物體辨識的三個主要問題:
在電腦視覺的研究中有三個主要的難題,分別是影像分類(Image classification),物件定位(Object Localization)以及物件偵測(Object Detection)。
這三個主要問題的差別可以由下面的課程投影片截圖來說明:
圖一:圖中左方描述影像分類的問題。圖片中間,則是物體定位問題。而圖片右方則是物體偵測問題。物體定位和偵測的任務時,會輸出紅色框框的 bounding box 來標注偵測到的物件位置。
影像分類中的輸出主要是一個二元分類器,其輸出是判定輸入的影像是否含有特定的物件。也可以建立一個多類別分類器,使該分類器的輸出為所有類別的預測機率,並取擁有最高預測機率的類別作為該物體的預測類別。
物體定位與物體偵測則是更進一步的標出物件所在位置,而物件定位與物件偵測不同的地方,在於物件定位的輸入影像為單一物件,而物件偵測的輸入影像則可能有零到多個物件。當物體偵測演算法偵測到物件後,會用一個矩形的 bounding box 來標注偵測物件在影像中所在位置。
這個 bounding box 有四個參數,分別為矩形中心的座標位置, bx, by 和矩形的長寬: bh, bw。如圖中圍住車子的紅色框框,或藍色框框所示。
一個多類別的影像分類器目標向量,為含有分類標籤編碼的一維向量,如,行人(C1),車(C2),摩托車(C3)和不含任何物件的背景,或未能偵測到物體的(C4)。影像的目標向量在屬於該類別的向量元素值唯一外,其他皆為零。
物件定位則需要輸出 bounding box 的四個參數, bx, by, bh, bw 的預測值。目標向量包括 bounding box 資訊的多維矩陣。
物體偵測的目標向量除了分類標籤編碼的一維向量還需加上 bounding box 的四個參數預測,如圖左的 7x1 的 y 向量,便是表示單一訓練例子的目標標示向量。該目標向量內每一個元素所代表的是意義,由上而下是:該偵測到物體的機率(pc),bounding box 的四個參數(bx, by, bh, bw),是 C1 的機率,是 C2 的機率,以及最後 C3 的機率。
在物體偵測輸出中,不含任何物件的背景圖案,其偵測物體的機率(pc)會為零,所以在這個情況下等同於 C4 背景,因此也不需要對 C1,C2,C3 做分類預測,更不需要標示 bounding box。相對的,若 pc 為不為零,則 C1, C2 和 C3 的分類預測機率是基於偵測到物體的可能性所計算出的 conditional probability,或 p(Ck|pc>0)。在這個例子中,k 為 1, 2, 3。
先計算 pc,再算出各類別的 conditional probability,屬於階層式預測的一種。
我們可以見到圖中 y 向量的下方,各舉了一個實例:下方左是一個車子的目標標示向量,右方則是一個背景的目標標示向量。因為,背景的目標標示向量中,並沒有任何目標該被偵測,所以 bounding box 的四個參數則可以任意填入不可能的數字(如:-1 等等),在圖中則以 ? 表示。
讀者讀到此難免疑惑,既然目標標示向量中的 bounding box 四個參數,事實上是代表一個面積,參數之間彼此依賴,不能各自獨立評量,那麼該如何對 bounding box 的預測準確度做評估呢?
在物體辨識中常用的一個 metric 為 Intersection over Union 或簡稱為 IoU。而 IoU 的計算可以見下圖:
可以看見上圖左中,為了要比較真正的(ground-truth) bounding box,和演算法預測出(predicted)的 bounding box,我們可以簡單的計算兩個 bounding boxes 的面積,並扣掉重複計算重疊的部份,以計算出聯集(Union)的總面積。而 IoU 這個 metric 則是計算重疊部分,或交集(Intersection) 在聯集中的比例有多少(上圖右)。
從上圖下中,可以看到不同的 IoU 大小對物體識別的能力做一個質性評估。但通常 IoU 能達到 0.5 已經算是不錯的預測,在 0.6 以上都會被考慮是比較嚴格的檢視條件。
在影像分類和物體偵測的競賽上,另外使用 Average Precision 和 Mean Aveage Precision (mAP) 作為評估模型的度量。
Precision 度量(分類器所回傳資料的比例,有多少資料標註正確)多用於在巨量資料中做搜尋,如使用 google 做字詞查詢,這個度量可以告訴模型建構者該模型的精準度,或以射箭比喻,Precision 是量測在射出的箭數中有多少箭是射中靶心。Precision 又可因為問題的困難程度,而決定使用前幾個最高預測機率的預測結果來計算 Precison,只要前幾個最高結果有涵蓋正確預測,便可以視為正確預測。如,比較分類器回傳的前五個最高預測機率結果,此 Precision 的變形計算又多簡寫為 P@5。
Recall 度量(在所有標註正確的資料中有多少比例,被分類器的回傳結果涵蓋),這個度量評量模型的正確度,或以流病篩檢為例,Recall 是量測在多少個患有流行性疾病的病患,有多少人是被成功檢測出。
透過取分類器的多少個最高預測,如 Top k 預測,k 為任一非零正整數,我們可以繪製一個考慮排名的 Precision - recall 曲線圖,並根據 recall 值的增加,計算出該曲線底下的面積。而此面積則稱為 Average Precision。
Average Precision 是評估單一預測物體的結果,平均多個物體的 top k 預測結果則被稱為 Mean Average Precision 多用於物體偵測中。為了能夠轉換 bounding box 四個參數實數比較成為分類器二元的輸出,我們可以將 IoU >= 0.5 的 bounding box 預測,視為預測器回傳一個正確的預測,反之則為錯誤。
了解物體定位和識別任務的輸出後,我們接著要介紹一個能即時做物體辨識的一個快速演算法,YOLO。YOLO 是 You Only Look Once 的簡稱,亦是關於 YOLO 演算法第一篇 paper 的標題。而比較起其他物體定位和識別的演算法, YOLO 之所以可以如此有效率並達到即時辨認的效能,在於這個演算法使用了以下幾個特點:
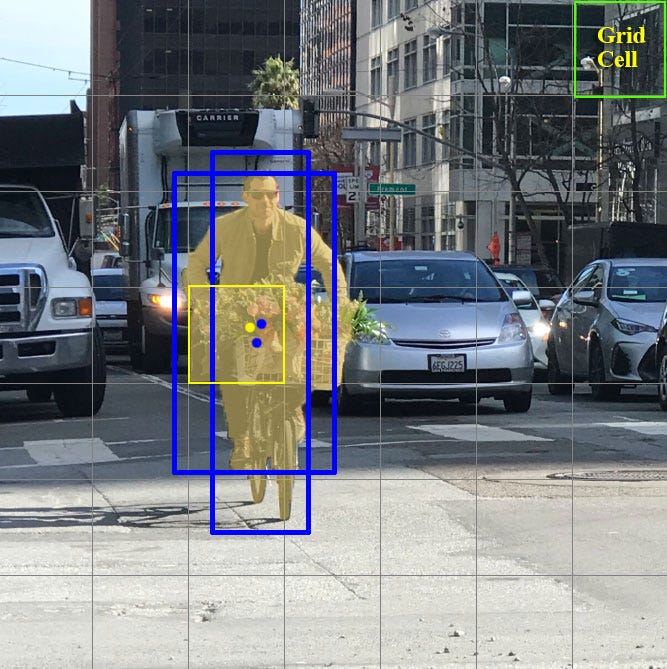
可見下圖看課程中所提到的實例:
圖中使用兩個 Anchor boxes,原先僅有 8 個元素的 y 目標標示向量(三個目標物件),現在為 2 x 8 的長度。前 7 個是對於 Anchor box 1 的目標輸出,後 8 個則是 Anchor box 2 的目標輸出。
在言簡意賅地說明了 YOLO v2 的精髓後,下篇中,我們將要介紹其他物件辨識的演算法,並與 YOLO 做比較。

