Recurrent Neural Network(RNN)是神經網絡的一種,常應用在處理時間、空間序列上有強關聯的訊息,尤其在 NLP (Natural Language Processing,自然語言處理)領域上,RNN 更是參與了重要的一角,有趣的應用如語音識別、翻譯、描述照片、作曲等等。
本篇主要參考這篇經典文 Understanding LSTM Networks 講解的以下三個魔法陣: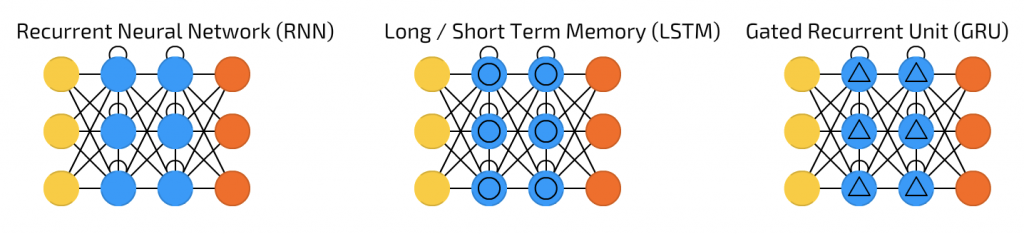
截圖自 [地圖] 深度學習世界的魔法陣們
Recurrent Neural Network(RNN)
基於我們在閱讀文章時,是根據對上下文來理解文章意義,RNN 的概念在於將狀態在自身網絡中循環傳遞,因此可以接受更廣泛的時間序列結構輸入,允許訊息持續存在。
下圖為一個簡單的 RNN 結構: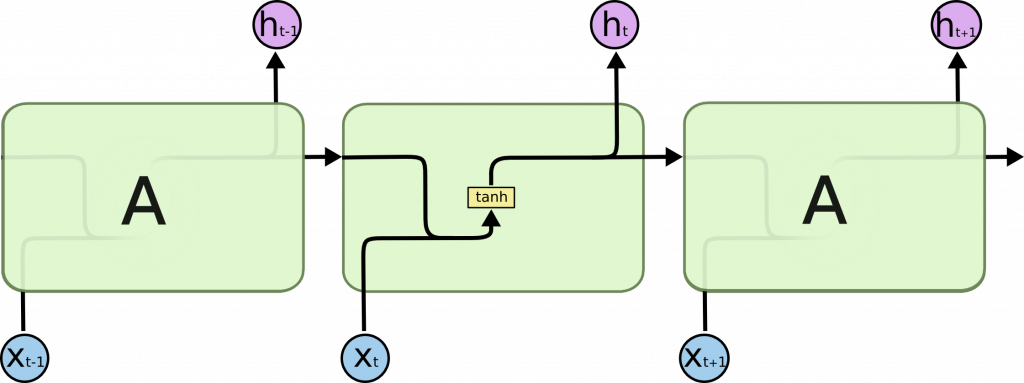
但 RNN 有其缺點:無法捕捉長期時間(當序列的距離太大)之間的關聯。簡單的 RNN 結構無法處理隨著遞歸權重指數級爆炸或消失的問題(Vanishing gradient problem)。
Long/Short Term Memory(LSTM)
先插播接下來結構圖符號的意義:
基於上述 RNN 的限制,可以透過 RNN 的變形,也就是 LSTM 來解決。LSTM 的特色是能夠學習長距離的依賴關係(Long-Term Dependencies),它不同於 RNN 有個單一的神經網絡層(tanh),而是有四個層,以特別的方式進行溝通,如圖: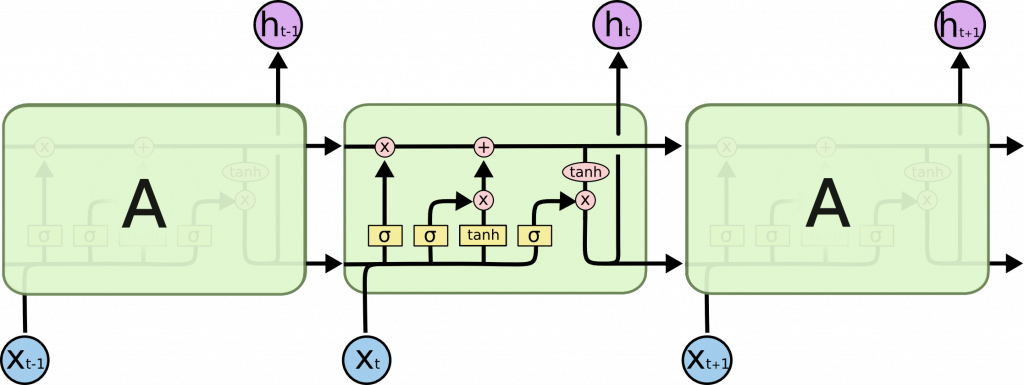
LSTM 核心關鍵在於 Cell State(單元狀態),沿着整個鏈運行,如下圖: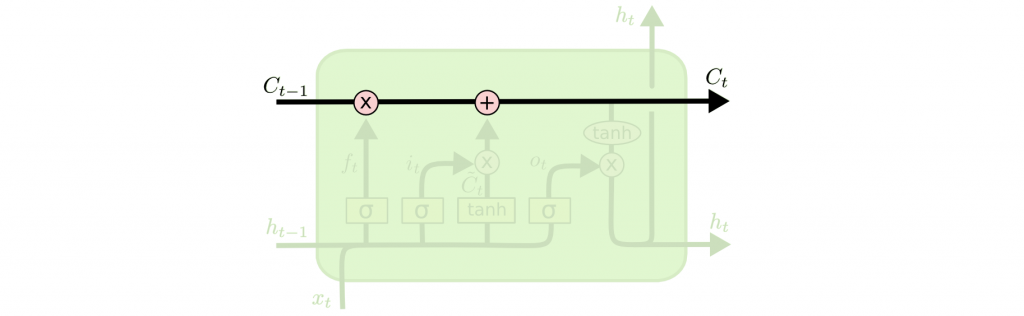
LSTM 可以增加或者删除單元狀態中的訊息,這些訊息經過 Gate 的結構所處理,選擇性地控制訊息通過,依照處理順序說明如下:
Forget gate layer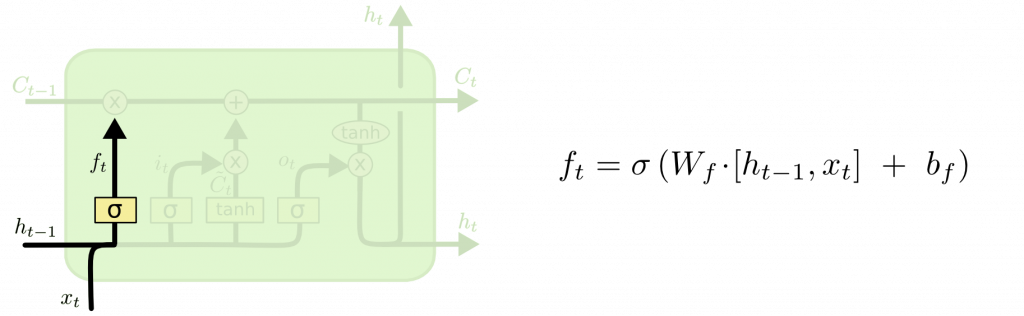
第一步:決定要從單元狀態中丟掉什麼訊息,所以稱為遺忘門,由激活函數sigmoid決定。
Input gate layer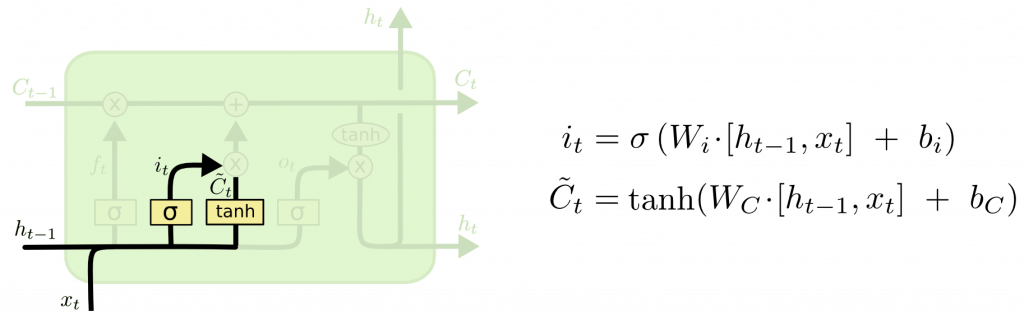
第二步:決定要在單元狀態中儲存哪些新的訊息,又分成兩部分:
sigmoid決定更新哪些值。tanh創建新的向量可添至單元狀態。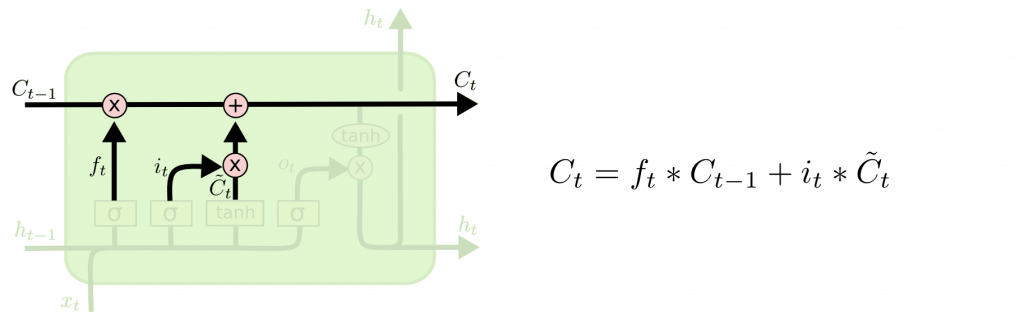
Output gate layer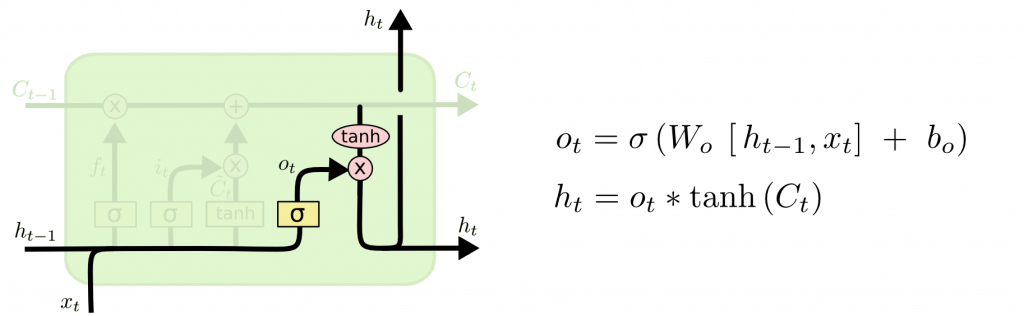
最後一步:決定輸出的内容。首先透過sigmoid層決定要輸出單元狀態的哪些部分,然後透過tanh函數(把值轉換為 [-1,1] 區間),把它的單元狀態與sigmoid的輸出相乘,因此決定最後輸出的部分。

以上就是 RNN/LSTM/GRU 的介紹,LSTM 對於 RNN 來說是一大邁步。而在本篇參考的文章末段提到:
LSTMs were a big step in what we can accomplish with RNNs. It’s natural to wonder: is there another big step? A common opinion among researchers is: “Yes! There is a next step and it’s attention!”
因此,後續預計介紹 Attention 機制,以及引入此機制後解決了怎麼樣的問題。
傳送門來也:[魔法小報] Attention 機制的引進
雖然近期有新技術號稱可全面取代 RNN,甚至說 RNN 無用,但我個人認為,了解這些魔法陣設計的原理,以及為了解決本身限制因應而生的變形魔法陣,如 LSTM,這些是很有趣的,也許有一天你也能創造出屬於自己的魔法陣。

