昨天的文章中,匆匆地帶過了 YOLO 演算法的重要精髓,但倒底 YOLO 演算法和其他的物體辨識演算法有何不一樣呢?首先我們讓詹姆斯龐德來告訴你:

為了能了解 YOLO v2 在物體辨識演算法設立的里程碑,我們必要先了解以往的物體辨識演算法的做法。
在 YOLO 之前,大多數的物體辨識演算法多用 Sliding window 來定位。我們以下圖的課程投影片截圖來圖解 Sliding window 演算法。
上圖上方投影片截圖,解釋進行物體偵測之前,會先對欲偵測的物體(在投影片中,車則是愈偵測的物體)做前處理,將目標影像中屬於偵測物體影像裁減成同樣大小,以影像分類的方式來做物體辨識。為了能增加物體辨識的準確率,通常也會增加一些非該物體的影像,如背景等。
但,通常在物體偵測的輸入影像中是含有多個物件,所以為了能搭配上述的物體層級的影像分類器且達到在原影像定位,傳統的物體辨識方法會使用 sliding window 演算法掃描原圖,每一個 window 都可以看做裁減過的影像,將會餵入物體辨識的分類器來做分類。
我們可以從下圖了解一張影像中可以同時擁有多個欲偵測的物體,如人,且每一個物體都有不同的大小,因此單一尺寸的 sliding window 將會遺失必要或添加不必要的特徵。
小的 window 將會無法偵測在影像中比 window 尺寸大的物體。相反地,過大的 window 則會包含太多背景資訊而增加了不必要的雜訊。所以由上圖下方投影片截圖,sliding window 演算法會使用不同尺寸的 window 掃描輸入影像,逐一對原圖做掃描。
然而,sliding window 在傳統的物體辨識盛行,在於特徵萃取預先設計好,而分類器都是以線性分類器為主。若要將 sliding window 的方法應用在 CNN 上,最簡易的作法,是為每一個尺寸的 window 剪裁下來的部分影像,建立一個 CNN 分類器來萃取該尺寸的特徵,並最終以類似投票的方式來決定該位置是否偵測物體。
然而這樣過於簡易的架構,會遭遇到訓練多個 CNN 的困難,而 2013 年由 Yann LeCun 的團隊所發表的 OverFeat 物體辨識演算法,為了解決這個困難,則使用 convoluional layer 的方法來實現 sliding window。
在這個方法中,先將 fully-connected layer 轉成 convolution layer,和平行計算較大影像中的不同位置。
上圖下將 fully-connected layer (包括 softmax 分類器)轉成輸出面積為 1x1 而 depth 則等同於 fully-connected layer 的輸出單位。 轉換的工作可藉著用與輸入 feature map 長寬尺寸相同的 filter 來完成。此步驟是為了使用 convolutional layer 節省重複的計算量。
上圖上,則是如何利用 convolutional layer 來節省 sliding window 方法重複的計算量。若最小的 window size 為 14x14 的輸入。我們針對這個輸入 widow size 建造一個將 fully-connected layers 都轉成 convolutional layer 的 CNN(上圖上的第一排)。
而若使用較大的 sliding window size (如 16x16,上圖上的第二排),會等同於使用 14x14 的 window size,用 stride 為一,在長和寬的各產生兩個 window 位置,或 4 個 windows(在圖中,為左上角用紅色箭頭註記,左下角用黃色箭頭註記,右上角用綠色箭頭註記,以及右下角用紫色箭頭註記)。
我們可以將這四個位置同時輸入以 14x14 尺寸訓練的卷積網路,並將預測結果視為左上,左下,右上,右下的物體偵測輸出。此一觀察,等同於使用 16x16 的輸入尺寸建構的卷積網路,並最後輸出 2x2x4 的預測機率。(上圖上的第二排,最後一個圖)
同理,對於 sliding window 尺寸大如 28x28(上圖上的第三排),亦可以視為同時對 8x8 個不同位置做以 14x14 為輸入尺寸的 convolutional network 計算。
在 OverFeat 的發表文獻中另外使用 multi-scale 的方法來做影像分類。Multi-scale 指的是將原整張影像複製並調整為不同尺寸的影像集。在傳統的物體辨識方法中,被稱為 “Multi-scale representation“ 或 ”Image Pyramid“,因為可由下圖可看出,當不同尺寸的影像相疊起,就如同一個金字塔一樣。(物體辨識的研究中另外有針對Image Pyramid 發展一個 Feature Pyramid Network類神經網路。)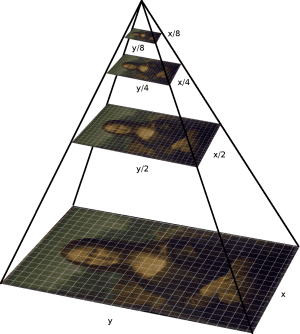
用 multi-scale 的方法來做影像分類,是因為 CNN 不能萃取出 scale-invariant 的特徵,所以需要對 CNN 分類器輸入不同尺寸的訓練資料集。
最後,我們要提到在課程中被當作補充教材,利用 Image Segmentation 的技巧,先對欲辨別影像做前處理後,才進行物體辨識,這類的方法被統稱為 Region Proposal,而代表性的演算法則是 R-CNN,Fast R-CNN 和 Faster R-CNN。
Sliding window 的方式會產生過多的訓練影像,需要高效能的長時訓練,因此電腦視覺的研究者們提出另外一種基於影像分割的演算法來偵測影像中含有物體的區域。
在傳統影像處理方法中,多利用由 Felzenszwalb 和 Huttenlocher 在 2004 提出的 graph-based 的影像分割法。在他們的演算法中,會將影像轉換成一個格狀的 graph,在這個 graph 之中,每一個像素為 graph 中的節點,在影像中相鄰的像素則有 edge 相連接,每個 edge 則有權重(weight)。權重的計算,則是基於 edge 兩端像素節點的色彩值,倘若兩端的像素節點的色彩值相近,會給予較低的權重,若相異,則給予較高的權重。
在建立這樣的 graph 後,採用 graph partition 的方式,找出該影像的格狀 graph 表示中,彼此相互連接的節點群聚(connected components),該節點群聚則為一個包含相似像素的 segment。
在經過影像分割後找到的 segments,通常無法立即應用在物體辨識上。所以需要透過 selective search 的方法,由下至上,以階層式的群聚演算法將分割得到的 segments 依照彼此的相似程度,聚合成一個矩形區域,並萃取出此區域內的特徵,餵入該物體辨識分類器,做物體辨識。
我們可以從下圖上看到影像分割後的結果,和下圖下則是將偵測到 region 用 bounding box 來表示之後的結果。而下圖左則是未經過 selective search 的 over-segmented 的結果,而中和右則是依序應用 selective search 聚合小區域而成為單一物體的預測。
R-CNN 為 Region-based CNN,便是架構在 selective search 的結果而建構出來的 CNN 模型。在 R-CNN 中先用 selective search 找出影像不同的區域,被稱為 Region of Interst (RoI),並將此區域的影像輸入至 CNN 來萃取特徵並進行分類和 bounding box 預測。
而 Fast R-CNN 和 Faster R-CNN 則是針對 R-CNN 的效率問題而進行架構上的改良。在 R-CNN 中需要多個 CNN 來做特徵的萃取,並對 CNN 萃取的特徵餵入對每一個物件分類建立的二元 SVM 分類器與 bounding box 回歸預測(regressor)
Fast R-CNN 以一個 CNN 取代多個 CNN 對 selective search 預估的 RoI 做特徵萃取,在 Fast R-CNN 中將 selective search 所找出 RoIs 投影到 CNN 的輸出 feature map 上,並使用 RoI pooling 的方式對投影 RoIs 在 CNN 輸出的特徵空間中做降維並輸出固定尺寸。在原影像中的 RoIs,經由 CNN 的特徵萃取後,可以將不同但重疊的 RoIs 投射到共享的特徵空間中,而減縮對每一個 RoI 做分類。
Fast R-CNN 另外一個架構上的改變則是用 softmax 分類器取代了二元 SVM 分類器們。
而 Faster R-CNN 則是捨棄 Fast R-CNN 中須分開且較費時的 selective search 演算法,以一個 Region Proposal Network (RPN) 來代替。RPN 的網路架構主要是一個卷積網路,並在卷積網路的輸出上加入兩層的全連接層所構成。該網路的輸入是 Fast R-CNN 的特徵萃取卷積網路輸出,而輸出則是該局部區域是否含有物體的預測機率和 bounding box 的位置。
為了能偵測不同大小的物體,RPN 採用 sliding window 的方法,亦即用 k 個不同長寬比的矩形 anchors,當作 sliding window 的 window 尺寸在同一個位置產生 k 個 RoI 預測。

相信讀者看到這裡,可以發現許多源自於 YOLO 的主意,都可以在其他的方法中找到異曲同工之處,接下來我們要介紹物體辨識的另一個應用,人臉辨識。
圖片來源:

