Ref.: Embeddings
昨天講到把同類型文字歸類在一起,已降低dimension space,實在是非常抽象,建議大家直接操作這個網站,可以有更直接的感覺。文章出現的解釋圖也很直覺:
說明了文字可以照性別分類、是動詞的話也可以照時態分類、或國家跟首都分類,讓每一類放置在附近,並透過方向及距離給予他們適當的意義,以增加關聯性。
除了要考量embedding space是否足夠讓我們訓練model,還要考量embeding space是否可以保留適當多的原始資訊。或許embedding space需要到百位數的dimension,但也比把每個word這種數十萬量級的資料當成input送進model還要好。
Embedding就是個矩陣(N*M),N是多少個字(可能是百萬級),M則是最後要變成多少維度,Embedding[i][j]就是第i個字在mapping到embedding space j時的weight。每個字都有自己的稀疏矩陣,來跟Embedding對應,就會得到各自的dense vector,最後在把他們集合在一起就好(當然如果有每個字的數量,也可在集合之前先乘進dense vector)。
在lookup的過程,就像是矩陣相乘,一個稀疏矩陣S維度是1*N,乘上維度是N*M的Embedding矩陣E,最後得到的1*M的dense vector,
這邊就要講到Embedding矩陣E怎麼來了。有很多常見的演算法,這些演算法都可以套到Machine Learning去進一步學習。像是**主成分分析principal component analysis (PCA)**就可以把高度相關的字詞歸類在一起。
Google也發展了一種**Word2Vec演算法,根據分布假說distributional hypothesis**,這個的主要概念是有同樣鄰居的文字應該就有相似的語意。
語言學家John Firth曾說過"You shall know a word by the company it keeps".
白話一點:看字先看他的樣子
Word2Vec把文字轉換成有上下文資訊的樣子,並把它傳遞給Neural Net訓練,透過隨即把文字group在一起去分辨實際共同出現的群體。input會是target word的稀疏矩陣,並把一個或多個的文字也一起輸入,最後這個input跟一個小小的hidden layer連在一起。
Positive example: "the plane flies"
Negative example: "the jogging flies"
Positive example: (the, plane), (flies, plane)
Negative example: (compiled, plane), (who, plane)
歸類不是重點,重點是歸類完你就可以得到embeddings。embeddings可以降低維度,在丟進model去train。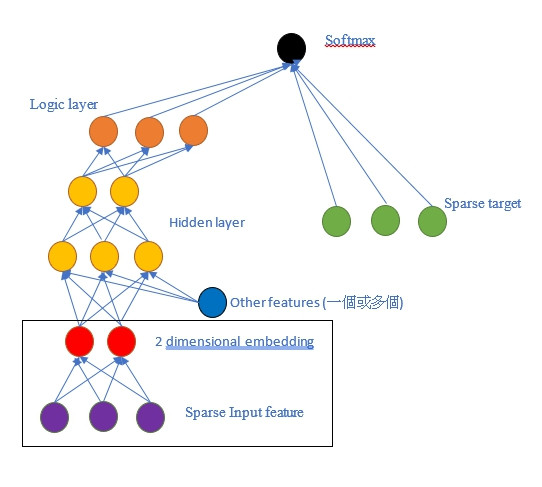
重點就是左下角的embedding layer,就好像其他hidden layer一樣,得出來的東西就是dense vector了。
這個練習主要是利用categorical_column當成feature column去訓練Linear Model,或更進一步將categorical_column轉換成indicator_column or embedding_column去訓練DNN,我覺得這部分的重點有兩個:
概念文章到此結束啦!! 明天開始會有四部影片的閱讀心得(?!)


 iThome鐵人賽
iThome鐵人賽