網頁爬蟲就是透過寫程式與網站溝通,以取得自己需要的程式,我們平常都是透過瀏覽器和網站做溝通,一般是從網址輸出後,伺服器收到並回傳原始碼經由網站轉為我們能夠閱讀的模式。瀏覽器會把網站回傳的資訊呈現給使用者,你可能會覺得沒必要多此一舉,但如果你常常需要取得網站最新消息,或針對不同網站做資訊比對,或是要從網站複製貼上大量資料,網頁爬蟲可能就可以更好的達成你的需求。
爬蟲就是爬蟲,他雖然小卻能看到我們平時所看不到的,我們可以在網頁中按 **F12 ** 就能看到類似爬蟲的視角。現在開始介紹怎麼使用 python 寫出網路爬蟲的程式。
先用系統管理員打開命令提示字元 (cmd)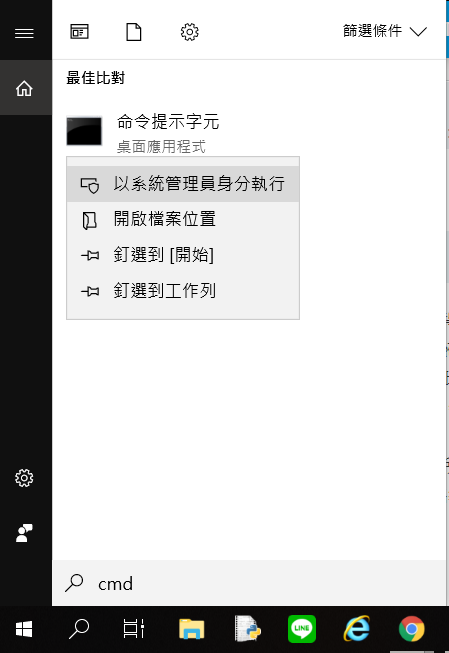
接著輸入 pip 查看你的 python 安裝了哪些套件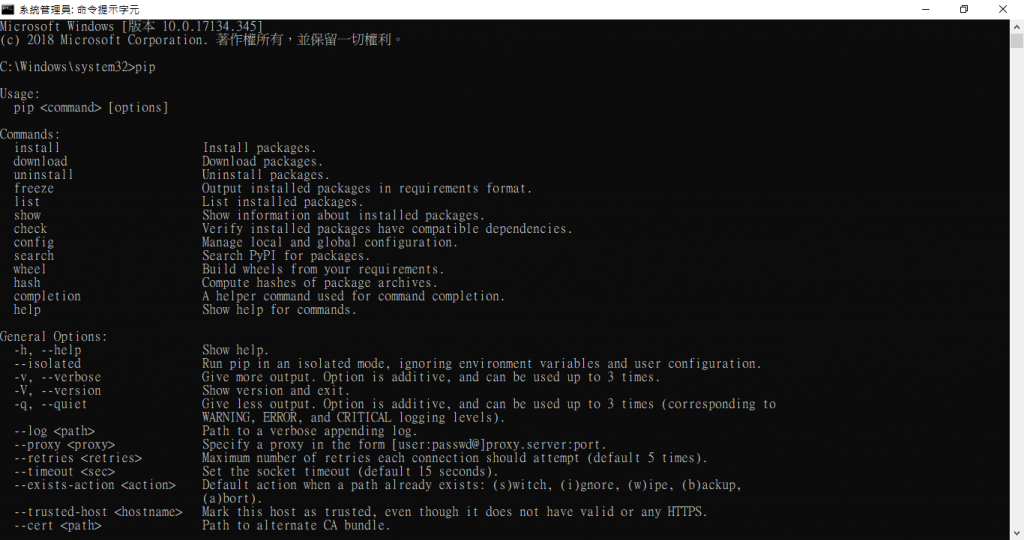
這裡需要安裝 requests、BeautifulSoup4 套件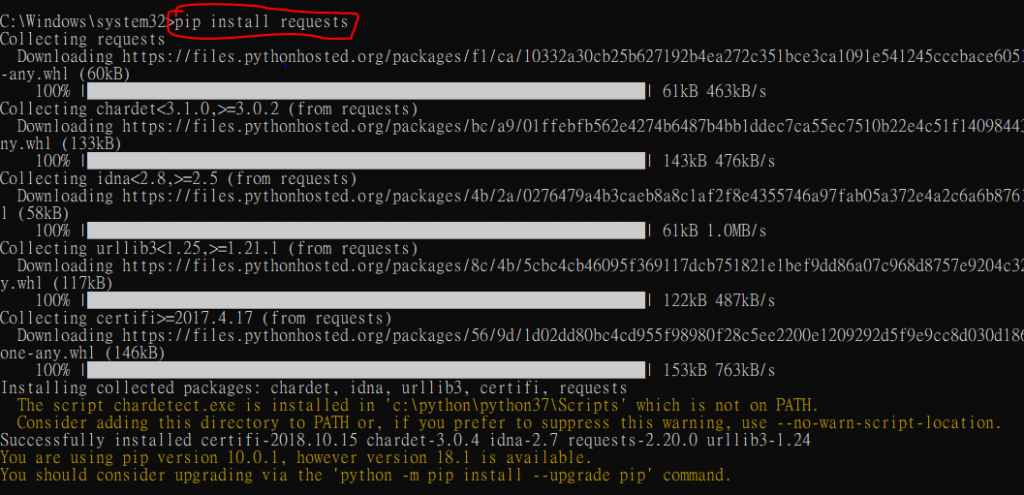

要怎麼知道你下載安裝套件有沒有成功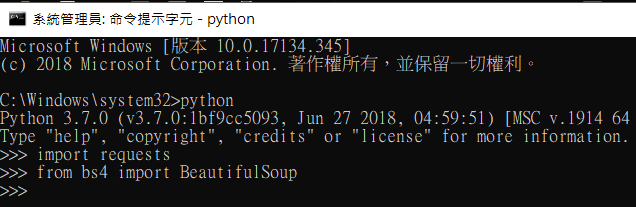
輸入完成沒跳出錯誤訊息就是成功了
準備好了就開始用 python 來抓取網頁內容吧,這邊我是用維基百科做測試
先 F12 進入開發人員工具後點 Network 並重新整理後你會看到一串資料,我們找到最頂端的資料並點擊去取得 url。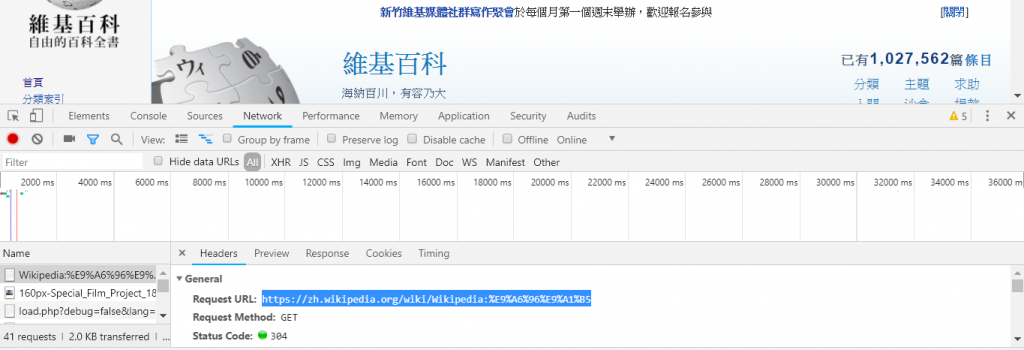
並進入 IDLE 輸入這段程式碼,將 url 貼上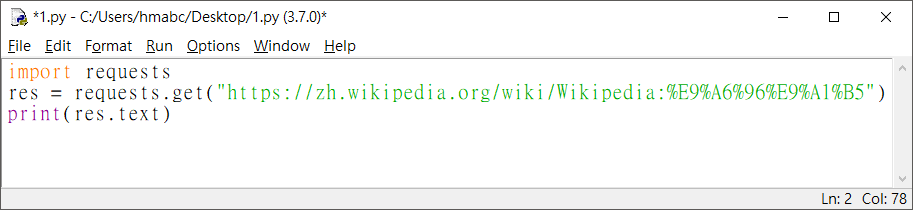
你可以看到整個網頁的程式碼了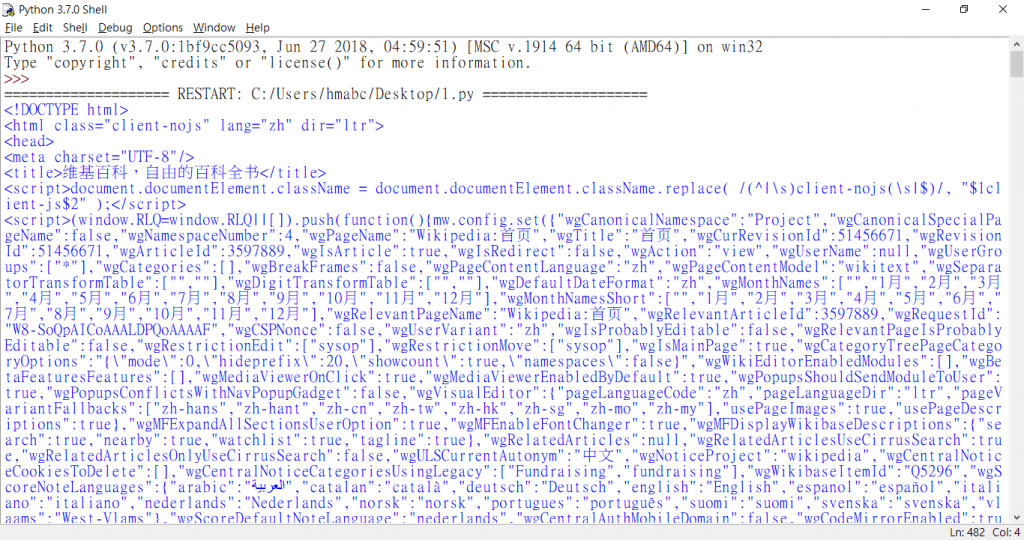


 iThome鐵人賽
iThome鐵人賽