
Azure 的 Speaker Recognition API 可分為兩部分:分別為說話者的身份驗證(Verification),與說話者的身份識別(Identification)。
這項服務可以用來當作門禁系統等的驗證系統,說『 芝麻開門 』即可驗證身份,可以省去每次進公司都要刷指紋刷好多次又進不去的問題(但可能變成一群人在門外喊開門)。
1. 先到以下網站按下試用,並取得金鑰。
https://azure.microsoft.com/en-us/services/cognitive-services/speaker-recognition/
2. 接著到以下網站查看 API 文件
這裡我們先使用 Identification API 辨識功能。
每個 Profile 代表一個人,每個 Profile 可存入多個聲音。
https://westus.dev.cognitive.microsoft.com/docs/services/563309b6778daf02acc0a508/operations/5645c068e597ed22ec38f42e
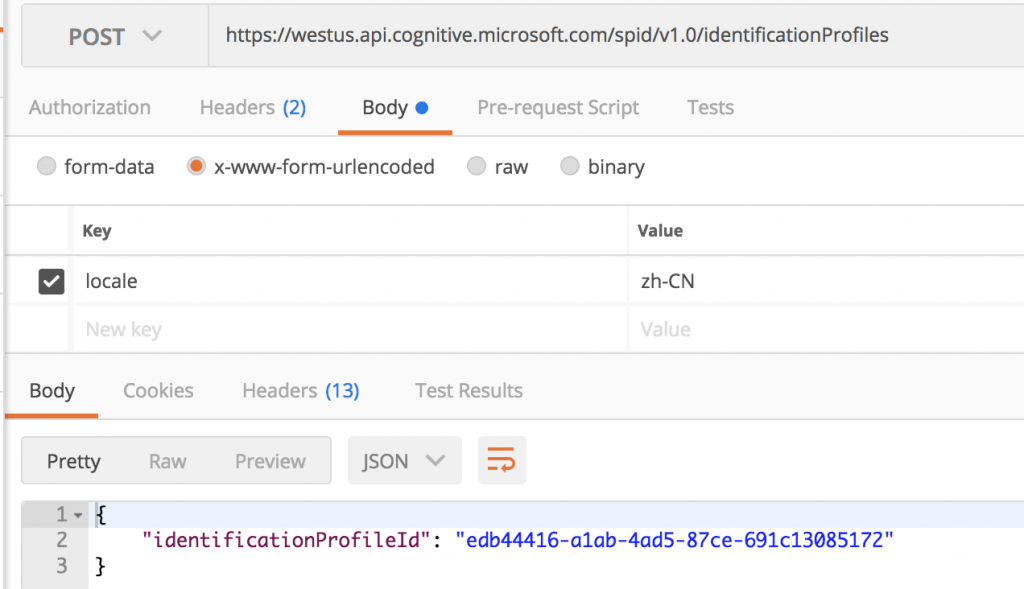
創建後可以看到回傳一個
identificationProfileId
上傳聲音檔案到 Profile 中。
https://westus.dev.cognitive.microsoft.com/docs/services/563309b6778daf02acc0a508/operations/5645c3271984551c84ec6797
音訊檔案記得要符合以下格式。
Container WAV
Encoding PCM
Rate 16K
Sample_Format 16 bit
Channels Mono
可以使用此網站轉換:https://audio.online-convert.com/convert-to-wav
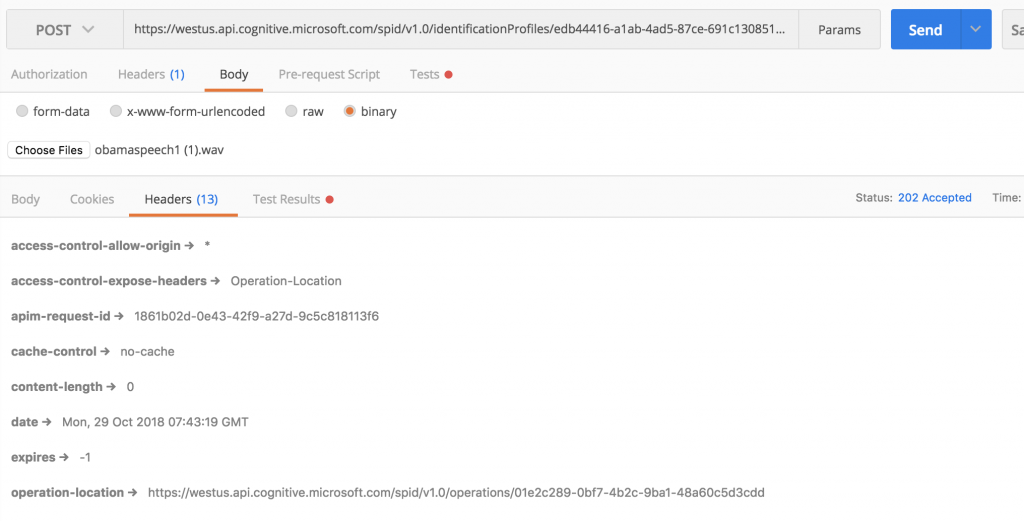
可以看到回傳的 Header 部分的 operation-location 欄位有一個 URL,我們可從此 URL 查看音訊處理狀態,每個 Profile 最多只能加入 1000 個聲音。
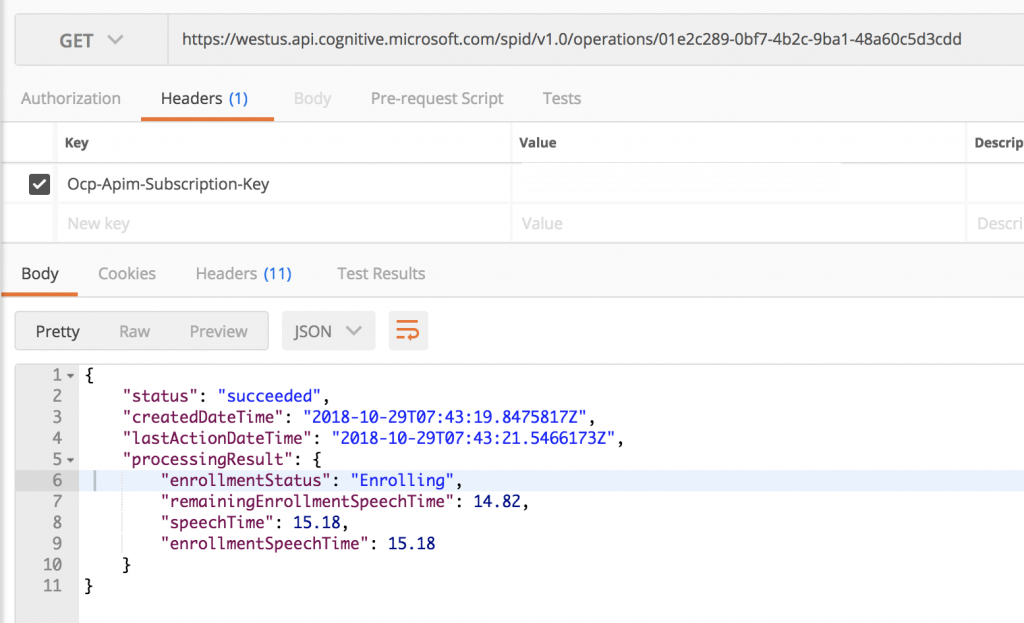
發送一個 GET 請求並附上金鑰。
上傳好許多不同的聲音檔案後,我們就可以開始測試我們的聲音集,其中 identificationProfileIds 的參數最多可以填上 10 組 ProfileID,每個 ProfileID 內包含許多剛才上傳的樣本聲音。
之後如下圖發送我們要辨識的聲音檔案,發送後等待幾秒鐘處理,即可看到回傳的參數一樣有 operation-location URL。
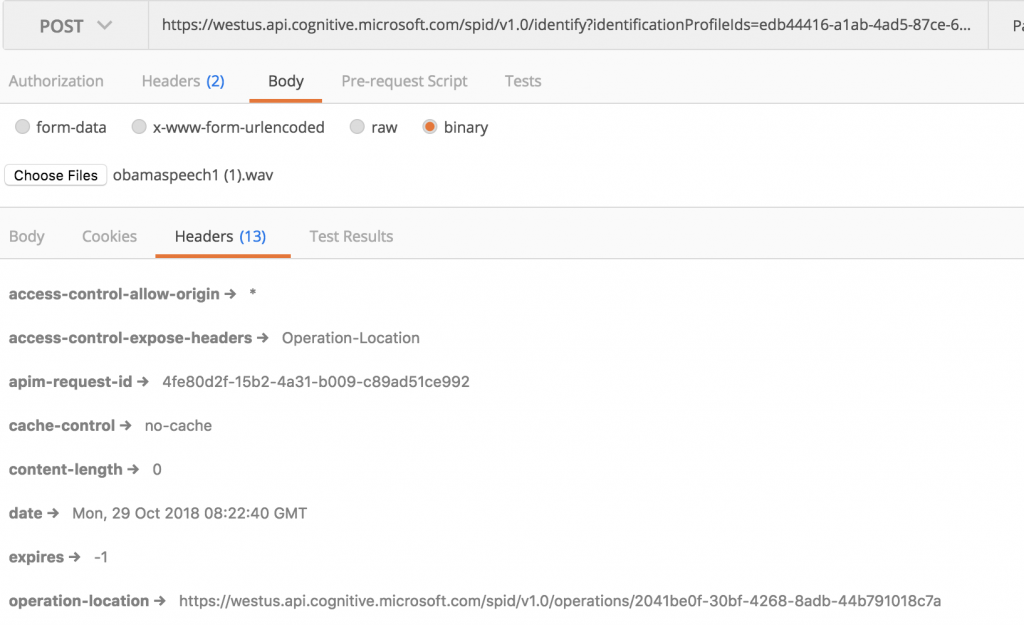
operation-location URL 發送請求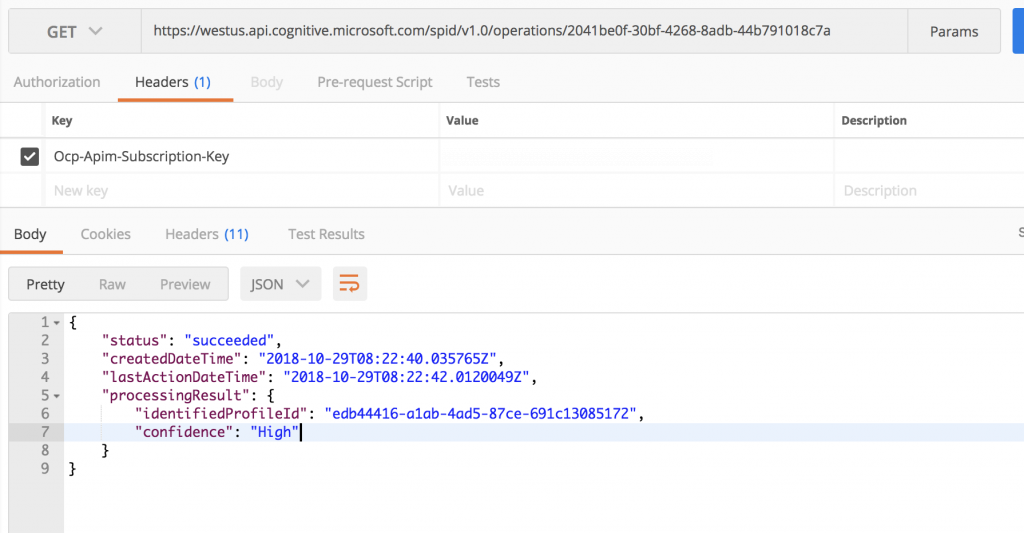
即可得到從第四步驟所傳入的 identificationProfileIds 中得到最符合此聲音的 Profile GUID。
最後從此 Profile GUID 與自己所建立的人物名稱表對應,即可得到聲音是誰所產生。

 iThome鐵人賽
iThome鐵人賽