LightGBM (GB指gradient boosting方法) 使用基於直方圖的算法 。例如,它將連續的特徵值分桶(buckets)裝進離散的箱子(bins),這使得訓練過程中變得更快。LightGBM採用了對增益最大的節點進行深入分解的方法。這樣節省了大量分裂節點的資源。下圖是XGBoost的分裂方式。
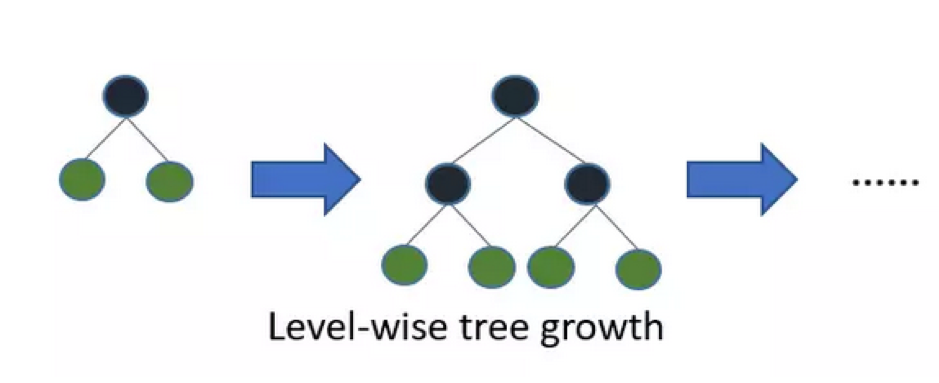
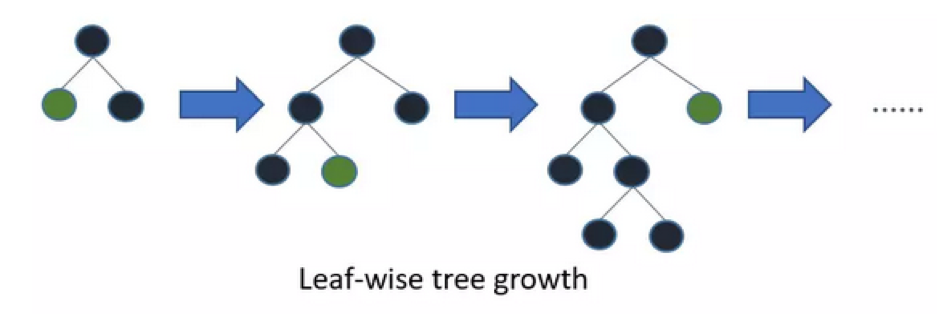
以下是LightGBM的分裂方式
其中離散數值的資料欄位宣告範例如下

在為LGBM構造資料集之前,應該將分類特徵轉換為整型integer。即使你通過categorical_feature傳遞引數,它也不接受字串值。
建樹過程上,leaf-wise分裂方法能產生比level-wise分裂方法更復雜的樹,能使得模型得到更高準確率。然而,它有時候或導致over fitting,但是我們可以通過設置 max-depth 參數來防止過擬合的發生。
和其他模型XGBoost, CatBoost, LightGBM的重要超參數比較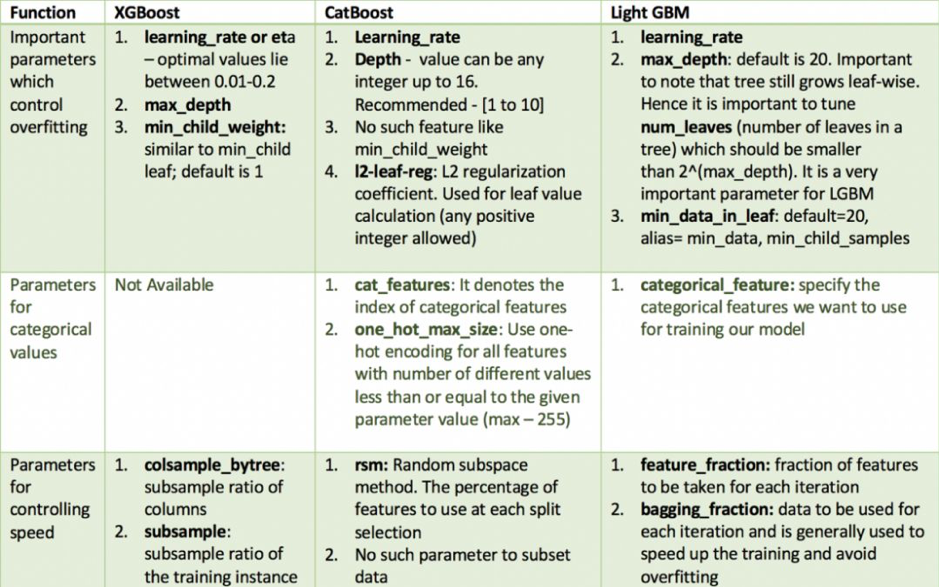
LightLGB核心參數
Boosting:也稱 boost, boosting_type 默認是 gbdt 。gbdt的效果比較經典穩定
num_thread:也稱作 num_thread , nthread 指定thread的個數。
Application:有regression, binary, multi-class, cross-entropy, lambdarank. 默認為 regression。
程式碼: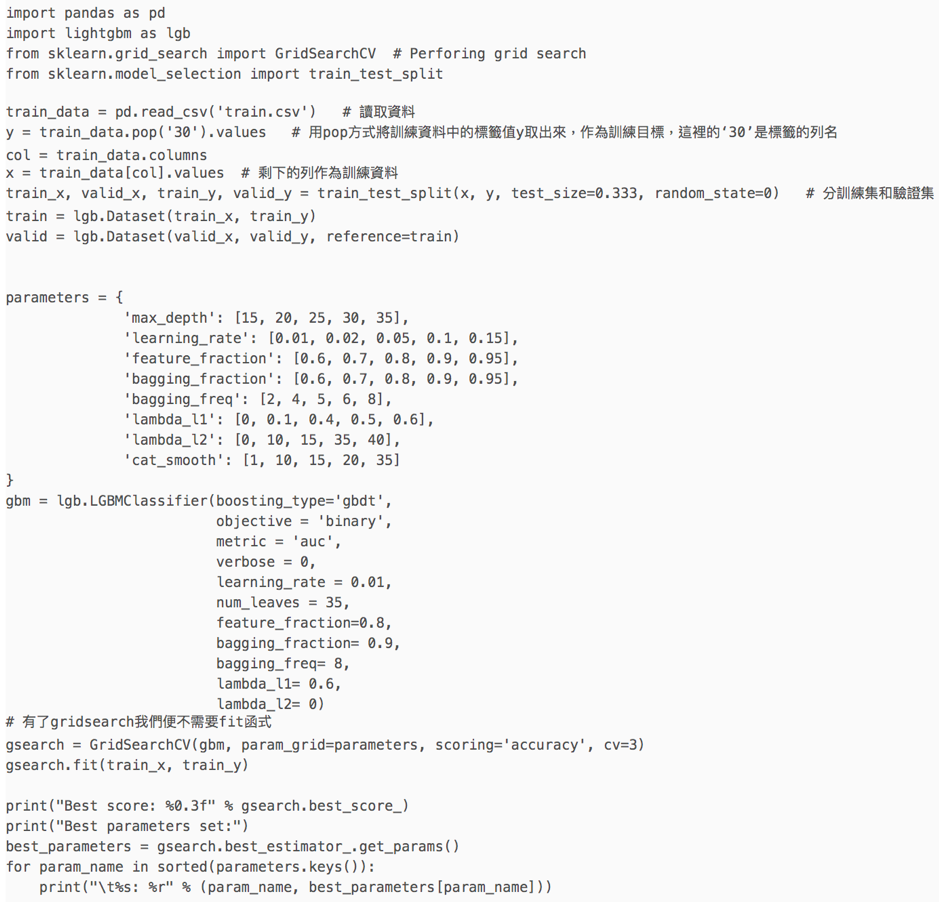
參考來源
CatBoost、LightGBM、XGBoost,這些演算法你都瞭解嗎?
https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/510420/
XGBoost過時了?LightGBM核心解析
https://hk.saowen.com/a/9d4cf70280f9a72a085ec7f7790b80654ca12cd52afcc3edcc9bc209d495c62d


 iThome鐵人賽
iThome鐵人賽