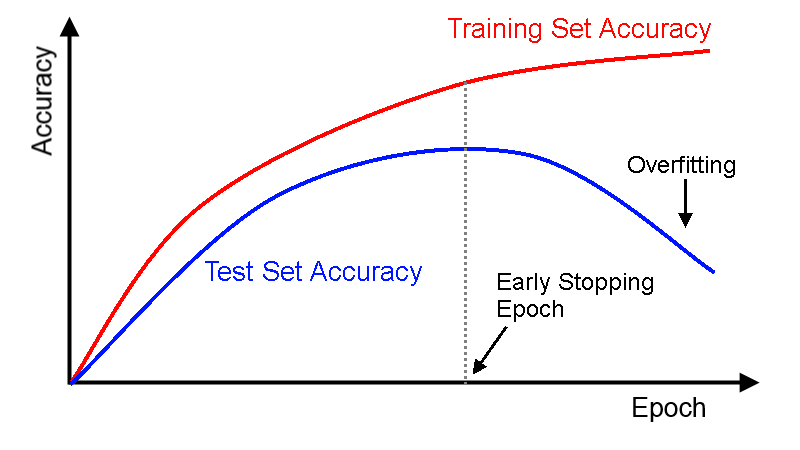
圖片來源:https://deeplearning4j.org/docs/latest/deeplearning4j-nn-early-stopping
Data augmentation
如果是圖片相關任務的話,我通常會用到 Data augmentation 的方式,它會增加本身數據的多樣性。由於收集資料是一個繁瑣而昂貴的過程,Data augmentation 在這邊就成為是另一種增加資料的替代方式。
圖片來源:https://medium.com/nanonets/how-to-use-deep-learning-when-you-have-limited-data-part-2-data-augmentation-c26971dc8ced
Weight Decay
原理是在 cost function 的後面增加一個懲罰項(代表對某些參數做一些限制),如果一個權重太大,將導致代價過大,因此在反向傳播後就會對該權重進行懲罰,使其保持在一個較小的值。例如:常見的 L1 Regularization 和 L2 Regularization 的公式: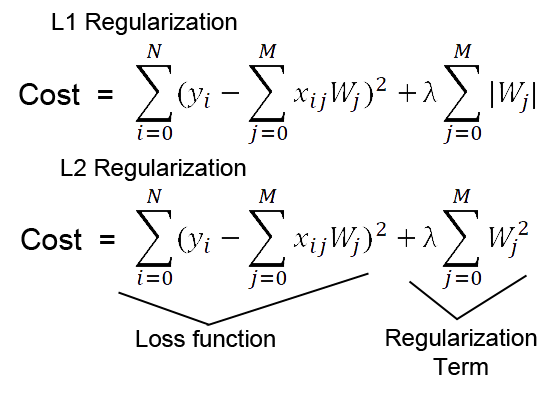
圖片來源:http://laid.delanover.com/difference-between-l1-and-l2-regularization-implementation-and-visualization-in-tensorflow/
下圖是使用 L2 Regularization 降低 Overfitting 的例子,相比之下,使用 Weight Decay 後,訓練資料與測試資料的辨識準確率差距縮小了。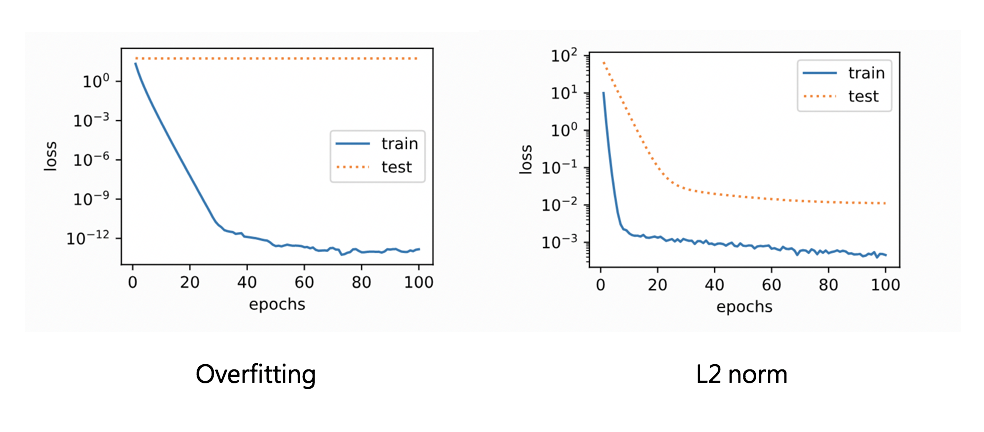
簡化模型複雜性
Overfitting 某方面是呈現出目前模型太強大了,已知具有太多層和隱藏單元的神經網絡非常複雜,所以另一個避免 Overfitting 的方法是直接是減小模型的大小。同時這也能讓模型更輕,訓練、運行更快。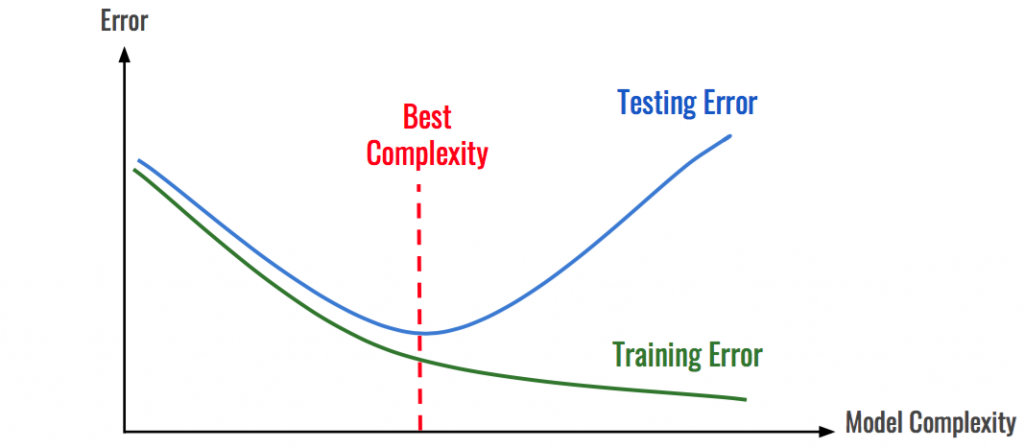
圖片來源:https://hackernoon.com/memorizing-is-not-learning-6-tricks-to-prevent-overfitting-in-machine-learning-820b091dc42
總結一下,本文介紹了六種避免 Overfitting 的方法:
這些方法的目的是希望讓模型能夠更穩健,提高泛化程度。
而下篇預計說明 最佳化(optimization) 的方法,各位見習魔法使繼續精進吧!
mini-batch 也可以減少 overfitting。
謝謝大大的補充~!
mini-batch 的部分我把它放在[精進魔法] Optimization:優化深度學習模型的技巧(上)內

