第八天了~~~ 就持續下去吧~~
昨天講了一下機器學習的大概,今天來講講Regression and Classification吧
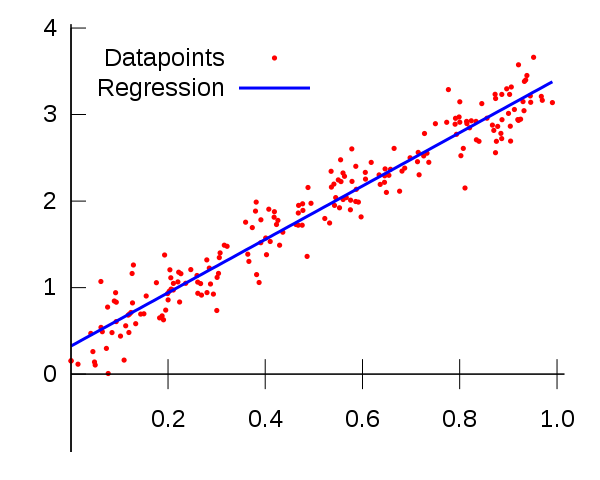
Regression代表的是"回歸",你猜的沒有錯,就是標準曲線然後有個相關係數的那個
這就是最簡單的機器學習了(至少你學會一樣)
簡單的來說就是你將數字帶入這個回歸線的方程式內,方程式會給你一個"預測"答案
(機器學習都是預測,沒有一定)
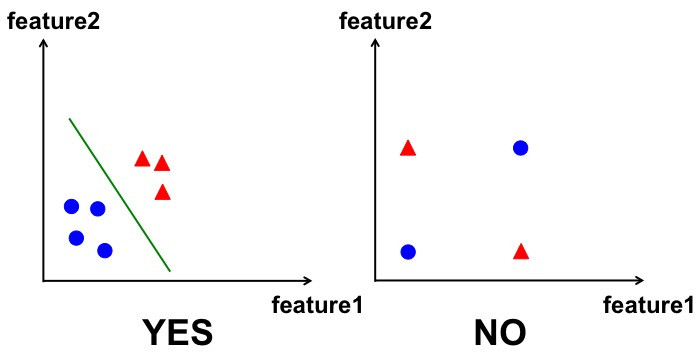
Classification顧名思義就是分類,甚麼意思?
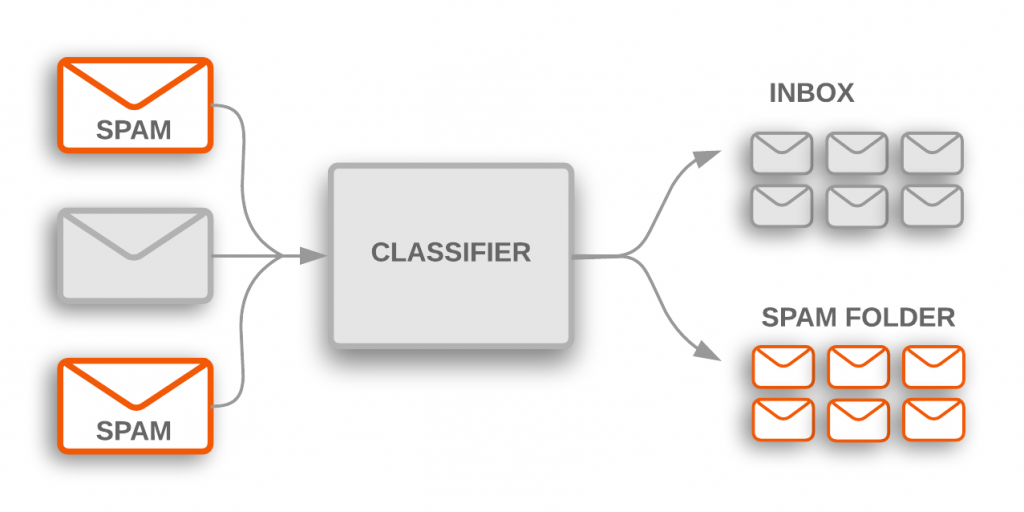
假如我有垃圾信件(spam)和還有正常的信件,那我可以藉由機器學習的方式來進行區分出來,哪些下去,哪些不要下去這樣,但這邊幾乎就是二分法,此外也依賴的歷史數據(例如:訂閱特價多少...這類的),所以屬於監督式學習。
另外說道二分法就不得不提Perceptron感知器還有神經網絡了。這些是甚麼東西?
先來說說神經網絡
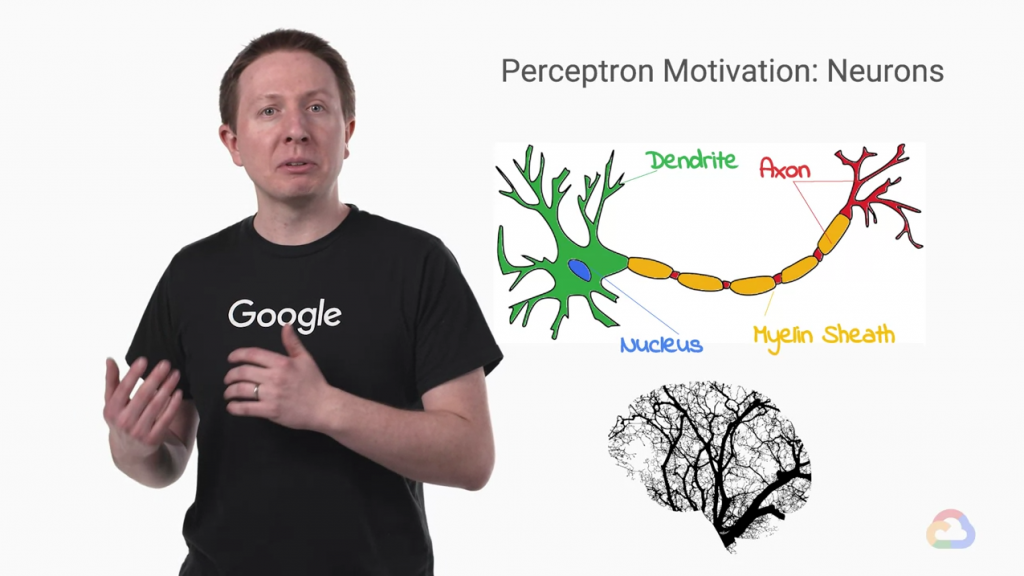
小時候適不是有學過神經衝動之類的,神經元呀...等
就是要超過有一定的值,我們稱為threshold,超過這個神經才會有反應
那我們來用數學模擬這個
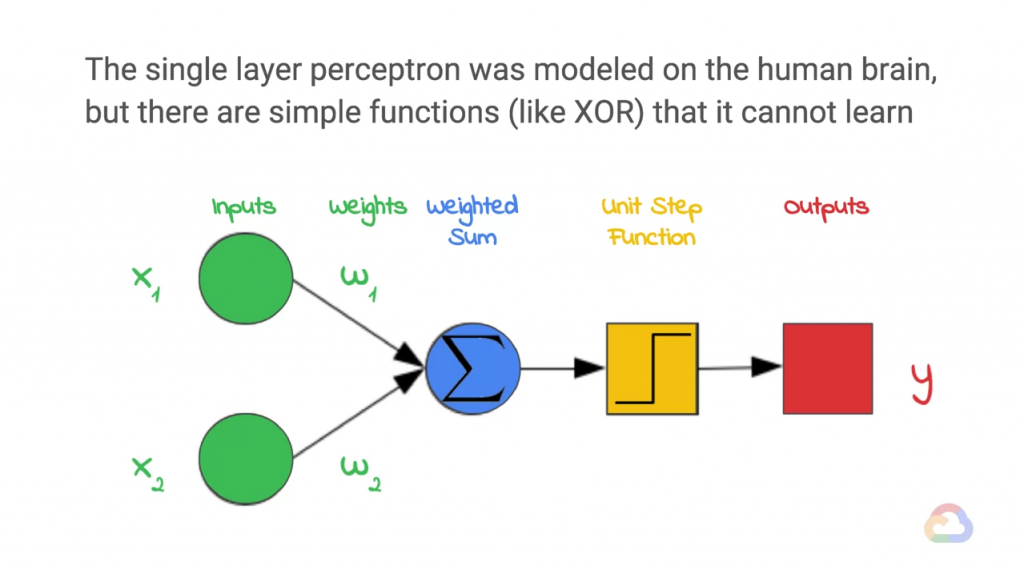
這個w代表是參數,為何要增加參數,痾...簡單的來說就是為了更精確地去分辨
參數越高,代表這個特徵越重要。(例如美麗跟眼睛大有很大的關係,但有沒有我不知道)
接著將所有特徵都放入後產生的值若大於一定的話,就會發生反映這樣
再來提提Perceptron
Perceptron就是機器會依照不同的權重去調整參數,以便完美的分開值(分類)
簡單來說這是一種分類的方式。
今天先這樣。
參考資料:
https://developers.google.com/machine-learning/guides/text-classification/
google cousera課程
http://qingkaikong.blogspot.com/2016/11/machine-learning-5-artificial-neural.html


 iThome鐵人賽
iThome鐵人賽