自然語言處理(NLP)的目標是設計演算法來讓電腦「理解」自然語言以執行一些任務,依難易度舉例如下:
圖片來源:https://www.ontotext.com/top-5-semantic-technology-trends-2017/
分詞
將句子分成最小的語義單位,是信息檢索、文本分類、情感分析等後續自然語言處理任務的基礎。英文的分詞可用空格切,而中文分詞是困難的。
詞形還原
指的是將詞語還原成最基本的形式,以英文來說,例如: am, are, is 轉成 be
詞性標注(POS,Part-Of-Speech)
標上詞性類別,像是名詞、動詞、形容詞。以語法特徵為主要依據,為兼顧詞彙意義的對詞進行劃分。
圖片來源:https://nlpforhackers.io/training-pos-tagger/
依存語法
分析句子中的主謂賓等,相互分析之間的依賴關係,一個句子只有一個「根」。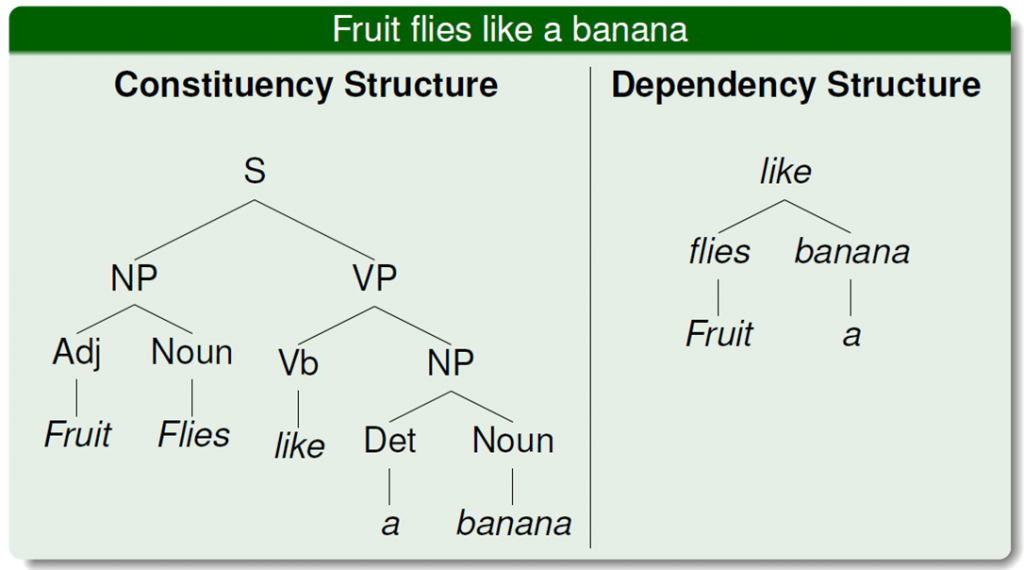
圖片來源:https://www.cs.bgu.ac.il/~elhadad/nlp12/nlp03.html
命名實體識別(Named Entity Recognition, NER)
在句子的序列中,定位並識別人名、地名、機構名等任務。
圖片來源:https://blog.paralleldots.com/data-science/named-entity-recognition-milestone-models-papers-and-technologies/
而在深度學習崛起後,加速 NLP 的研究發展。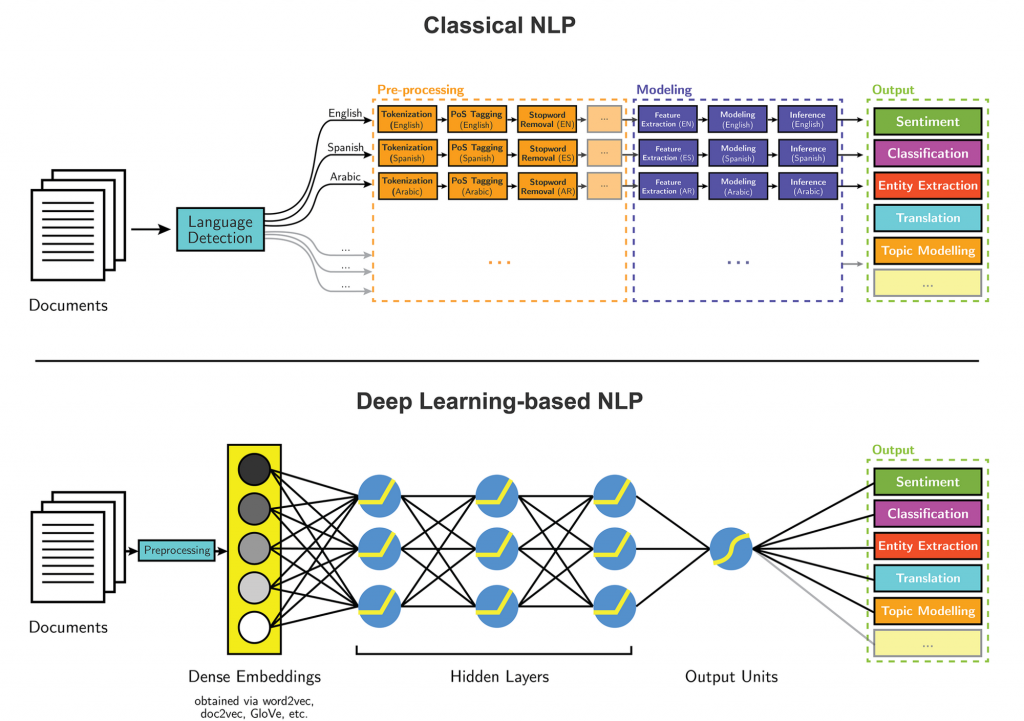
圖片來源:https://medium.com/intro-to-artificial-intelligence/entity-extraction-using-deep-learning-8014acac6bb8
將語料庫中的單詞(word)分佈在向量空間中,其中單詞之間的餘弦距離(Cosine Distance)用於衡量彼此的相似性,在上下文中給出一個單詞來識別性別和地理位置,如下圖的 Vector Representations: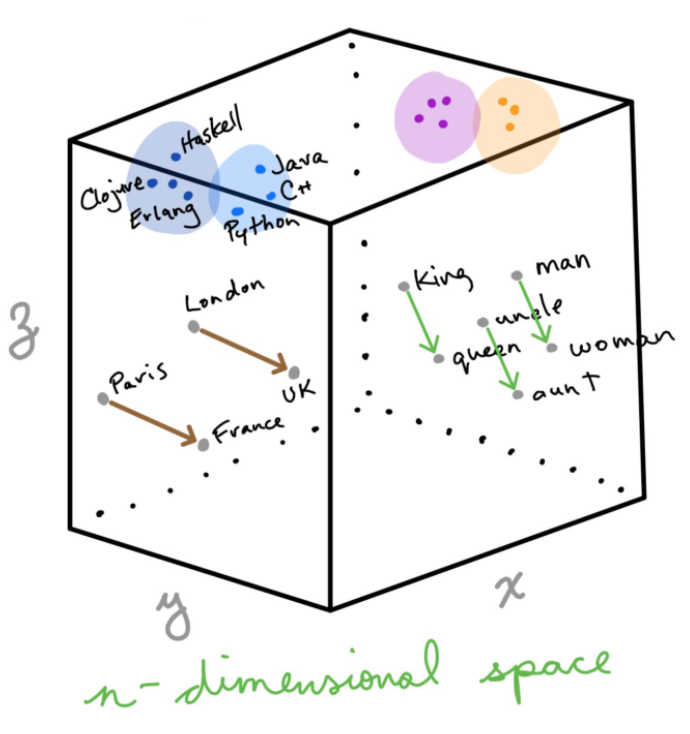
圖片來源:https://medium.com/cityai/deep-learning-for-natural-language-processing-part-i-8369895ffb98
Word2vec 與 one-hot encoding 的比較:
one-hot encoding,把每個單詞當成一個維度,若總共有十萬個單詞,那就會有十萬個維度。one-hot encoding 使用稀疏方式儲存,非常簡潔,但缺點是不能體現單詞和單詞之間的關係,且容易產生維度災難(curse of dimension)。Skip-gram 或 CBOW 等方法來實現。完成 Word2vec 訓練後,可以映射每個詞到一個向量,用來表示詞對詞之間的關係。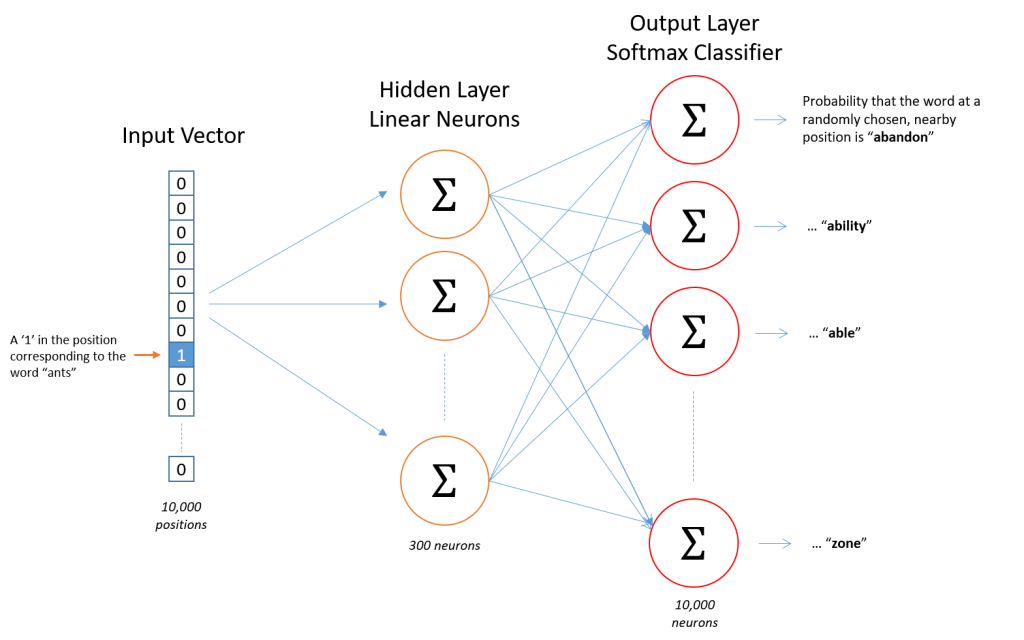
圖片來源:https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
RNN/LSTM/GRU
特色是可處理序列的資料,很高興我們之前有把 RNN 核心魔法陣說明過了,傳送門:- [魔法陣系列] Recurrent Neural Network(RNN)之術式解析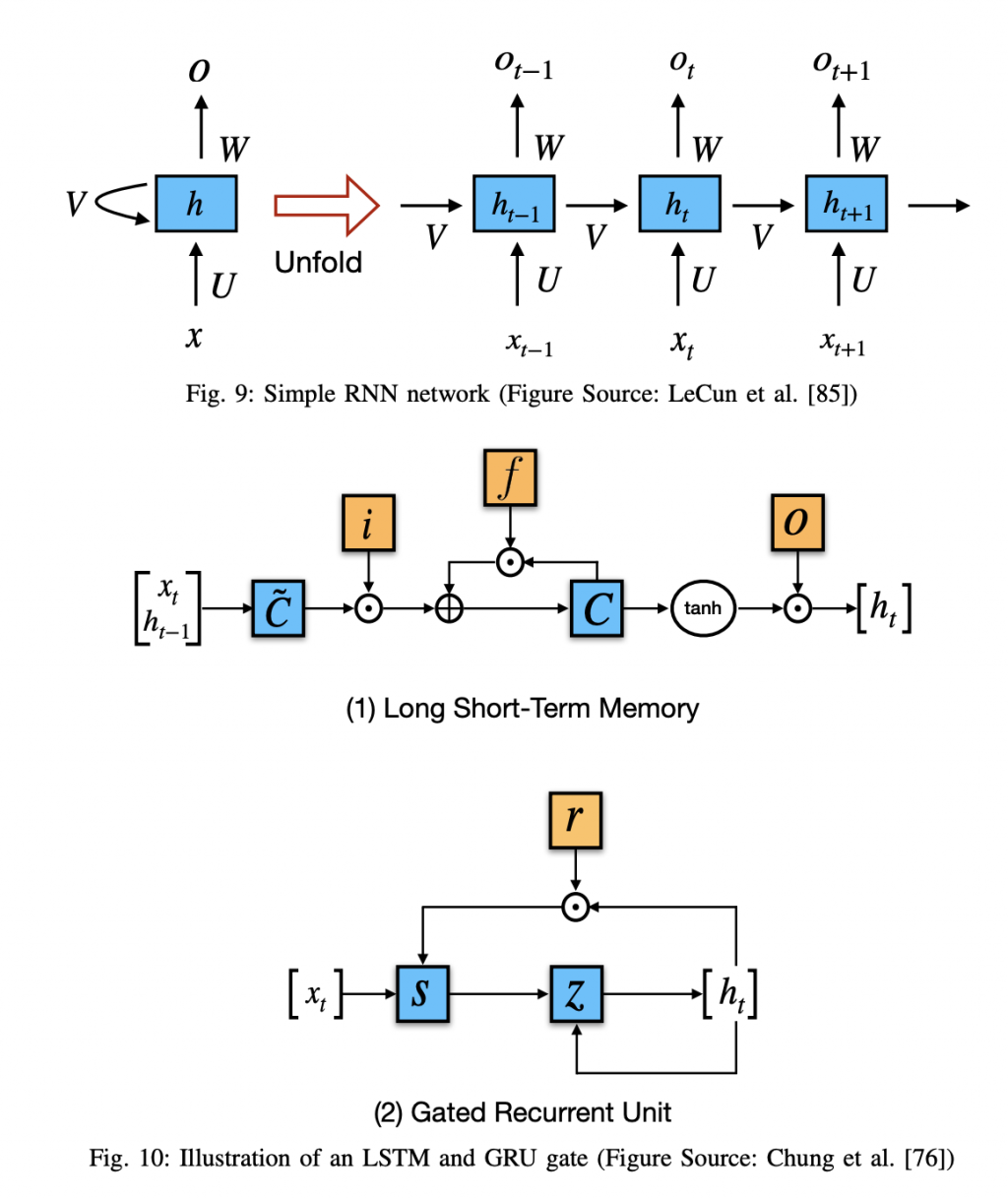
圖片來源:論文《Recent Trends in Deep Learning Based Natural Language Processing》
圖片來源:論文《Recent Trends in Deep Learning Based Natural Language Processing》
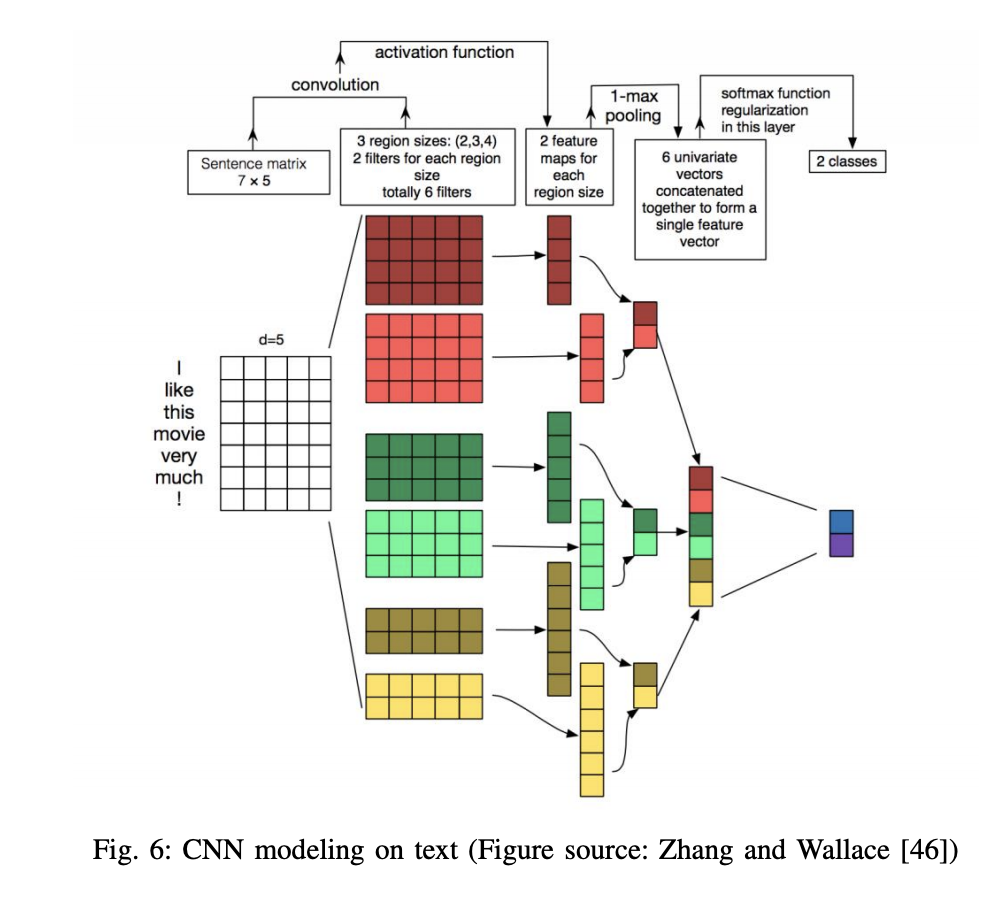
莉森之喃喃:曾用 CNN 處理文本分類的任務,實作的效果很不錯。
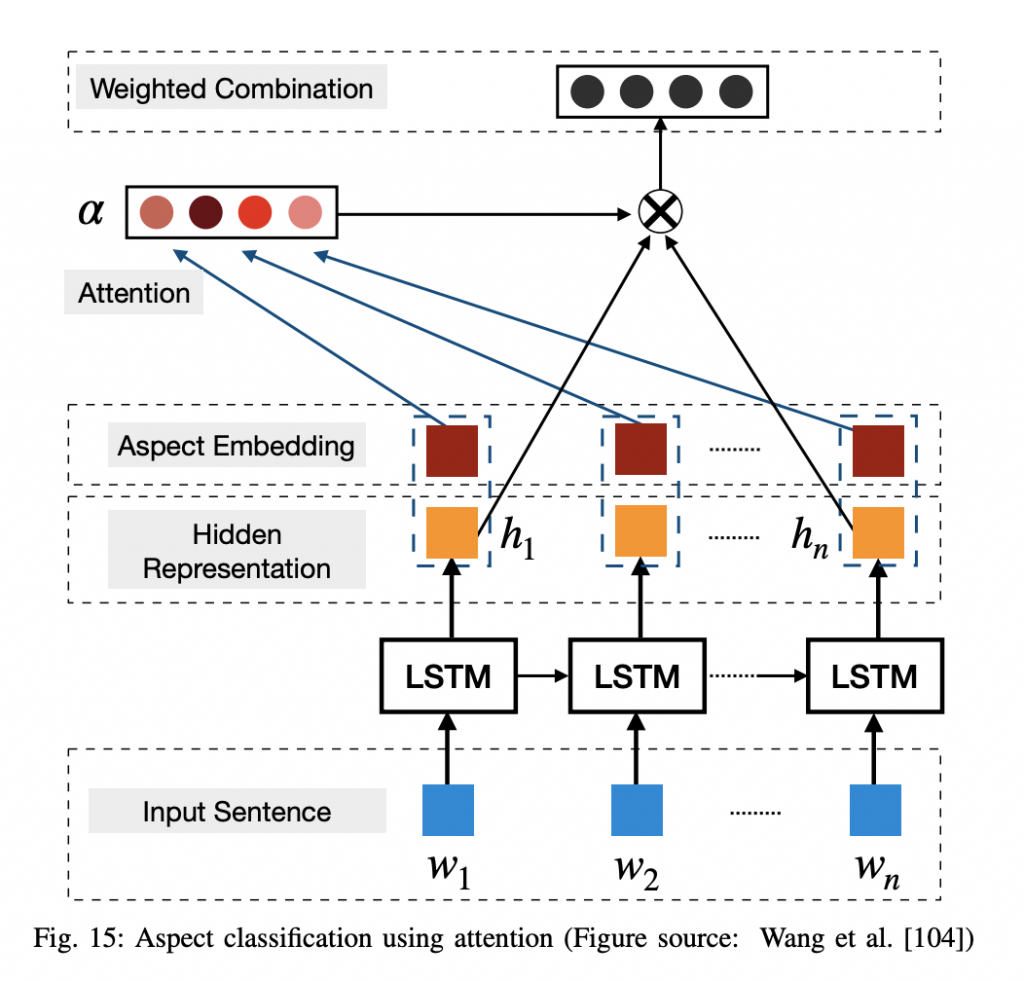
詞嵌入(Word Embeddings)→→→ 編碼(Encode) →→→ 注意力(Attend) →→→ 預測(Predict)
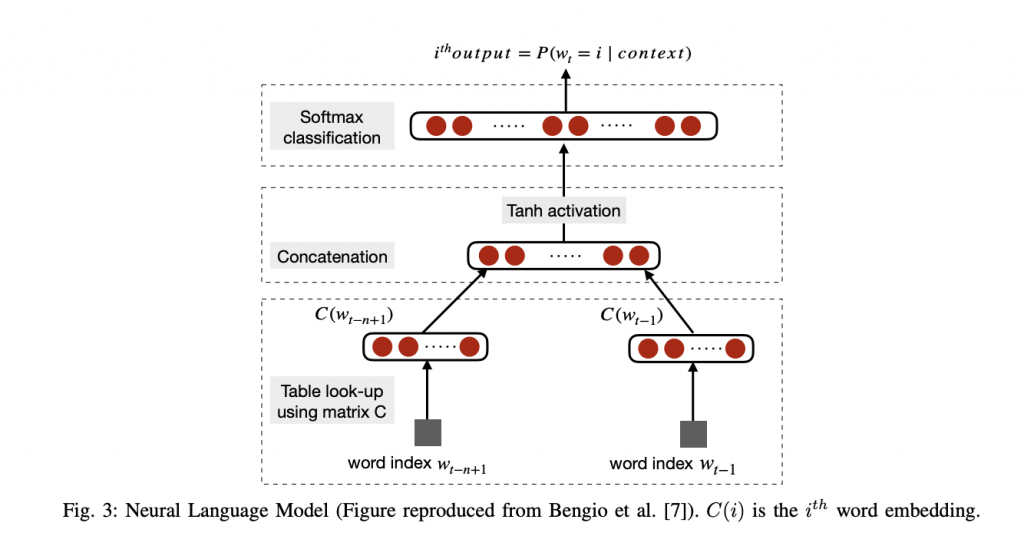
圖片來源:論文《Recent Trends in Deep Learning Based Natural Language Processing》
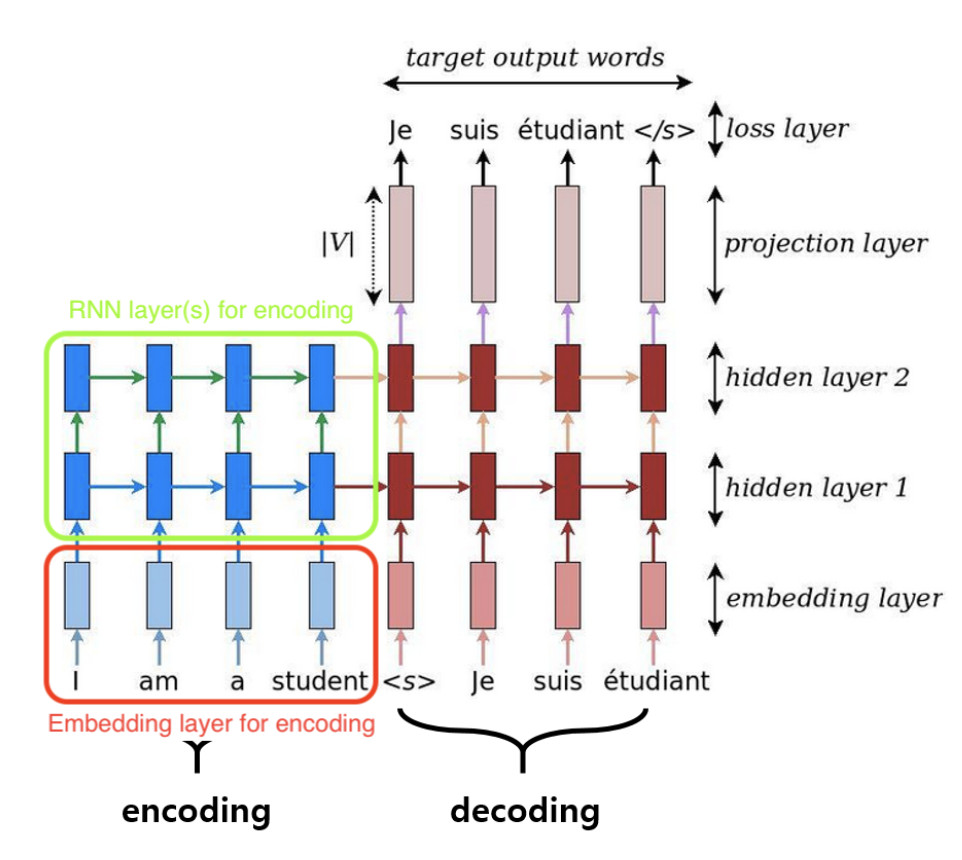
圖片來源:https://towardsdatascience.com/seq2seq-model-in-tensorflow-ec0c557e560f
圖片來源:論文《Recent Trends in Deep Learning Based Natural Language Processing》
呼~這一篇跟電腦視覺一樣花了非常多時間在寫,下一篇,也就是鐵人賽最後一篇了!一同來為「英雄集結:深度學習的魔法使們」系列畫下句點吧。