在介紹 Inception network 時,必須提到另外一個與 VGG 架構完全不同但在表現上一樣出色的另一個 convolution network ,則是由 Google 提出的 GoogleLeNet。和 VGG 架構相同的地方是,兩個網路都在追求深度上卯足全力,而和 VGG 架構不同的是,GoogleLeNet 還追求廣度。而在廣度上的實踐,GoogleLeNet 則用了 Inception Module,所以 GoogleLeNet 又經常被稱為 Inception Network。關於 Inception Module,我們可以見下面的 GoogleLeNet 示意圖捕捉其架構的輪廓。
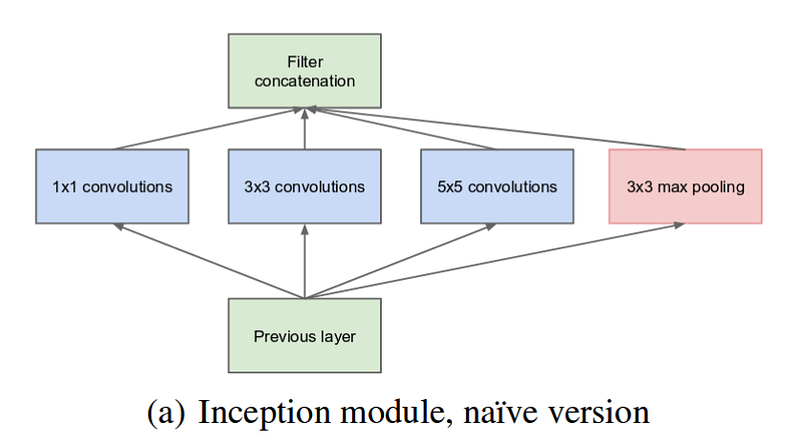
圖一:Inception Module v1
可以看到如同傳統的 CNN 架構, 往上堆疊具有不同功能的運算層,Inception Module 還在同一層中同時納入了使用不同大小的 convolution filter 的特徵萃取結果。在最初的 Inception Module v1 版本,總共使用了 1x1(same padding),3x3 (same padding),5x5(same padding)和 3x3 (max pooling, padding) 四種運算。然而,因為執行大於 1x1 filter 的 convolution operation 計算量過大,所以在這些 convolution operation 前又加了 1x1 convolution operation,而完整的 Inception Module 第一版的示意圖如下:
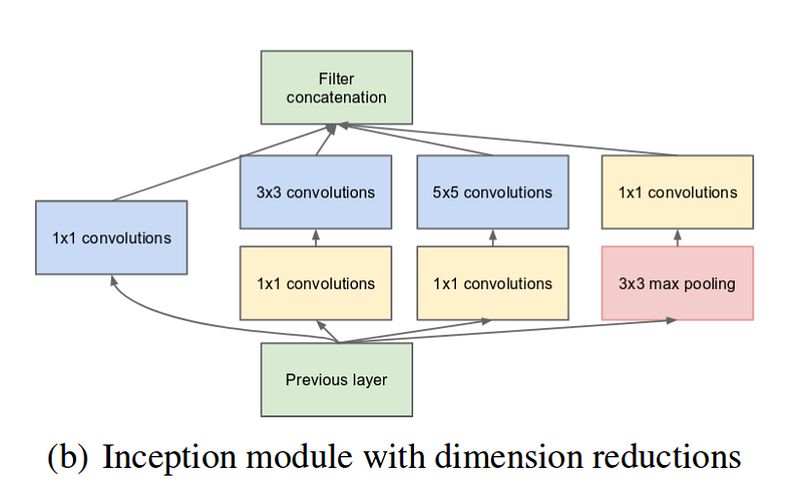
圖二:Inception Module v1 + 1x1 convolution
而 Inception module 在對同一個輸入同時進行這四種運算後,必須輸出與原輸入截面積同樣大小的尺寸,而總輸出 Channel 數則是將所有運算輸出的 Channel 疊加在一起,如下圖課程投影片的截圖。
圖三:Inception Module Filter Concatenation
那麼,1x1 convolution filter (在某些文獻中又被稱為 kernel) 在 Inception Network 中的角色倒底是什麼?在這之前,我們必須先瞭解 1x1 convolution 的功能。
所謂的 1x1 convolution 是指使用 1x1 的 filter,來對整張影像做 convolution operation。若對灰階影像或在 convolution layer 其輸入 channel 等於 1 的情況下,1x1 convolution filter 執行的是矩陣與純數值元素相乘的運算,但對具有多個 channels 的 RGB 影像或輸入 channel 大於 1 的情況, 1x1 filter 所執行的 convolution operation 並不只是單純的矩陣與純數相乘,而是對原輸入裡的橫截面中,每一個輸入點做如 fully-connected layer 的運算。可以見下圖解說:
圖四:1x1 convolution 只有一個 output channel 計算示意圖
上圖左是具有三個 channel 的 input volume, x,分別用 3x3 的矩陣代表每一個 channel 的橫切面,也就是矩陣代表式 x[:, :, i],i 可以為 0, 1 和 2 (index 為零,numpy 語法)。每一個 channel 在經過 1x1 convolution 的時候,其長與寬不會改變,但深度會將為 1,將所有橫切面與 filter 中的數值相乘後再相加,即為 1x1 convolution 的輸出 feature map。
倘若我們使用 output channel 數目不為 1 的 1x1 filter,就相等於對橫切面每一個空間位置做 fully-connected layer 的全連接線性映射運算,可以看下圖從課程投影片擷取下來的圖解。
圖五:1x1 convolution 多個 output channel 計算示意圖
可以看到如果1x1 convolution filter 只有一個輸出 channel 的話,就等同於對輸入深度為 D,截面上的點,也就是 x[h, w, :] 做 Dx1 全連接線性映射到 y[h, w, 0] 的位置。若有多個 output channel,C,則等同於做 DxC 的全連接線性映射到 y[h, w, :] 的位置上。
1x1 convolution filter 的作用在於降低深度,但不降低原輸入二維的維度情況下,降低計算量。在 Inception Network 中則擔任 bottleneck 架構的功能。何謂 bottleneck 架構呢?請見下圖課程投影片截圖。
圖六:1x1 convolution 作為 bottleneck layer
在一般 convolution layer,在輸入維度相當高的情況下,做 convolution 其計算量是相當大的,尤其在希望不遺失局部的細節,仍使用較小的長度的 filter 的情況下。如圖上方,在 28x28x192 的輸入中使用 5x5 的 filter,會達到 約一億兩千萬(~120M) 的運算次數。28x28x32 次的 5x5x192 矩陣元素相乘。但透過 1x1 convolution layer 引進 bottleneck 結構而達到降維的效果後,再執行 5x5 convolution operation,將會有效地減少所需的計算數目。可見圖下方,透過 1x1 convolution layer 減少了原輸入的 channel 大小,從 192 到 16,再執行 5x5 convolution operation 可發現總共的計算次數約為一千兩百四十萬(~12.4 M,1x1 convolution operation 需要約 28x28x16 個計算量再加上 28x28x32 次的 5x5x16 矩陣元素相乘),比起在原輸入直接執行 5x5 convolution 減少了將近 10 倍。
那麼了解了 1x1 convolution operation 對 Inception module 的功能後,我們再回頭看看擁有許多 Inception Modules 的 GoogleLeNet 的結構,見下圖。
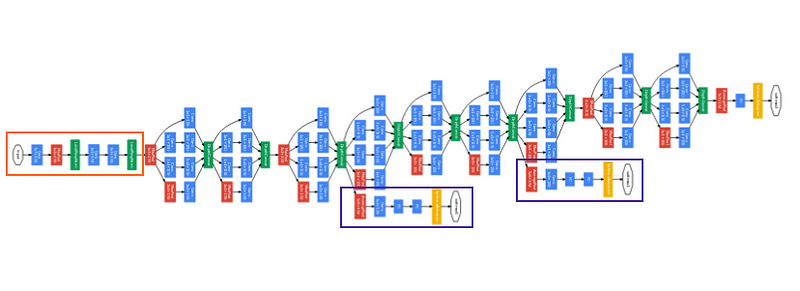
圖七:GoogleLeNet v1 完整架構
在這個初版的 GoogleLeNet 中,總共有 22 層可訓練的參數層(若加上 max-pooling layer 則為 27 層)。在網路的最底層,是一個傳統的 convolution network,被稱為 stem,用來計算最粗略的特徵擷取結果。
在 stem 上的網路架構,則用了九個 Inception module(在圖中,長出旁枝較寬的網路架構即為 Incpetion module)在這個初版的 GoogleLeNet 運用一種稱為輔助分類器架構,來解決 gradient vanishing 的問題。
這個輔助分類器,位於網絡的中間,其用途為先計算到至該層為止的 loss,在圖中則是用紫色線條框起來的部分,而實踐方式則是建構供分類使用的 fully-connected 和 softmax layer 的相似架構。而 GoogleLeNet 的總損失,則是主分類器和另外兩個輔助分類器計算出的損失和。
然而,關於 Inception 的故事並沒有完,事實上,它就如好萊塢電影般,一連出了四個 Inception 的版本。而在 Inception v4 中引進了 ResNet 的 Residual Blocks 而成了 Inception-ResNet。
在此以旋風式的方式,來快速的帶過 Inception 之後版本的變遷。
在架構上 Inception v2 改變最多,其原因是希望解決 1x1 convolution operation 降維過多的問題,在文獻中將此現象稱為 ”representation bottleneck”。為了解決這個方法,則設計了三種不同 Inception modules,但主要目的都是將 5x5 convolution operation 先拆成兩個 3x3 convolution operation(下圖左上),隨後再運用 factorization 的方法,使用非對稱性的 filters 來完成相同運算。而根據 filters 是垂直疊加或橫向擴張,則設計了下圖右和下圖左下的不同架構。
圖八:Inception v2 module
左上:將 5x5 convolution operation 拆成兩個垂直疊加的 3x3 convolution operations
左下:將 3x3 convolution operation 矩陣分解為 3x1 和 1x3 非對稱的 convolution operations,並平行連接
右:將 3x3 convolution operation 矩陣分解為 3x1 和 1x3 非對稱的 convolution operations,並垂直連接
在 v3 的部分則多為演算法和訓練方法的增進。
而 v4 的部分,在架構上的改變包括:
而 residual block 使用在 inception module 上的架構如下圖: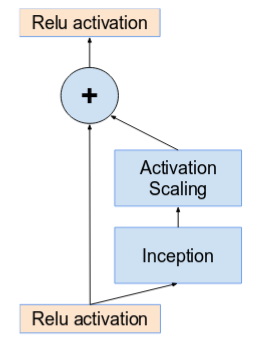
圖九:Residual block + Incpetion module (Inception v4)
可以看到 residual block 原本的 skip connection 會跳過整個 inception module,並且在上方增加了一個 activation scaling block,其功用類似於 regularization,為了防止 inception block 過多的參數而造成學習的困難。
到這裡, Inception 的故事似乎到了一個段落,然而關於電腦視覺的探索卻尚未停止。在下一篇幅中,我們要介紹 YOLO 演算法如何進行影像物體辨識。

