類神經網路學門中,除了感知器所用的人工神經元,另外一個由生理現象引發靈感的網路結構,則是 1989 年由 Yann LeCun 所提出 Convolution Neural Network(CNN)。該網路的靈感來自於靈長類的視覺成像的原理,在腦後方的視覺皮質,在接受光線刺激時,並非所有的視覺細胞都會激發,相對的,每一視覺細胞都只負責接受區域性的訊息。
區域性的連接(Local Connectivity),在生理上被稱為 receptive fields,是 CNN 中與傳統的 Feed Forward 類神經網路最大不同的地方。見下圖,可以看到兩種不同的類神經網路架構的分別。
圖一:上圖為一個常見的三層 Feed Forward Network,而下圖則為由三層 convolution layer 構成的 convolution network。
可以看到比起 Feed Forward Network 來,CNN 的權重參數只負責一小部分的局部區域,而達到 sparse connection 的目的。這在電腦視覺中,一張影像動輒有幾千萬像素,傳統使用在 Feed Forward 網路的 fully-connected layer,會造成參數過載的情況,而使類神經網路訓練困難。
另外一個區域性的連接連接的好處,則是透過訊號處理中經常使用的 convolution operation,而達到萃取偏移不變的特徵。convolution operation,在訊號處理上,可以視為使用一個固定函式來作為訊號擷取的取樣訊號。這常見的函式通常是一個固定週期的 step function,持續對欲取樣的 1D 訊號中擷取訊號。
雖然 convolution operation 最初是應用在 1D 的訊號上,但 CNN 所處理的輸入是影像,若是灰階影像則為 2D。但和 1D 訊號中使用同一取樣函式有異曲同工之妙,為了能對影像進行 2D 的 convolution operation,會使用 parameter sharing 的方式來偵測影像在不同位置中具有相同特性的特徵。
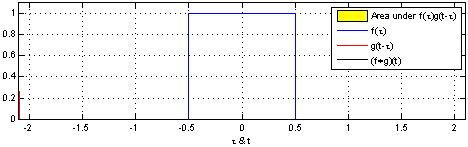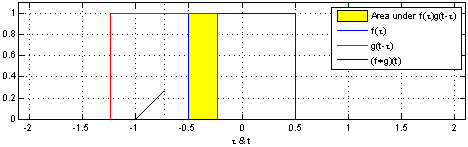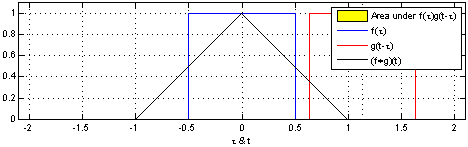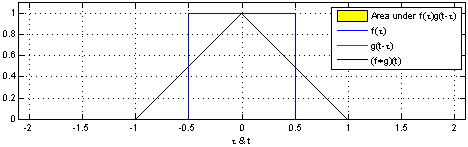
圖二:圖解如何用 step function 對 1D 的訊號 apply convolution operation 作取樣。
但若為 RGB 影像,CNN 的輸入則為 3D,因為除了影像的長度和寬度外,尚有 RGB 三個 Channel 形成的深度(depth)。此時,所使用的 convolution operation 仍舊是 2D,而原因應當是 RGB 的深度,可以看做物件在成像時不同的 raw 特徵,所以在進行 convolution operation 的時候會透過如 fully-connected layer 的方法,將 raw channel 映射到更高維的特徵表現中,那也就是為什麼,CNN 的架構總是如下圖會逐漸加深深度,其原理就和 Feed Forward 網路在上層使用更多的神經元以捕捉更微細或抽象的特徵。
圖三:上方為一個常見的 convolution network 架構的示意圖,下方則為一個 convolution layer。對於一個convolution layer 經常的需要 apply 不同的 filter 而萃取不同的訓練實例中的部分特徵,而造成 output volume 逐漸變深的情況。
另外一個在 CNN 架構中常見的則是 pooling layer。Convolution operation 負責 scan 影像,以萃取影像中局部的特徵,然而真正的偏移不變性,仍需要透過 pooling 的方式對萃取出的局部特徵作 reduction,而得到影像不同位置中共享有的特徵,常使用的 reduction function 有 max 或 average。
在 pooling layer 中,除了對經過 convolution operation 萃取出的 feature map 或 output volume 取出局部特徵中最具代表性的單一特徵值,而具有如訊號處理中抑制雜訊的作用,同時也進行 dimensionality reduction ,所以 pooling layer 的輸出,其截面必定會縮小,而深度則維持不變。
圖四:上方為一個常見的 convolution network 架構的示意圖,下方左則為一個 max pooling layer,下方右則為一個 average pooling layer。pooling layer 並不會對 output volumen 的深度有任何影響,但會縮小 output volume 的截面積。
Convolution layer 的實作細節:
圖五:對原影像做 padding 的示意圖,在這裡是 "same" 的 padding 模式。圖下方,則是一個簡單的 3x3 灰階影像(下方左),經過對上下左右 padding 兩個 0 值之後的變為 7x7 的灰階影像。
圖六:對一張 5x5 的影像用 3x3 filter 做 convolution,原影像不做 padding 的話,經過 convolution 得出的最後 feature map 會縮小至 3x3,如圖所示。
這就是今天關於卷機網路的閃電秀,那麼卷機網路和瑞士卷倒底有沒有關係呢?嗯,除了只有愈捲愈長的共同點,單純就是筆者貪吃甜食而已。

