我知道昨天早上文章的收尾是說今天要繼續談內迴圈,然後要做中文文字雲。但經過了重新編排和改寫後,在36小時後的現在決定,為了順序上比較完整、加上讓系列文談到的涵蓋範圍更多,預計剩下來的5天編排是這個樣子:英文文字雲使用外迴圈2天、中文文字雲先使用外迴圈再使用內迴圈共3天。
因為小馬我前兩天努力趕了點進度,然後壓縮了一下原本要講中文文字雲內迴圈的部分。原本是打算30天只能講完內迴圈的應用,不過擠了一下,現在多出了4天,發現這樣就可以把外迴圈的例子給舉上來。畢竟這才是小馬認為的「迴圈處理的精華」啊!看看那精美猶如工廠般的外迴圈製作流程圖!
這個系列文,將會給各位帶來滿滿的,大!數!據!......(!?)
英文的處理,非常適合拿來說明外迴圈的處理概念。當然,針對這個處理,並不是非得用外迴圈來做,畢竟這方式看起來很麻煩,只是因為它在說明上相較簡單,所以被我拿來當例子示範外迴圈。一旦外迴圈學通了,肯定會有一種如武俠小說中打通任督二脈的暢快感。
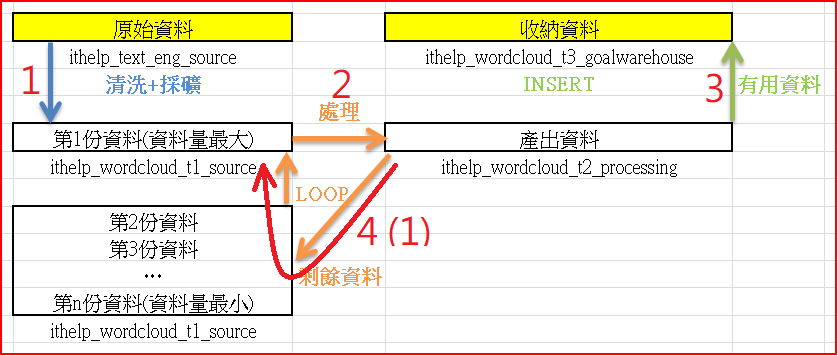
在正式進入資料之前,我先以上圖搭配簡單的範例做說明:
清洗資料
原始資料(ithelp_text_eng_source):【Is it good to drink?】
去掉問號、全換小寫後,存成t1。
t1資料(ithelp_wordcloud_t1_source):【is it good to drink】
處理資料
t1資料(ithelp_wordcloud_t1_source):【is it good to drink】
找到第一個空格位置,STRPOS(text,' ') = 【3】
將【is】和【it good to drink】切開,存成t2。
t2資料(ithelp_wordcloud_t2_processing):【3】、【is】、【it good to drink】
收納資料
將
t2資料(ithelp_wordcloud_t2_processing):【is】
收進
t3資料(ithelp_wordcloud_t3_goalwarehouse)裡。
重建t1
砍掉t1,將
t2資料(ithelp_wordcloud_t2_processing):【it good to drink】
建成
t1資料(ithelp_wordcloud_t1_source):【it good to drink】
重複步驟2,3,4,
此時步驟2的t1資料(ithelp_wordcloud_t1_source)已經變成【it good to drink】,而不是原本的【is it good to drink】。持續做好幾次之後,t3資料(ithelp_wordcloud_t3_goalwarehouse)裡,就會陸續收進:is、it、good、to、drink。如下圖所示: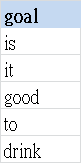
接著你只要select goal,SUM(1) from t3 group by goal,文字雲的底階資料就誕生了。你也可以想像,當一篇文章一直重複出現某個單字時,group by後的sum(1)就會越多,對吧?
而外迴圈,就是將4(1)->2->3寫成迴圈裡面的query,依序執行。以下先暴個明天的劇情雷:
--t1
DROP TABLE IF EXISTS ithelp_wordcloud_t1_source;
CREATE TABLE ithelp_wordcloud_t1_source as
select next_target target from ithelp_wordcloud_t2_processing;
--t2
DROP TABLE IF EXISTS ithelp_wordcloud_t2_processing;
CREATE TABLE ithelp_wordcloud_t2_processing as
select *,
STRPOS(target,' ') tag,
LEFT(target,STRPOS(target,' ')-1) goal,
SUBSTRING(target,STRPOS(target,' ')+1) next_target
from ithelp_wordcloud_t1_source;
--t3
INSERT into ithelp_wordcloud_t3_goalwarehouse
select goal from ithelp_wordcloud_t2_processing
where goal is not null and goal not in ('') and tag > 0;
簡單來說,就是將上面這一串,完整塞進迴圈的query位置。
暫時看不懂也無妨,明天會有更深入的說明。
相較於內迴圈,外迴圈有個極大的問題,在於,一剛開始,不會知道要跑幾次、要跑多久,因為第二份資料開始,都必須等前面資料處理完才能得知。不像內迴圈,在跑完t1時,就已經得知整個內迴圈的範圍是多少(例如昨天內迴圈文章舉例的關聯分析17種商品),可以直接指定這個範圍(17)去進行迴圈。
插個題外話,以現在這個英文文字雲的例子,當然我們可以預先算出要計算到第幾個空格,那是因為這個例子相較簡單(才被我拿來當範例),但在大多數使用外迴圈處理的資料裡,幾乎沒辦法預先計算要跑到哪個範圍;同理,內迴圈能不能用控制項?當然可以,只是內迴圈的處理,之所以稱「內」迴圈,表示這個迴圈範圍是已經被人得知的,經驗上就會直接指定變數,讓迴圈跑完某個範圍,而不會再寫成控制項。
所以,針對外迴圈,我們必須壓上一條控制項,簡單說,就是控制【什麼時候要跑、什麼時候不跑】的條件。將我們的判斷過程細細來看:
- 判斷空格位置(3)
- 將資料拆成【收納資料】(is)和【剩餘資料】(it good to drink)
什麼時候會開始沒有【收納資料】?就是沒有空格的時候。當剩餘資料只剩下【drink】,空格位置是【0】,不再有收納資料出現。就是這時候,讓迴圈不要再繼續跑。因此,我們先設計一個這種條件的function,在之後迴圈中,我們可以加上這個條件,去控制整個迴圈的終點。
再插個題外話,事實上,如果你看這篇沒有想睡覺,你會發現一件事,就是如果我們在0的時候就停下來,那麼,drink這個字只會是剩餘資料,而永遠無法變成收納資料。那最後你的goal,就會少掉drink這個單字。該怎麼辦呢?明天一併解決這問題!
建置ithelp_wordcloud_1():
DROP FUNCTION IF EXISTS ithelp_wordcloud_1();
CREATE OR REPLACE FUNCTION ithelp_wordcloud_1()
RETURNS INTEGER as
$BODY$
BEGIN
RETURN ()
END
$BODY$
LANGUAGE 'plpgsql';
這個function,和前面提到的都不一樣,前面提到的是要跑出整份資料,但這裡,我只需要跑出一個整數,而這個整數是0。所以第三排的RETURNS後面接的不是SETOF某table,而是INTEGER。
至於BEGIN...END的中間,實際要RETURN什麼,才可以讓它是0?就是明天的功課了。今天只先闡述,外迴圈是在處理什麼工作、如何停止外迴圈。為了順序上的建置較容易讓各位理解,明天會一步一步從頭來過,咱們明天見。
上一篇:
SQL迴圈實作 -5.關聯分析的處理工廠3
下一篇:
SQL迴圈實作 -7.英文文字雲的處理工廠2

